

5.4. Операции с поиском по неключевым полям
Записи в базе данных связаны в целое по ключевым полям. Если планируется частое выполнение запросов по неключевым атрибутам, то лучшее решение проблемы - введение “вторичных индексов”.
Файл со вторичным индексом связывает значения из домена неключевого атрибута либо напрямую с записями, либо косвенно через значение ключа. Очевидно, что связь через ключ записи требует дополнительного обращения за соответствующей записью, однако этот вариант может быть выгоднее по объему памяти, если значение ключа занимает меньше места, чем указатель на запись.
Пример структуры со вторичным индексом приведен на рис. 5.2.




 z1
z2
- индекс индекса
z1
z2
- индекс индекса


 z2
- вторичный индекс
z2
- вторичный индекс



 3
p3
p4
p5
3
p3
p4
p5




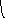 z1
z12
- вторичный индекс
z1
z12
- вторичный индекс



 1
p1
1 p2
1
p1
1 p2
Рис. 5.2.
z1, z2,... - значения неключевых атрибутов;
цифры - количество указателей p.
5.5. Операции по частичному соответствию
Иногда возникают запросы по двум и более атрибутам, не образующим ключ. Поиск записей с заданными значениями нескольких полей называют поиском по частичному соответствию.
Задача поиска по частичному соответствию может быть решена с помощью вторичных индексов по заданным атрибутам. Между найденными с помощью вторичных индексов указателями (или значениями ключа) выполняют операцию пересечения. Если указатели адресуют блок записей, то, конечно, следует дополнительно проанализировать все записи в найденном блоке.
Поиск по частичному соответствию достаточно экономично реализуется в хешированном файле при подборе хеш-функции по методу раздельного хеширования. В методе раздельного хеширования хеш-функция H(N1, N2, ... , Nk) вычисляется по значениям атрибутов N1, N2, ... , Nk, которые планируются в запросах. Кроме того, хеш-функция H(N1, N2, ... , Nk) строится как произведение частичных хеш-функций Hi(Nj):
H(N1, N2, ... , Nk) = H1(N1) * H2(N2) * ... * Hk(Nk) .
Число значений хеш-функции и соответственно число цепочек записей равно
M = M1 * M2 * ... *Mk.
При поиске по частичному соответствию значения некоторых атрибутов будут заданы и поэтому по каждому j-ому из этих атрибутов необходимое число просматриваемых цепочек будет уменьшаться в Mj раз.
Лекция 6. Язык запросов SQL
Запросы к базе данных формулируются на специальном языке. Среди многочисленных языков запросов в настоящее время выдвинулся вперед язык SQL. Это сокращение образовано от слов “Structed Query Language”; в документации рекомендуется произносить его как “сэквэл”.
Независимость от специфики компьютера и поддержка его ведущими фирмами, сделало SQL, и вероятно в течение обозримого будущего оставит его, основным стандартным языком. По этой причине любой, кто хочет работать с базами данных 90-х годов, должен знать SQL.
Стандарт SQL определяется ANSI (Американским Национальным Институтом Стандартов) и в данное время также принимается ISO (международной организацией по стандартизации). Язык SQL предложен фирмой IBM. Но другие компании подхватили SQL сразу же, а компания Oracle отбила у IBM право на рыночную продажу SQL продуктов.
Однако, большинство коммерческих программ баз данных расширяют SQL без уведомления ANSI, добавляя разные особенности в этот язык, которые, как они считают, будут весьма полезны.
В результате стандартизации возникли проблемы из-за введенных ограничений, так как не всегда ANSI определяет то, что является наиболее полезным; программы пытаются соответствовать стандарту ANSI не позволяя ему ограничивать их слишком сильно.
6.1. Структура языка SQL
Язык SQL ориентирован на реляционные базы данных. Если использовать универсальный язык программирования, например C, то чтобы сформировать реляционную базу данных необходимо было бы начать с самого начала. Потребовалось бы определить объект, называемый таблицей, которая могла бы расти так, чтобы иметь любое число строк, а затем создавать постепенно процедуры для помещения значений в нее и извлечения из них. Для поиска некоторых определенных строк необходимо было бы выполнить по шагам процедуру, подобную следующей:
1. Взять строку таблицы.
2. Выполнить проверку, является ли эта строка одной из строк которая нужна.
3. Если это так, сохранить ее где-нибудь, пока вся таблица не будет проверена.
4. Проверить, имеются ли другие строки в таблице.
5. Если имеются, возвратиться на шаг 1.
6. Если строк больше нет, вывести все значения, сохраненные в шаге 3.
В СУБД, использующей SQL, все это уже реализовано.
Имеются два SQL:
- интерактивный;
- вложенный.
Интерактивный SQL используется для обращения непосредственно к базе данных. В этой форме SQL команда немедленно выполняется.
Вложенный SQL используется внутри программ, которые обычно написаны на некотором другом языке (типа КОБОЛА или Си). Это делает эти программы более мощными и эффективным. Однако, встроенный SQL требует некоторых расширений к интерактивному SQL. Вложенный
SQL - библиотека функций, которым передаются переменные или параметры программы.
Интерактивный SQL - это форма наиболее полезная непрограммистам.
И в интерактивной и во вложенной формах SQL, имеются многочисленные части, или субподразделения. К сожалению, эти термины не используются повсеместно во всех реализациях. Они подчеркиваются в SQL ANSI и полезны на концептуальном уровне, но большинство SQL программ практически не обрабатывают их отдельно, так что они по существу становятся функциональными категориями команд SQL.
Субчасти языка SQL:
- DDL ( Язык Определения Данных ), или Язык Описания Схемы в SQL ANSI, состоит из команд, которые создают объекты ( таблицы, индексы, отчеты и т.п. ) в базе данных;
- DML (Язык Манипулирования Данными) - это набор команд, которые необходимы для определения того, какие значения представлены в таблицах в данный момент;
- DCD (Язык Управления Данными) состоит из средств, которые определяют, разрешить ли пользователю выполнять определенные действия или нет.
Это не различные языки, а виды команд SQL, сгруппированные по их функциям.
Не все типы значений, которые могут занимать поля таблицы, логически одинаковые. Наиболее очевидное различие - между числами и текстом. Вы не можете помещать числа в алфавитном порядке или вычитать одно имя из другого.
В SQL-записях каждому полю назначается тип данных, который укаазывает на тип значения, которое это поле может содержать.
Все значения в данном поле должны иметь одинаковый тип. Это ограничение полезно тем, что оно налагает некоторую структурность на данные. Часто сравниваются некоторые или все значения в данном поле, поэтому действие можно выполнять только на определенных строках, а не на всех. Этого нельзя было бы сделать, если бы значения полей имели смешанный тип данных.
К сожалению, определение этих типов данных является основной областью, в которой большинство коммерческих программ баз данных и официальный стандарт SQL не всегда совпадают. ANSI SQL стандарт распознает только текст и тип числа, в то время как большинство коммерческих программ используют другие специальные типы, например, такие как DATE (ДАТА) и TIME (ВРЕМЯ), фактически почти стандартные типы ( хотя точный формат их меняется ). Некоторые пакеты также поддерживают такие типы, как MONEY (ДЕНЬГИ) и BINARY (ДВОИЧНЫЕ).