§4.3. Основные виды нелинейной регрессии
Параболическая и полиномиальная регрессии.
Параболической зависимостью величины Y от величины Х называется зависимость, выраженная квадратичной функцией (параболой 2-ого порядка):
![]() .
(4.8)
.
(4.8)
Это уравнение называется уравнением параболической регрессии Y на Х. Параметры а, b, с называются коэффициентами параболической регрессии. Вычисление коэффициентов параболической регрессии всегда громоздко, поэтому для расчетов рекомендуется использовать компьютер.
Уравнение (4.8) параболической регрессии является частным случаем более общей регрессии, называемой полиномиальной. Полиномиальной зависимостью величины Y от величины Х называется зависимость, выраженная полиномом n-ого порядка:
![]() , (4.9)
, (4.9)
где числа аi (i=0,1,…, n) называются коэффициентами полиномиальной регрессии.
Степенная регрессия.
Степенной зависимостью величины Y от величины Х называется зависимость вида:
![]() . (4.10)
. (4.10)
Это уравнение называется уравнением степенной регрессии Y на Х. Параметры а и b называются коэффициентами степенной регрессии.
Если прологарифмировать обе части уравнения степенной регрессии, то получится уравнение
ln![]() =lna+b·lnx. (4.11)
=lna+b·lnx. (4.11)
Это уравнение описывает прямую на плоскости с логарифмическими координатными осями lnx и ln . Поэтому критерием применимости степенной регрессии служит требование того, чтобы точки логарифмов эмпирических данных lnxi и lnуi находились ближе всего к прямой (4.11).
Показательная регрессия.
Показательной (или экспоненциальной) зависимостью величины Y от величины Х называется зависимость вида:
![]() (или
(или
![]() ). (4.12)
). (4.12)
Это уравнение называется уравнением показательной (или экспоненциальной) регрессии Y на Х. Параметры а (или k) и b называются коэффициентами показательной (или экспоненциальной) регрессии.
Если прологарифмировать обе части уравнения степенной регрессии, то получится уравнение
ln![]() =x·lna+lnb
(или ln
=k·x+lnb). (4.13)
=x·lna+lnb
(или ln
=k·x+lnb). (4.13)
Это уравнение описывает линейную зависимость логарифма одной величины ln от другой величины x. Поэтому критерием применимости степенной регрессии служит требование того, чтобы точки эмпирических данных одной величины xi и логарифмы другой величины lnуi находились ближе всего к прямой (4.13).
Логарифмическая регрессия.
Логарифмической зависимостью величины Y от величины Х называется зависимость вида:
=a+b·lnx. (4.14)
Это уравнение называется уравнением логарифмической регрессии Y на Х. Параметры а и b называются коэффициентами логарифмической регрессии.
Гиперболическая регрессия.
Гиперболической зависимостью величины Y от величины Х называется зависимость вида:
![]() . (4.15)
. (4.15)
Это уравнение называется уравнением гиперболической регрессии Y на Х. Параметры а и b называются коэффициентами гиперболической регрессии и определяются методом наименьших квадратов. Применение этого метода приводит к формулам:
![]() ,
,
![]() , (4.16)
, (4.16)
где:
![]() ,
,
![]() , (4.17)
, (4.17)
![]() .
.
В формулах (4.16-4.17) суммирование проводится по индексу i от единицы до количества наблюдений n.
К сожалению, в Excel нет функции, вычисляющих коэффициенты гиперболической регрессии. В тех случаях, когда заведомо не известно, что измеряемые величины связаны обратной пропорциональностью, рекомендуется вместо уравнения гиперболической регрессии искать уравнение степенной регрессии, так в Excel имеется процедура ее нахождения. Если же между измеряемыми величинами предполагается гиперболическая зависимость, то коэффициенты ее регрессии придется вычислять с помощью вспомогательных расчетных таблиц и операций суммирования по формулам (4.164.17).
Быстрое построение нелинейных регрессий в Excel с помощью тренда.
В Excel с помощью добавления линии тренда можно быстро построить, помимо линейной регрессии, следующие виды нелинейных регрессий: логарифмическая, полиномиальная, степенная, экспоненциальная.
Для построения графика нелинейной регрессии, так же как при построении линейной регрессии, необходимо построить график экспериментальных точек (точечная диаграмма) и, не сбрасывая выделения с полученной диаграммы, выполнить команду ДиаграммаДобавить линию тренда. В появившемся диалоговом окне во вкладке Тип выбрать наиболее подходящий для данных экспериментальных точек тип нелинейной регрессии. Во вкладке Параметры следует отметить Показывать уравнения на диаграмме и Поместить на диаграмме величину достоверности аппроксимации (R^2) (при необходимости).
В
результате будет проведена кривая
линия, называемая линией тренда или
регрессии, к которой ближе всего
располагаются экспериментальные точки.
На этой диаграмме также будут выведены
уравнение соответствующей регрессии
и коэффициент достоверности аппроксимации
![]() (квадрат коэффициента корреляции в
случае линейной зависимости). Величина
,
так же как и для линейной зависимости,
показывает, насколько точно полученное
уравнение регрессии описывает зависимость
экспериментальных данных. Если
близок к единице, то полученное уравнение
регрессии с достаточной степенью
точности хорошо описывает экспериментальную
зависимость (теория согласуется с
экспериментом). Если
близок к нулю, то выбранный тип нелинейной
регрессии плохо описывает экспериментальную
зависимость (теория не согласуется с
экспериментом).
(квадрат коэффициента корреляции в
случае линейной зависимости). Величина
,
так же как и для линейной зависимости,
показывает, насколько точно полученное
уравнение регрессии описывает зависимость
экспериментальных данных. Если
близок к единице, то полученное уравнение
регрессии с достаточной степенью
точности хорошо описывает экспериментальную
зависимость (теория согласуется с
экспериментом). Если
близок к нулю, то выбранный тип нелинейной
регрессии плохо описывает экспериментальную
зависимость (теория не согласуется с
экспериментом).
Практические задания
4.1. Вычисление корреляционного момента,
коэффициентов корреляции и линейной регрессии.
Построение прямой линейной регрессии
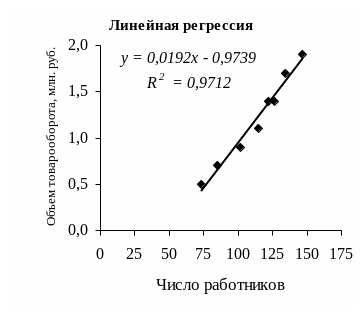
Получены данные о числе работников магазинов (величины xi) и объем розничного товарооборота в млн. руб. (величины yi):
xi |
73 |
85 |
102 |
115 |
122 |
126 |
134 |
147 |
yi |
0,5 |
0,7 |
0,9 |
1,1 |
1,4 |
1,4 |
1,7 |
1,9 |
Предполагается, что в исследуемой группе магазинов значения факторов, влияющих на объем товарооборота (к этим факторам относятся, например, объем основных фондов, их структура, площади торговых залов и подсобных помещений, расположение магазинов по отношению к потокам покупателей и т.д.), примерно одинаковы. Поэтому влияние различия их значений на изменение объема розничного товарооборота сказывается незначительно.
Исследовать связь объема розничного товарооборота магазинов и числа работников в них, т.е. найти ковариацию, коэффициент корреляции и получить уравнение линейной регрессии Y на X (если коэффициент корреляции покажет соответствующую тесноту линейной связи). Определить, какой объем розничного товарооборота в млн. руб. можно ожидать при увеличении числа работников магазинов до 170. Вычисления произвести с помощью стандартных функций, затем построить график линейной регрессии двумя способами: с помощью Пакета анализа и быстрым добавлением линии тренда.
Для выполнения этого задания проделайте следующие пункты.
Наберите исходные данные в два столбца, в заголовке которых наберите буквы X и Y, соответственно, в ячейки А1 и В1. Тогда данные займут диапазон А2:А9, а данные займут диапазон ячеек В2:В9.
Сначала вычислите основные корреляционные характеристики с помощью стандартных функций Excel. В ячейку А10 наберите: «хy=» (используя для набора шрифт Symbol и команду ФорматЯчейкиШрифтНижний индекс для набора нижних индексов, предварительно выделив их). Содержание этой ячейки выровняйте по правому краю. В ячейку В10 наберите формулу для вычисления ковариации (4.1): =КОВАР(А2:А9; В2:В9) и нажмите Enter. Содержание этой ячейки выровняйте по левому краю. Должно получиться: хy=10,475.
Вычислите коэффициент корреляции (4.3). Наберите в ячейку А11: «r=», выделите ее курсивом и выровняйте по правому краю. В ячейку В11 наберите формулу для вычисления коэффициента корреляции (4.3): =КОРРЕЛ(А2:А9; В2:В9) и нажмите Enter. Выровняйте содержание этой ячейки по левому краю. Должно получиться: r=0,9855.
Вычислите теперь эту же величину с помощью другой функции ПИРСОН в следующей строке. Оформление результата произведите так же, как и в пункте 3, обозначив коэффициент корреляции через rp. Убедитесь, что результат действия функций ПИРСОН и КОРРЕЛ одинаковый.
Вычислите квадрат коэффициента корреляции в следующей строке с помощью функции КВПИРСОН. Оформление содержания этих ячеек произведите так же, как и в пункте 3. В результате выполнения в ячейках А13 и В13 должно получиться: r2=0,9712.
Поскольку величина коэффициента корреляции близка к единице, то есть основания предполагать наличие зависимости между величинами Х и Y. Вычислите коэффициент линейной регрессии Y на Х
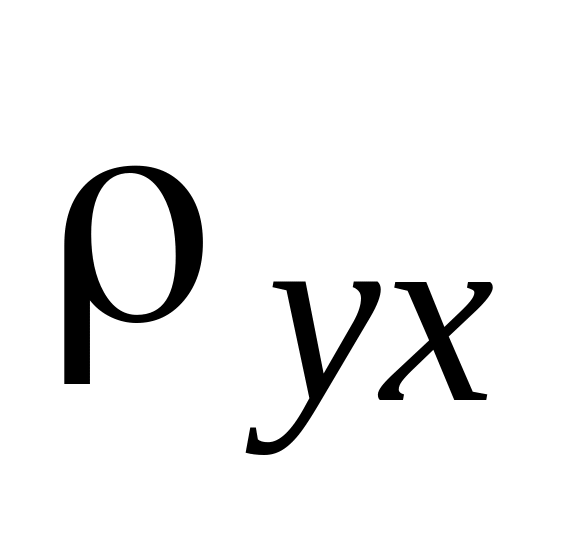 .
В ячейку А14 наберите: «
=».
В ячейку В14 наберите формулу: =НАКЛОН(В2:В9;
А2:А9). Содержание ячеек А14 и В14 оформите
по аналогии с пунктом 3. Должно получиться:
=0,0192.
Коэффициент регрессии
.
В ячейку А14 наберите: «
=».
В ячейку В14 наберите формулу: =НАКЛОН(В2:В9;
А2:А9). Содержание ячеек А14 и В14 оформите
по аналогии с пунктом 3. Должно получиться:
=0,0192.
Коэффициент регрессии
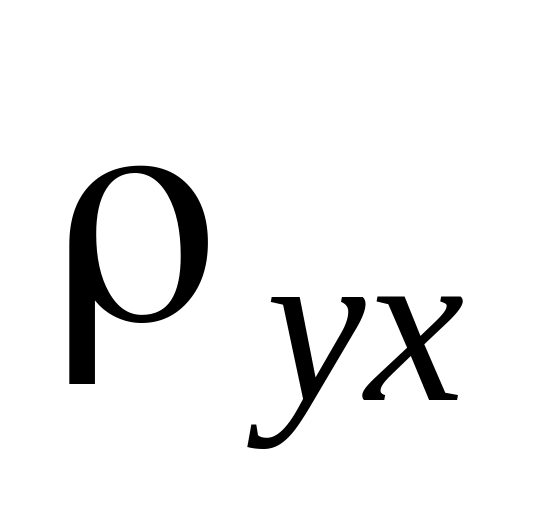 =0,019
показывает, что увеличение численности
работников магазина на одного человека
приводит к увеличению товарооборота
в среднем на 19 тысяч рублей. Это своего
рода эмпирический норматив приростной
эффективности использования работников
данной группы магазинов. Если увеличение
численности на одного работника приводит
к меньшему росту объема товарооборота,
то прием его на работу необоснован.
=0,019
показывает, что увеличение численности
работников магазина на одного человека
приводит к увеличению товарооборота
в среднем на 19 тысяч рублей. Это своего
рода эмпирический норматив приростной
эффективности использования работников
данной группы магазинов. Если увеличение
численности на одного работника приводит
к меньшему росту объема товарооборота,
то прием его на работу необоснован.Вычислите второй коэффициент регрессии Y на Х. В ячейку А15 наберите: «
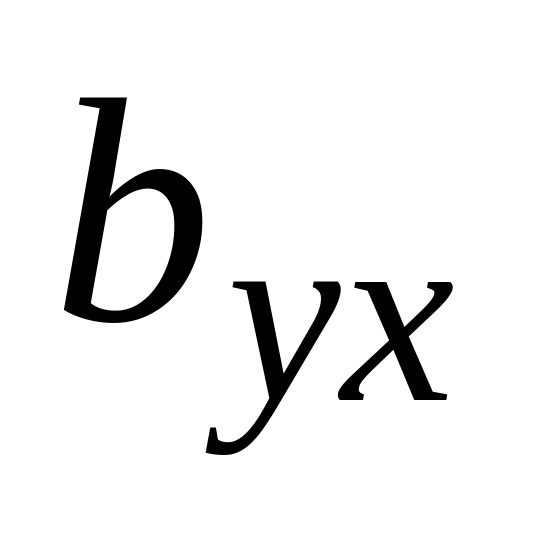 =».
В ячейку В15 наберите формулу:
=ОТРЕЗОК(В2:В9; А2:А9). Должно получиться:
=0,9739.
Это означает, что уравнение линейной
регрессии Y
на Х
имеет вид:
=».
В ячейку В15 наберите формулу:
=ОТРЕЗОК(В2:В9; А2:А9). Должно получиться:
=0,9739.
Это означает, что уравнение линейной
регрессии Y
на Х
имеет вид:
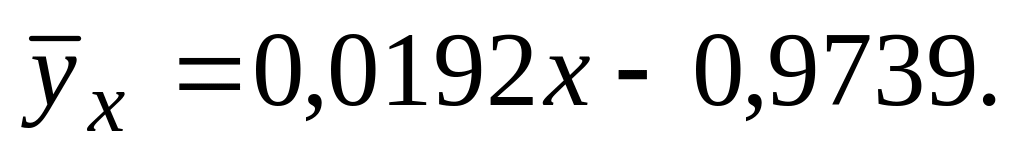
Теперь вычислите коэффициент линейной регрессии Х на Y. Для этого в ячейку А16 наберите: «
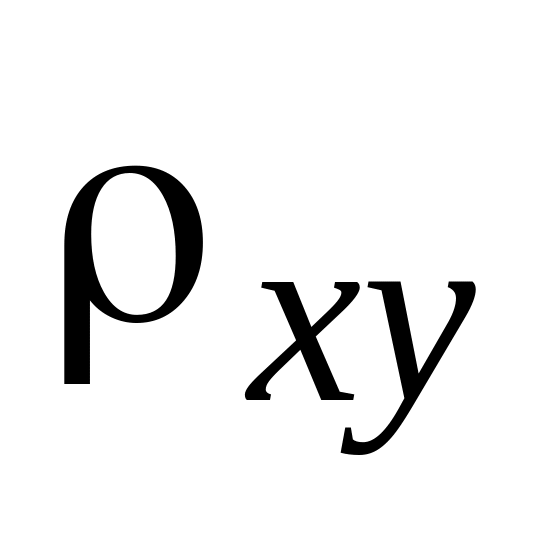 =».
В ячейку В16 наберите формулу для его
вычисления: =НАКЛОН(А2:А9; В2:В9). Должно
получиться:
=50,482.
=».
В ячейку В16 наберите формулу для его
вычисления: =НАКЛОН(А2:А9; В2:В9). Должно
получиться:
=50,482.В ячейку А17 наберите: «
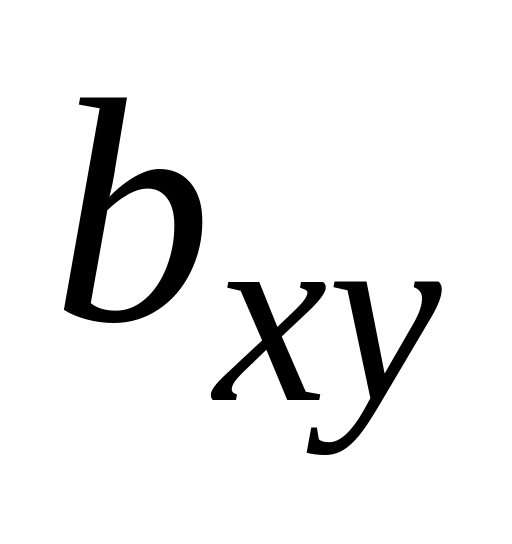 =».
В ячейку В17 наберите формулу:
=ОТРЕЗОК(А2:А9; В2:В9). Должно получиться:
=52,422.
Это означает, что уравнение линейной
регрессии Х
на Y
имеет вид:
=».
В ячейку В17 наберите формулу:
=ОТРЕЗОК(А2:А9; В2:В9). Должно получиться:
=52,422.
Это означает, что уравнение линейной
регрессии Х
на Y
имеет вид:
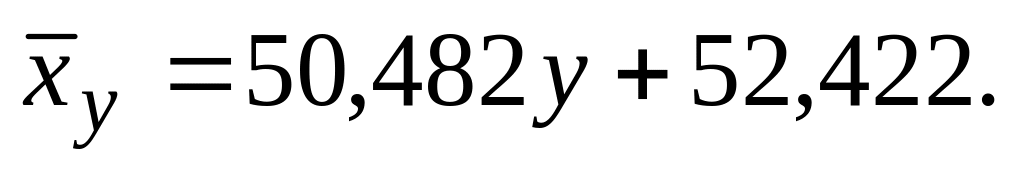
Определите, какой объем розничного товарооборота в млн. руб. можно ожидать при увеличении числа работников магазина до 170. Для этого в ячейку А18 наберите: «Y(170)=». Затем в ячейку В18 наберите формулу: =ПРЕДСКАЗ(170; В2:В9; А2:А9) и нажмите Enter. В результате должно получиться: Y(170)=2,2966. Это означает, что при наличии в магазине 170 работников объем розничного товарооборота составит примерно 2,3 млн. руб.
Теперь постройте график линейной регрессии Y на Х с помощью Пакета анализа. Выполните команду СервисАнализ данных и выберите инструмент анализа Регрессия.
В появившемся диалоговом окне Регрессия:
в поле Входной интервал Y: наберите: В2:В9 (или выделите этот интервал мышью, тогда его адрес появится в поле, где курсор);
в поле Входной интервал Х: наберите: А2:А9 (или выделите его мышью);
активизируйте переключатель Уровень надежности (по умолчанию установлено 95%);
активизируйте переключатель Выходной интервал и в ставшее активным (белым) поле поместите адрес ячейки D3;
активизируйте переключатель График подбора и нажмите ОК. Не сбрасывая выделение, сразу выполните команду ФорматСтолбецАвтоподбор.
В результате вычислений появится несколько таблиц под названием Вывод итогов и график подбора. Первая таблица Регрессионная статистика должна иметь вид:
Регрессионная статистика |
|
Множественный R |
0,985475971 |
R-квадрат |
0,971162888 |
Нормированный R-квадрат |
0,966356703 |
Стандартная ошибка |
0,089321148 |
Наблюдения |
8 |
Она занимает интервал: D5:Е10. Убедитесь, что в ячейке Е5 содержится вычисление значения коэффициента корреляции, в ячейке Е6 – его квадрат, в ячейке Е10 – количество парных наблюдений.
Следующая таблица называется Дисперсионный анализ, она занимает диапазон D12:I16. Ее структуру мы не рассматриваем.
Следующая таблица занимает диапазон D18:L20 и содержит коэффициенты регрессии, их стандартные ошибки и границы доверительных интервалов. Фрагмент этой таблицы имеет вид:
|
Коэффициенты |
Нижние 95% |
Верхние 95% |
Y-пересечение |
-0,973875115 |
-1,35597 |
-0,59178 |
Переменная X1 |
0,019237833 |
0,015926 |
0,022549 |
Строка
Y-пересечение
содержит характеристику коэффициента
,
а строка Переменная
X1 содержит
характеристику коэффициента регрессии
.
Убедитесь, что содержание ячейки Е19
совпадает с вычисленным ранее
коэффициентом
,
а содержание ячейки Е20 – с вычисленным
ранее
.
Доверительные интервалы (с 95% надежностью)
для этих коэффициентов оказались
следующими: 0,0159<
<0,0225
и –1,3559<![]() <0,5917.
Это означает, что можно указать
статистическую погрешность коэффициентов:
b=
<0,5917.
Это означает, что можно указать
статистическую погрешность коэффициентов:
b=
![]() ,
где
нижняя граница интервала, и =
,
где
нижняя граница интервала, и =
![]() ,
где
нижняя граница соответствующего
доверительного интервала. Вычислите
их самостоятельно.
,
где
нижняя граница соответствующего
доверительного интервала. Вычислите
их самостоятельно.
Результаты
регрессионного анализа принято записывать
в виде:
=0,0192![]() 0,0033;
=0,9739
0,3821.
Погрешность для второго коэффициента
0,0033;
=0,9739
0,3821.
Погрешность для второго коэффициента
![]() оказалась больше, чем погрешность для
.
Однако величина достоверности
аппроксимации, которая совпадает с
квадратом коэффициента корреляции для
линейной регрессии, близка к единице
(r2=0,9711),
что позволяет с достаточной степенью
точности утверждать о хорошей
согласованности теоретической зависимости
(уравнение линейной регрессии) с
наблюдаемыми данными.
оказалась больше, чем погрешность для
.
Однако величина достоверности
аппроксимации, которая совпадает с
квадратом коэффициента корреляции для
линейной регрессии, близка к единице
(r2=0,9711),
что позволяет с достаточной степенью
точности утверждать о хорошей
согласованности теоретической зависимости
(уравнение линейной регрессии) с
наблюдаемыми данными.
Последняя таблица с результатами вычислений инструмента анализа Регрессия называется Вывод остатка и имеет вид:
Наблюдение |
Предсказанное Y |
Остатки |
1 |
0,430486685 |
0,069513315 |
2 |
0,66134068 |
0,03865932 |
3 |
0,988383838 |
-0,088383838 |
4 |
1,238475666 |
-0,138475666 |
5 |
1,373140496 |
0,026859504 |
6 |
1,450091827 |
-0,050091827 |
7 |
1,60399449 |
0,09600551 |
8 |
1,854086318 |
0,045913682 |
Она
занимает диапазон D24:F34.
Столбец Предсказанное
Y
содержит вычисленные по полученной
формуле
![]() значения yi
для каждого наблюдаемого значения
.
В столбце Остатки
приведены
разности между наблюдаемыми значениями
значения yi
для каждого наблюдаемого значения
.
В столбце Остатки
приведены
разности между наблюдаемыми значениями
![]() из диапазона В2:В9 и рассчитанными по
формуле линейной регрессии значениями
из соседнего столбца Предсказанное
Y.
из диапазона В2:В9 и рассчитанными по
формуле линейной регрессии значениями
из соседнего столбца Предсказанное
Y.
Правее полученных таблиц имеется график подбора. самостоятельно придайте квадратную форму этой диаграмме. Соедините розовые маркеры сплошной линией без маркеров, очистите линии сетки и сделайте фон диаграммы белым.
Теперь постройте график линейной регрессии быстрым способом. Для этого выделите исходные данные (интервал ячеек А2:В9) и вызовите Мастер диаграмм. Выберите Тип диаграммы – Точечная и нажмите Готово.
Не сбрасывая выделения с диаграммы, выполните команду ДиаграммаДобавить линию тренда.
В появившемся диалоговом окне Линия тренда: во вкладке Тип выберите Линейная; во вкладке Параметры активизируйте переключатели Показывать уравнения на диаграмме и Поместить на диаграмму величину достоверности аппроксимации (R^2), а затем нажмите ОК.
В результате на диаграмме будет проведена прямая линия регрессии, ближе всего к которой располагаются экспериментальные точки, на графике будет выведено уравнение этой прямой (убедитесь, что входящие в него коэффициенты совпадают с вычисленными ранее), а также величина R2 (убедитесь, что она совпадает с вычисленным ранее квадратом коэффициента корреляции).
Полученную диаграмму самостоятельно приведите к следующему виду: