

3.Формальні породжувальні граматики.Типи граматик.
Ієрархія Хомскі. Дерево виводу.
Формальною породжувальною граматикою називається четвірка виду G = (N, T, S, P), де N – скiнченна непорожня множина, елементи якої будемо називати нетермiнальними символами, T – скінченна непорожня множина, елементи якої будемо називати термiнальними символами, S ∈ N – початковий нетермiнальний символ, P – скiнченна множина продукцiй (правил перетворення) вигляду ξ → η, де ξ та η – слова в алфавiтi
N ∪ T. Букви термiнального алфавiту позначатимемо малими латинськими буквами чи цифрами, а нетермiнального алфавiту – великими латинськими буквами. Слова в алфавiтi N ∪T, як завжди, будемо позначати малими грецькими буквами. Нагадаємо, що множину всiх слiв в алфавiтi A позначають через .
Нехай
G
= (N,
T,
S,
P)
– граматика, i
нехай
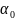 = σ
ξ
τ
(тобто
– конкатенацiя
слiв
σ,
ξ
i
τ
),
= σ
ξ
τ
(тобто
– конкатенацiя
слiв
σ,
ξ
i
τ
),
 = σ
η
τ
– слова в алфавiтi
N
∪
T.
Якщо ξ
→ η
– продукцiя
граматики G,
то говорять, що
безпосередньо виводиться з
,
i
записують
⇒
.
Якщо
,
,
. . . ,
= σ
η
τ
– слова в алфавiтi
N
∪
T.
Якщо ξ
→ η
– продукцiя
граматики G,
то говорять, що
безпосередньо виводиться з
,
i
записують
⇒
.
Якщо
,
,
. . . ,
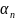 – слова в алфавiтi
N
∪
T
такi,
що
⇒
⇒
– слова в алфавiтi
N
∪
T
такi,
що
⇒
⇒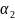 ⇒
.
. . ⇒
⇒
.
. . ⇒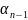 ⇒
,
то говорять, що
виводиться з
i
записують
⇒
,
то говорять, що
виводиться з
i
записують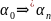 .
.
Мовою, що породжується граматикою G = (N, T, S, P), називають множину всiх слiв термiналiв, якi виводяться з початкового символу S. Її позначають L(G). Таким чином, L(G) = {ω ∈ T∗| S ⇒∗ω}.
Якщо ми маємо багато правил граматики з однаковими лівимичастинами
A
→
,A
→
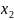 ,
. . .A
→
,
то ми можемо об’єднати їх в одне правило
наступного вигляду A
→
|
| . . . |
.
,
. . .A
→
,
то ми можемо об’єднати їх в одне правило
наступного вигляду A
→
|
| . . . |
.
Граматики класифiкують за типами продукцiй. Розглянемо класифiкацiю, яку запропонував американський математик i лiнгвiст Н.Хомскi. Принцип цiєї класифiкацiї полягає в тому, що на продукції накладено певнi обмеження. Вiн подiлив граматики на чотири типи.
У
граматицi
типу
0
немає жодних обмежень на продукцiї.
Граматика типу
1
може мати продукцiї
лише у виглядi
ξ
→ η,
де довжина слова η
не менша, нiж
довжина слова ξ,
або у виглядi
ξ
→ e.
У граматицi
типу
2
можуть бути лише продукцiї
A
→ ω,
де A
– нетермiнальний
символ, ω
∈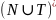 .
Граматика типу
3
може мати такi
продукцiї:
.
Граматика типу
3
може мати такi
продукцiї:
A → ωB, A → ω i A → e, де A, B – нетермiнали, ω – слово з термiналiв. Iз цих означень випливає, що кожна граматика типу n, деn = 1, 2, 3, є граматикою типу n−1. Граматики типу 2 називають контекстно вiльними, бо нетермiнал A в лiвiй частинi продукції
A → η можна замiнити словом η в довiльному оточеннi щоразу, коли він зустрiчається, тобто незалежно вiд контексту.
Мову, яку породжуєграматика типу 2, називають контекстно вiльною. Якщо в множинi продукцiй P є продукцiя виду γ µ δ → γ ν δ, |µ| ≤ |η|, то граматику називають граматикою типу 1, або контекстно залежною, оскiльки µ можна замiнити на ν лише в оточеннi слiв γ . . . δ, тобто у вiдповiдному контекстi. Мову, яку породжує граматика типу 1, називаютьконтекстно залежною. Граматику типу 3 називають праволiнiйною.
Двоїсто визначають лiволiнiйну граматику – вона може мати такi продукцiї:
A → ωB, A → ω i A → e, де A, B – нетермiнали, ω – словоз термiналiв. Лiволiнiйнi i праволiнiйнi граматики називаються регулярними. Регулярнi граматики породжують регулярнi мови i тількиїх.
Слово
ω
належить мовi
L(G)
контекстно вiльної
граматики G
тодi
i
лише тодi,
коли iснує
виведення S
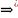 ω
в G.
Таке виведення показує як крок за
крококом застосовуються продукцiї
граматики, щоб одержати слово ω
з початкового нетермiнального
символу S.
ω
в G.
Таке виведення показує як крок за
крококом застосовуються продукцiї
граматики, щоб одержати слово ω
з початкового нетермiнального
символу S.
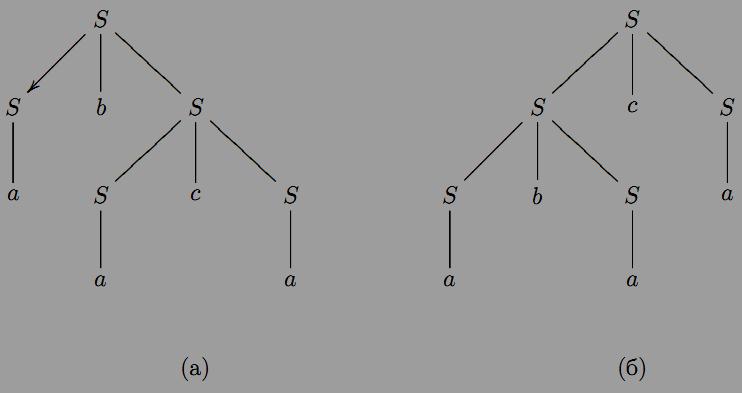
Це виведення можна також продемонструвати наочно з допомогоюдерева, яке називатемемо деревом виведення. Наприклад, розглянемо контекстно вiльну граматику G = ({S}, {a, b, c}, S, P), де P = {S →SbS | ScS | a} i слово abaca ∈ L(G). Виведення
S ⇒ SbS ⇒ SbScS ⇒ abScS ⇒ abSca ⇒ abaca показано на рисунку (а), а виведення
S ⇒ ScS ⇒ SbScS ⇒ abScS ⇒ abSca ⇒ abaca зображено деревом на рисунку (б).
В загальному випадку для контекстно вiльної граматики G =(N, T, S, P) дерево виведення будується наступним чином:
1) Вершиною дерева є початковий нетермiнальний символ S.
2)
Повторюємо наступнi
кроки доти, доки кожен листок дерева
буде або порожнiм
символом e
або термiнальним
символом: длякожного листка A
∈
N
дерева обираємо продукцiю
A
→
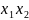 . . .
. . .
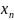 граматики G,
де
граматики G,
де
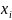 ∈
N
∪
T
i
замiнюємо
вершину A
∈
N
наступним деревом:
∈
N
∪
T
i
замiнюємо
вершину A
∈
N
наступним деревом:
Я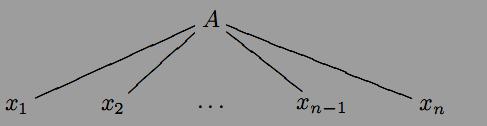 кщо
конкатенацiя
листкiв
дерева виведення є словом ω
∈
кщо
конкатенацiя
листкiв
дерева виведення є словом ω
∈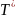 ,то
кажемо, що дане дерево є деревом виведення
для слова ω.
,то
кажемо, що дане дерево є деревом виведення
для слова ω.
Дерево виведення слова ω вiдповiдає виведенню ω в граматицi G. Легко бачити, що часто дерево виведення вiдповiдає бiльш нiж одному виведенню слова ω. Контекстно вiльна граматика G = (N, T, S, P) називається не-однозначною, якщо iснує слово ω ∈ L(G), яке має два або бiльшерiзних дерев виведень.Розглянемо граматику G з правилами S → if b then S else S | if b then S | a.
Ця граматика неоднозначна, оскiльки слово
if b then if b then a else a
має два виводи
if b then (if b then a) else a та
if b then (if b then a else a),
яким вiдповiдають два рiзних дерева виведення.