

Кодування фільмів
Фільм є послідовністю кадрів, які швидко змінюють один одного і на яких зображені послідовні фази руху. Оскільки відомі принципи кодування окремих кадрів, то закодувати фільм як послідовність таких кадрів просто. Звук записують незалежно від зображення. При демонстрації фільму важливо тільки добитися синхронізації звуку і зображення (у кіно для цього використовують хлопавку - по клацанню хлопавки поєднуються звук і зображення).
Закодований фільм несе в собі інформацію про розмір кадру в пікселях і кількість використовуваних кольорів; частоту і розрізнювання для звуку; способі запису звуку (покадровий або безперервний для всього фільму). Після цього слідує послідовність закодованих картинок і звукових фрагментів.
5.3Стиснення даних як технологія вторинного кодування. Алгоритм Хаффмена
Передача і зберігання інформації вимагають достатньо великих витрат. На жаль, велика частина даних, які потрібно передавати по каналах зв'язку і зберігати, має не найкомпактніше представлення. Швидше, ці дані зберігаються у формі, що забезпечує їх найбільш просте використання, наприклад: звичайні книжкові тексти, ASCII коди та коди Windows - 1251 текстових редакторів, двійкові коди даних ЕОМ, окремі відліки сигналів в системах збору даних і т.д. Проте таке найбільш просте у використанні представлення даних вимагає удвічі - втричі, а іноді і в сотні разів більше місця для їх збереження і смуги частот для їх передачі, ніж насправді потрібно. Тому стиснення даних, як одна із форм кодування, – це один з найбільш актуальних напрямків сучасної теорії інформації.
Кодування джерела повідомлень (стиснення, компресія) проводиться з метою забезпечення компактного представлення даних, скорочення об'єму інформації, що виробляється джерелом, та з метою підвищення швидкості передачі інформаційних повідомлень по каналах зв'язку.
Зворотною операцією при цьому є декомпресія - спосіб відновлення стислих даних в початкові.
Існують два типи систем стиснення даних як без втрати якості (коли передавана/зберігається інформація в стислому вигляді після декомпресії абсолютно ідентична початковою), так і з втратою якості (коли дані після декомпресії відрізняються від оригінальних).
Виділяються такі основні види упаковки:
- десяткова упаковка призначена для упаковки символьних даних, що складаються тільки з чисел. Замість використовуваних 8 біт під символ можна цілком раціонально використовувати всього лише 4 біти для десяткових і шістнадцатеричних цифр, 3 біти для восьмеричних і т.д. При подібному підході вже відчувається стиснення мінімум 1:2.
- статистичне кодування засноване на тому, що не всі елементи даних зустрічаються з однаковою частотою (або вірогідністю). При такому підході коди вибираються так, щоб елементу, що найчастіше зустрічається, відповідав код з якнайменшою довжиною, а якнайменше частому - з найбільшою. Окрім цього, коди підбираються так, щоб при декодуванні можна було однозначно визначити елемент початкових даних. При такому підході можливе тільки біт-орієнтоване кодування, при якому виділяються дозволені і заборонені коди. Якщо при декодуванні бітової послідовності код виявився забороненим, то до нього необхідно додати ще один біт початкової послідовності і повторити операцію декодування. Найпоширенішими прикладами такого кодування є алгоритми Шеннона і Хаффмена, останній з яких ми і розглядатимемо.
Алгоритм Хаффмена є деревоподібним кодом, заснованим на статистичному кодуванні.
Деревоподібним кодом називають код, кодові слова якого містить тільки ті, що відповідають кінцевим вершинам кодового дерева.
Вузли дерева розміщуються на ярусах. На початковому (нульовому) ярусі розташований один вузол, який називається коренем дерева. Вузли наступних ярусів пов'язані з вузлами попередніх ярусів ребрами. У випадку двійкового коду з кожного вузла виходить не більше двох ребер. Ребрам приписані кодові символи. У даному прикладі прийнято, що ребру, що веде нагору, приписується символ 0, а ребру, що веде вниз - символ 1. Таким чином, кожній вершині дерева відповідає послідовність, що зчитується уздовж шляху, що зв'язує даний вузол з коренем дерева.
Кінцевим вузлом називається вузол, якщо з нього не виходить жодного ребра.
Розберемося детальніше в реалізації коду Хаффмена.
Хай
є джерело даних, яке передає символи
![]() з
різним ступенем вірогідності, тобто
кожному
з
різним ступенем вірогідності, тобто
кожному
![]() відповідає
своя вірогідність (або частота)
відповідає
своя вірогідність (або частота)
![]() ,
при чому існує хоча б одна пара
і
,
при чому існує хоча б одна пара
і
![]() ,
,![]() ,
такі, що
і
,
такі, що
і
![]() не
рівні. Таким чином утворюється набір
частот
не
рівні. Таким чином утворюється набір
частот
![]() ,
при чому
,
при чому
![]() ,
оскільки передавач не передає більше
ніяких символів окрім як
.
,
оскільки передавач не передає більше
ніяких символів окрім як
.
Наша
задача - підібрати такі кодові символи
![]() з
довжинами
з
довжинами
![]() ,
щоб середня довжина кодового символу
не перевищувала середньої довжини
початкового символу. При цьому потрібно
враховувати умову, що якщо
,
щоб середня довжина кодового символу
не перевищувала середньої довжини
початкового символу. При цьому потрібно
враховувати умову, що якщо
![]() і
,
то
і
,
то
![]() .
.
Хаффмен запропонував будувати дерево, в якому вузли з найбільшою вірогідністю якнайменше віддалені від коріння. Звідси і витікає сам спосіб побудови дерева:
1.Вибрати два символи і , , такі, що і зі всього списку є мінімальними.
2.Звести
гілки дерева від цих двох елементів в
одну точку з вірогідністю
![]() ,
помітивши одну гілку нулем, а іншу -
одиницею (за власним розсудом).
,
помітивши одну гілку нулем, а іншу -
одиницею (за власним розсудом).
3.Повторити пункт 1 з урахуванням нової точки замість і , якщо кількість точок, що вийшли, більше одиниці. Інакше ми досягли коріння дерева.
Тепер спробуємо скористатися одержаною теорією і закодувати інформацію, передану джерелом, на прикладі семи символів.
Розберемо
детально перший цикл. На малюнку зображена
таблиця, в якій кожному символу
відповідає
своя вірогідність (частота)
.
Згідно пункту 1 ми вибираємо два символи
з таблиці з якнайменшою вірогідністю.
У нашому випадку це
![]() і
і
![]() .
Згідно пункту 2 зводимо гілки дерева
від
і
у
одну точку і позначаємо гілку, що веде
до
,
одиницею, а гілку, що веде до
,-
нулем. Над новою точкою приписуємо її
вірогідність (в даному випадку - 0.03).
Надалі дії повторюються вже з урахуванням
нової точки і без урахування
і
.
.
Згідно пункту 2 зводимо гілки дерева
від
і
у
одну точку і позначаємо гілку, що веде
до
,
одиницею, а гілку, що веде до
,-
нулем. Над новою точкою приписуємо її
вірогідність (в даному випадку - 0.03).
Надалі дії повторюються вже з урахуванням
нової точки і без урахування
і
.
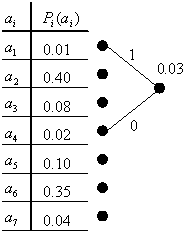
Після багатократного повторення висловлених дій будується наступне дерево:
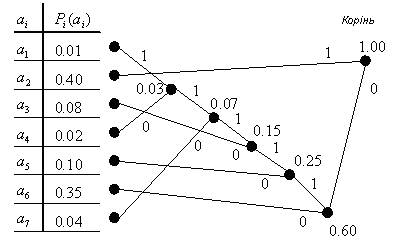
По побудованому дереву можна визначити значення кодів , здійснюючи спуск від коріння до відповідного елементу , при цьому приписуючи до одержуваної послідовності при проходженні кожної гілки нуль або одиницю (залежно від того, як іменується конкретна гілка). Таким чином таблиця кодів виглядає таким чином:
|
|
|
|
1 |
011111 |
0,01 |
6 |
2 |
1 |
0,40 |
1 |
3 |
0110 |
0,08 |
4 |
4 |
011110 |
0,02 |
6 |
5 |
010 |
0,10 |
3 |
6 |
00 |
0,35 |
2 |
7 |
01110 |
0,04 |
5 |
Тепер спробуємо закодувати послідовність з символів.
Хай
символу
 відповідає (як приклад) число і. Хай є
послідовність 12672262. Потрібно одержати
результуючий двійковий код.
відповідає (як приклад) число і. Хай є
послідовність 12672262. Потрібно одержати
результуючий двійковий код.
Для
кодування можна використовувати таблицю
кодових символів
 із врахуванням, що
відповідає
символу
.
У такому разі код для цифри 1 буде
послідовністю 011111, для цифри 2 - 1, для
цифри 6 – 00, а для цифри 7 – 01110. Таким
чином, одержуємо наступний результат:
із врахуванням, що
відповідає
символу
.
У такому разі код для цифри 1 буде
послідовністю 011111, для цифри 2 - 1, для
цифри 6 – 00, а для цифри 7 – 01110. Таким
чином, одержуємо наступний результат:
Дані |
12672262 |
Довжина коду |
Початкові |
001 010 110 111 010 010 110 010 |
24 біт |
Кодовані |
011111 1 00 01110 1 1 00 1 |
19 біт |
В результаті кодування ми виграли 5 біт і записали послідовність 19 бітами замість 24.
Проте це не дає повної оцінки стиснення даних. Повернемося до математики і оцінимо ступінь стиснення коду. Для цього знадобиться ентропійная оцінка.
Ентропію для нашого випадку можна представити у вигляді:
![]() .
.
Ентропія
має чудову властивість: вона дорівнює
мінімальній допустимій середній довжині
кодового символу
![]() у
бітах. Сама ж середня довжина кодового
символу обчислюється по формулі
у
бітах. Сама ж середня довжина кодового
символу обчислюється по формулі
![]() .
.
Підставляючи
значення у формули
![]() і
і
![]() ,
одержуємо наступний результат:
,
одержуємо наступний результат:
![]() ,
,
![]() .
.
Величини і дуже близькі, що говорить про реальний виграш у виборі алгоритму. Тепер порівняємо середню довжину початкового символу і середню довжину кодового символу через відношення:
![]() .
.
Таким чином, ми одержали стиснення в співвідношенні 1:1,429, що дуже непогане.
І наприкінці, вирішимо останню задачу: дешифровка послідовності бітів.
Хай для нашої ситуації є послідовність бітів:
001101100001110001000111111
Необхідно визначити початковий код, тобто декодувати цю послідовність.
Звичайно, в такій ситуації можна скористатися таблицею кодів, але це достатньо незручно, оскільки довжина кодових символів непостійна. Набагато зручніше здійснити спуск по дереву (починаючи з коріння) за наступним правилом:
1.Початкова точка - корінь дерева.
2.Прочитати новий біт. Якщо він нуль, то пройти по гілці, поміченій нулем, інакше - одиницею.
3.Якщо точка, в яку ми потрапили, кінцева, то ми визначили кодовий символ, який слідує записати і повернутися до пункту 1. Інакше слід повторити пункт 2.
Розглянемо
приклад декодування першого символу.
Ми знаходимося в точці з вірогідністю
1.00 (коріння дерева), прочитуємо перший
біт послідовності і відправляємося по
гілці, поміченій нулем, в точку з
вірогідністю 0.60. Оскільки ця точка не
є кінцевою в дереві, то прочитуємо
наступний біт, який теж рівний нулю, і
відправляємося по гілці, поміченій
нулем, в точку
![]() ,
яка є кінцевою. Ми дешифрували символ
- це число 6. Записуємо його і повертаємося
в початковий стан (переміщаємося в
коріння).
,
яка є кінцевою. Ми дешифрували символ
- це число 6. Записуємо його і повертаємося
в початковий стан (переміщаємося в
коріння).
Таким чином декодована послідовність приймає вигляд.
Дані |
001101100001110001000111111 |
Довжина коду |
Кодовані |
00 1 1 0110 00 01110 00 1 00 011111 1 |
27 біт |
Початкові |
6 2 2 3 6 7 6 2 6 1 2 |
33 біт |
В даному випадку виграш склав 6 біт при достатньо невеликій довжині послідовності.
Висновок напрошується сам собою: алгоритм простий. Проте слід зробити зауваження: даний алгоритм хороший для стиснення текстової інформації (дійсно, реально ми використовуємо при набиванні тексту приблизно 60 символів з доступних 256, тобто вірогідність зустріти інші символи близька до нуля), але достатньо поганий для стиснення програм (оскільки в програмі всі символи практично рівноімовірні). Отже ефективність алгоритму дуже сильно залежить від типу даних, що стискаються.
Розглянемо ще один приклад реалізації стиснення такого алгоритму. Хай повідомлення є текстом, який складається із дванадцяти символів із ймовірностями, які визначені і відображені в таблиці 1.
Таблиця 1
Символ |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
Імовірність |
0,01 |
0,01 |
0,01 |
0,01 |
0,02 |
0,02 |
0,02 |
0,1 |
0,1 |
0,1 |
0,2 |
0,4 |
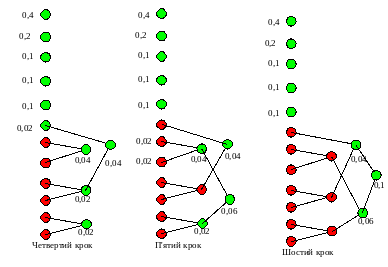
Надалі будується “дерево” коду згідно із алгоритмом Хаффмена. Як відомо, на кожному кроці алгоритму здійснюється аналіз ймовірностей усіх символів (які на цьому кроці позначені зеленими колами), починаючи із пари символів, які мають найменші імовірності. Вразі наявності декількох символів із однаковою імовірністю, вибір пари здійснюється довільно. Нехай на першому кроці, в наслідок аналізу чотирьох найменших та однакових ймовірностей, вибрано перший та другий символи. Ці символи утворюють новий вузол (узагальнений символ), імовірність появи якого дорівнює сумі ймовірностей тих символів, які його утворили (0,01+ 0,01 = 0,02). Ребрам, які поєднують ці вузли привласнюють значення “1” чи “0” (довільно, за бажанням виконавця). Звернемо увагу, що на рисунках, які демонструють алгоритм, значення ребер привласнено (для спрощення рисунків!) лише на перших двох кроках алгоритму. Після цього розглянуті вузли (на першому кроці – перший та другий) із розгляду виключаються, що на рисунках показано виділенням таких вузлів червоним кольором.
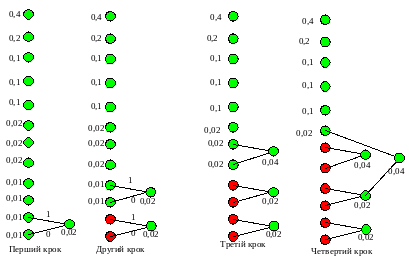
Перший – четвертий кроки алгоритму
На наступному кроці відбувається такий же аналіз ймовірностей, і, в наслідок аналізу двох найменших та однакових ймовірностей (третьої та четвертої), визначається наступний новий вузол (узагальнений символ) із відповідною ймовірністю (0,01+ 0,01 = 0,02).
На третьому кроці відбувається аналіз чотирьох вузлів із найменшими ймовірностями (по 0,02) і визначається наступний новий вузол (узагальнений символ) із відповідною ймовірністю (0,02+ 0,02 = 0,4).
Цей процес продовжується до повного перебору усіх вузлів, в наслідок чого утвориться корінь дерева із імовірністю, яка дорівнює 1 (одиниці).
Четвертий –шостий кроки алгоритму
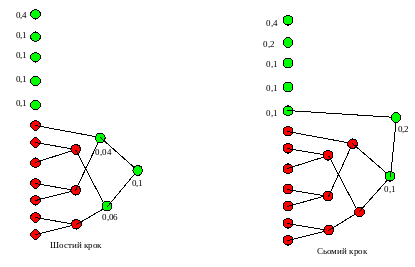
Шостий –сьомий кроки алгоритму
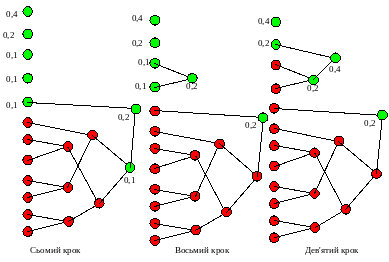
Сьомий – дев’ятий кроки алгоритму
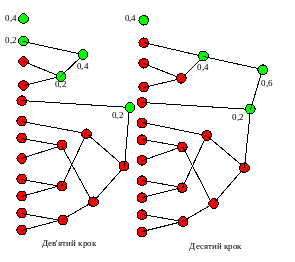
Дев’ятий – десятий кроки алгоритму
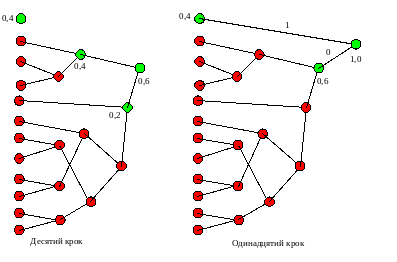
Десятий – одинадцятий кроки алгоритму
Здійснивши тепер перехід по ребрам із кореня дерева до того вузла, яким позначено кожен із символів, і, послідовно записавши коди відповідних ребер, отримаємо коди кожного із символів.
Із рисунків видно, що коди перших шести символів будуть шестирозрядними, розрядність решти символів буде зменшуватися, аж до одного розряду для символу із найбільшою імовірністю.