

Лабораторна робота №1. Тема: Архітектура процесора Pentium.
Мета: розглянути особливості архітектури процесора Pentium, навчитися оптимізовувати код для парного виконання.
Теоретичні відомості
Процесор Pentium виконаний за суперскалярною архітектурою з двома паралельними цілочисловими конвеєрами (U pipe і V pipe). Ці конвеєри можуть виконувати інструкції одночасно таким чином, що процесор Pentium може виконувати дві інструкції, навіть якщо вони обидві одночасно звертаються до пам'яті .
Конвеєризація дозволяє кільком інструкціям, кожній на різних стадіях виконання, оброблятися за один цикл.
Головний конвеєр - це конвеєр U, який є покращеним конвеєром процесора Intel 486. Конвеєр U може виконувати кожну інструкцію з набору команд.
Додатковий конвеєр V подібний до конвеєра U, але має деякі обмеження по інструкціях, які він може виконувати. Конвеєр V виконує більшість з часто використовуваних цілочислених інструкцій.
Цілочислові інструкції проходять п'ять ступенів конвеєра. Кожна ступінь відповідає за інакший аспект виконання команди (рис.1).
попередня вибірка (PF);
перша стадія декодування (D1);
друга стадія декодування (D2);
виконання (EX);
буфер запису (WB)
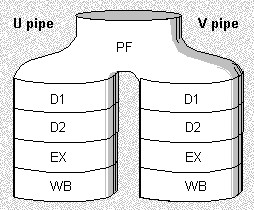
Рис. 1 Ступені цілочисельного конвеєра.
Блок попередньої вибірки команд процесора Pentium містить чотири 32-байтові буфери попередньої вибірки. Блок попередньої вибірки розміщує інструкції в буферах вибірки з випередженням достроково, так що вони завжди доступні в потрібний час. Таким чином, блок попередньої вибірки не має доступу до зовнішньої пам'яті чи кешу команд, щоб одержати наступну команду для виконання. Блок попередньої вибірки команд використовує два буфери для послідовної попередньої вибірки і два буфери для передбаченого отримання вибраних команд. Процесор Pentium може попередньо вибирати команди через границю рядка кеша, без простою.
Парність є здатністю процесора Pentium сприймати дві команди для одночасного виконання в конвеєрах U і V. Тільки перед передаванням команд до стадії D1, процесор перевіряє наступні дві команди, щоб побачити, чи вони можуть бути подані до конвеєрів U і V одночасно.
Кожна команда класифікується відповідно до того, як вона може паруватися в конвеєрах (рис. 2):
UV: Може паруватися в будь-якому конвеєрі. Приклади: mov, test, dec, add, cmp, inc, sub та інші прості логічні та арифметичні інструкції;
PU: Може паруватися, але тільки якщо подана до конвеєра U. Приклади: adc, sbb, mul, div та інші їм подібні інструкції;
PV: Може паруватися, але тільки якщо подана до конвеєра V. Приклади: call, jcc та інші команди переходів. Ці команди є PV, через те, що вони переходять до вихідної команди, яка не може виконуватися в той же час, що і перехід безпосередньо;
NP: Не може паруватися; повинна виконуватися в конвеєрі U. Приклади: idiv, imul, movsx, setcc та інші.
Якщо дві команди можуть паруватися, перша команда подається до конвеєра U і друга команда подається до конвеєра V.
Якщо дві команди не можуть паруватися, перша команда подається до конвеєра U і жодна команда не подається до конвеєра V.
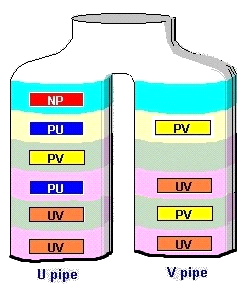
Рис. 2 Приклади парного виконання інструкцій.
Хоча дві команди можуть виконуватися паралельно, зовнішньо вони забезпечують ту ж саму семантику, якби вони виконувались послідовно. Тобто, процесор зберігає точну послідовність виконання команд і наявність переривань і виключень.
У випадку простою конвеєра, наступним командам не дозволяється передати очікуючу команду в інший конвеєр.
Протягом виконання, процесор Pentium також підтримує порядок доступів до пам'яті. Це означає, що команда V-конвеєра може зробити перший доступ до пам'яті тільки тоді, коли команда U-конвеєра зробить останній доступ до пам'яті. Таким чином порядок, в якому записані команди в програмі є порядком виконання, в якому вони спостерігаються зовнішньо.
Розгляньте, наприклад, цей код:
inc mem
mov edx, eax
mov ecx, edi
add ecx, 3
mov ecx, mem
inc mem і mov паруються і прибувають разом до стадії EX. inc mem потребує 3 цикли для виконання і звертається до пам'яті в першому і третьому циклі. mov не може почати виконуватись до третього циклу, коли inc mem робить останній доступ до пам'яті. Тим часом, другий mov стає в чергу на стадії D2 і add стає в чергу на стадії D1.
Пристрій динамічного передбачення переходів процесора Pentium намагається передбачити певну множину команд, що виконуються. Правильне передбачення переходів зберігається в буферах пеопередньої вибірки і конвеєри працюють настільки ж повно, наскільки можливо при мінімізації конвеєрних черг завдяки переходам. Інструкції виконуються без штрафних циклів, коли передбачення правильне.
Процесор Pentium кешує інформацію про попередні переходи в малому кеші, що називається буфер переходів - Branch Target Buffer (BTB). Ця інформація використовується для передбачення наступних переходів. Передбачення відбувається на ранній стадії конвеєра. Коли передбачення правильне, переходи виконуються без затримок. Всі передбачення контролюються в кінці конвеєра.
Коли перехід передбачений помилково, процесор Pentium повинен зняти некоректні команди з конвеєра і почати викликати команди від попереднього правильного шляху. За винятком умовних переходів в конвеєрі V, всі помилково передбачені розгалуження, виклики, безумовні і умовні переходи викликають затримку в 3 штрафних цикли. Помилково передбачений перехід в конвеєрі V викликає затримку в 4 штрафних цикли.
Серцем апаратних засобів передбачення переходів є кеш, що називається буфером переходів. Буфер переходів має 256 входжень і є 4-канальним набірно-асоціативним. Ознакою, яка використовується для доступу до буферу переходів, є адреса інструкції переходу.
Порція даних в буфері переходу включає адресу адресата переходу і два біти історії, що використовуються для передбачення, прийметься перехід чи ні. Два біти історії допомагають у випадку, де перехід узгоджено приймається деякий час, потім випадково не приймається. Передбачення змінюється тільки тоді, коли перехід є помилково передбаченим два рази підряд.
Процесор Pentium має окремі, вбудовані на одному з ним кристалі, кеші команд і даних. Вбудовані кеші збільшують продуктивність системи за допомогою швидшої обробки запитів на зчитування/запис внутрішньо, ніж зверненням до пам'яті. Кеші також зменшують використання процесором зовнішньої шини даних, коли одні й ті ж комірки пам'яті опитуються багатократно.
Наявність окремих кешів даних і команд дозволяє суміщені перегляди кешів. До двох звертань до даних і 32 байти необробленого опкоду можуть бути доступні за один цикл.
Кожен кеш процесора Pentium має дві частини:
- Пам'ять довільного доступу даних, яка містить дані, що заносяться з пам'яті.
- Пам'ять довільного доступу ознак, яка містить інформацію про адреси даних в оперативній пам'яті.
Пам'ять довільного доступу в кеші даних розділяється на рядки. Кожен рядок кешу містить фіксовану, рівну частину даних (рядок) з оперативної пам'яті.
Асоціативність кешу визначає те, як рядки пам'яті переводяться в рядки кешу.
Кеш команд має наступні характеристики:
- містить 8 Kбайт інформації;
- є двоканальним асоціативно-набірним кешем;
- має довжину рядка в 32 байти;
- підтримує алгоритм заміщення LRU (Last Recently User - блок даних в кеші);
- підтримує методи відновлення попереднього значення рядка.
Кеш команд не підтримує часткові заповнення рядка кешу, так що кешування навіть 1-байтової команди вимагає кешування повного рядка в 32 байти.
Мінімальна затримка для кешового промаху - 3 штрафних цикли.
В процесорі Pentium кожний кеш має 128 сетів (множин) по два рядки. Сетом є група рядків кешу, в яку даний рядок в пам'яті може бути поміщений. Кожна адреса пам'яті переводитьсяться до однієї специфічної множини.
Процесор Pentium має два шляхи; кожний має 128 рядків. Шляхом є група рядків кешу, яка містить один рядок від кожного сету.
Асоціативність кешу визначає кількість рядків кешу, в які поміщується дана адреса пам'яті.
Кеші команд і даних процесора Pentium є двоканальними асоціативно-набірними. Кожен рядок з оперативної пам'яті може розміщуватись в два рядки кешу. Розміщення рядка оперативної пам'яті в кеші підраховується від частини його адреси в оперативній пам'яті. Залишок адресних бітів зберігається у ознаці входження рядка кешу.
Для того, щоб краще зрозуміти те, як працює кеш, уявіть, як рядок вставляється в кеш.
Процесор спочатку намагається звернутися до адреси, не розташованої в кеші. Рядок пам'яті, в якій розміщується специфічна адреса переноситься в буфер. Номер рядка в сеті підраховується.
Далі, рядок вставляється в кеш. Процесор Pentium має двоканальний асоціативно-набірний кеш. Використовуючи алгоритм заміни LRU, процесор Pentium визначає, яким шляхом рядок буде вставлений в сет.
Адреси, до яких звертаються ваші додатки, можуть в той час і не зберігатися в кеші. Це зветься кешовим промахом. Є 3 типи кешових промахів:
- обов'язковий промах. Запит, який не досягає цілі, через те, що це є перший запит на даний рядок в пам'яті;
- конфліктний промах. Запит, який не досягає цілі через відсутність доступу в конкретний сет. Коли відбувається конфліктний промах, кеш-пам'ять не обов'язково повна:
- промах розрядності. Запит, який не досягає цілі через те, що кеш повний.
Щоб бути ефективними, кешам потрібно зберігати код і дані, які процесор найбільш ймовірно попросить. Кешування працює, завдяки двом принципам:
- просторове розміщення;
- часове розміщення.
Повідомлення в коді, який підтримує адреси просторового розміщення доступні послідовно. Тобто, дані або команди, до яких здійснюється доступ знаходяться близько до даних або команд, які в даний момент використовуються. У коді, який підтримує часове розміщення, кожна адреса в пам'яті доступна декілька разів, з дуже короткими інтервалами.
Розмір рядка кешу в 32-байта використовує переваги просторового розміщення. Коли процесор звертається до елемента в пам'яті, це вводить повний 32-байтовий рядок в кеш.
Заповнення рядка кешу генерує тільки промахи читання, не промахи запису. Тобто, промах запису в кеш не копіює пропущений рядок в кеш з пам'яті. Замість цього запис відсилається в буфер запису.
Процесор Pentium має два буфери запису, по одному для кожного конвеєра.
Обидва буфери запису можуть бути заповнені в тому ж циклі двома суміщеними промахами в кеші даних. Записи зберігаються у відповідному буфері, поки зовнішня шина звільниться, щоб виконати їх. Тим часом, процесор може обробити наступну множину команд.
Буфери запису завжди очищуються в тій самій послідовності, в якій записи були згенеровані програмами. Процесор Pentium гарантує, що операції зчитування даних з буферів запису ніколи не перевпорядковуються наперед незавершених операцій запису даних. Це робить існування буферів запису прихованим для програмного забезпечення.
Процесор Pentium містить високопродуктивний пристрій для роботи з плаваючою крапкою - FPU (математичний співпроцесор), який забезпечує значні цифрові можливості і підтримку операцій з плаваючою комою, розширеного цілого числа і типів даних BCD.
Процесор Pentium координує обробку цілих і з плаваючою комою чисел, до певної міри приховану від програмного забезпечення. Крім того, вбудовані засоби координації дозволяють конвеєрам цілого числа обробляти інші інструкції, в той час, як математичний співпроцесор виконує цифрові інструкції.
Математичний співпроцесор процесора Pentium приєднує триступінчатий конвеєр з плаваючою крапкою до цілочисленних п'ятиступінчатих конвеєрів. Команди операцій над числами з плаваючою комою проходять через регулярні стадії цілочисленних конвеєрів до стадії виконання (EX).
Хоча тільки одна команда операцій над числами з плаваючою комою може виконуватись в будь-якому циклі, конвеєр з плаваючою комою дозволяє двом додатковим командам виконуватися одночасно в конвеєрі на стадії X1 і на стадії X2.
Після того, як команда операції над числами з плаваючою комою закінчує виконання, все передається до стадії WF.
Більшість команд операцій над числами з плаваючою комою можуть бути допущені тільки до конвеєра U. Тільки команда fxch може бути допущена до конвеєра V.
Коли команда операції над числами з плаваючою комою може паруватися з fxch, вона допускається до конвеєра U, а fxch допускається до конвеєра V.
Математичний співпроцесор процесора Pentium безпосередньо підтримує наступні типи даних (рис. 3): ціле слово, коротке ціле число, довге ціле число, запаковане десяткове число, одинарне дійсне, подвійне дійсне, і розширене дійсне.
Математичний співпроцесор процесора Pentium підтримує цифрові інструкції.
Спеціальні програмні засоби не необхідні, щоб використовувати цифрові можливості, через те, що більшість стандартних компіляторів безпосередньо підтримують їх.

Рис. 3 Приклади типів даних, які підтримує математичний співпроцесор.
Операнди з плаваючою комою зберігаються в стеку з плаваючою комою. Стек складається з восьми 80-розрядних регістрів і вказівника вершини стеку. Регістри нумеруються від st(0) до st(7).
Більшість інструкцій над числами з плаваючою комою вимагають щонайменше одного операнда в st(0) (також званого вершиною стеку, або TOS), коли команда починає виконуватися. Згодом, після того, як команда виконає цикли продуктивності, операнд може бути переміщений в інше місце в стеці.
Операнди можуть бути завантажені по стековому використанню, наприклад, fld. Результати можуть бути збережені для використання пам'яті, наприклад, fst.
Команда, яка працює з вершиною стеку, не може почати виконуватись, доки попередні команди закінчують роботу з вершиною стеку. Звичайно, команда може почати виконуватись паралельно до дії команд на інших стекових регістрах з плаваючою комою.
У наведеному коді:
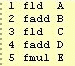
кожна команда діє на вершину стеку. Однак, коли fld C завантажує C до вершини стеку, А+B рухається до st(1); тобто, fadd B в дійсності діє на st(1). Таким чином, fadd D може почати виконуватись паралельно до fadd B.
fxch є єдиною з команд операцій над числами з плаваючою комою, яка може виконуватись в конвеєрі V. Всі інші команди операцій над числами з плаваючою комою класифікуються наступним чином:
- FX. Команди FX можуть паруватися з fxch.
- NP. Команди NP не можуть паруватися з fxch.
Команди операцій над числами з плаваючою комою не можуть паруватися з цілочисленими командами. Команда fxch можуть паруватися тоді, коли відбуваються всі наступні умови:
- команда операції над числом з плаваючою комою слідує за fxch;
- Команда FX виконується негайно за fxch;
- ця команда fxch вже виконувалась.
Це необхідно через те, що границі команд в кеші визначаються вперше тоді, коли команда виконується. Команди можуть паруватися тільки наступного разу, коли команда виконуються вже з кешу.
Більшість команд операцій над числами з плаваючою комою вимагають щонайменше одного операнду в вершині стека на початку виконання. Однак, після того, як команда виконує цикли продуктивності, операнди можуть бути розміщені в іншому місці в стеку.
Команда fxch обмінює вмістом вершину стека з вмістом будь-якого іншого стекового регістра. Через те, що fxch може паруватися з іншими командами операцій над числами з плаваючою комою, ви не втрачаєте жодного циклу.
У наведеному коді, fxch обмінює вмістом вершину стеку, C+D, з st(1), А+B. fmul E діє на новий вміст вершини стеку, А+B.
Шина даних передає інформацію між процесором і підсистемою пам'яті. Процесор Pentium має 64-розрядну зовнішню шину даних і може перенести дані до і від пам'яті зі швидкістю до 528 Mбайт/секунду. Дана шина даних гарантує стійкий потік команд і даних до пристрою виконання.
Процесор Pentium здійснює конвеєризацію циклу шини, щоб збільшити пропускну можливість шини. Це дозволяє другому циклу шини початися перед закінченням першого циклу.
Шина даних також має монопольний режим для високошвидкісної передачі інформації. Вбудовані (першого рівня) кеші використовують пошвидшений цикл чотирьох передач, щоб заповнити рядок кешу з пам'яті.
Процесор Pentium допускає виконання до двох цілочислених команд кожного циклу, одної в конвеєрі U і одної в конвеєрі V. Команди, що допускаються до конвеєрів одночасно, називаються командами, що паруються.
Є певні обмеження щодо парування команд:
- жодна команда, з тих, що паруються не NP, перша команда не PV, і друга не PU;
- немає регістрового суперництва між командами, за винятком конкретних спеціальних пар;
- команди з безпосередніми операндами і адресними зміщеннями не можуть паруватися;
- обидві інструкції є в кеші команд і вже виконувались. Якщо перша команда є однобайтовою, вона може паруватися, навіть якщо її треба прочитати з пам'яті.
Щоб зробити ваш код більш спроможним до парування, що гарантує використання найкращої переваги подвійного цілочисленого конвеєра процесора Pentium:
- уникайте регістрового суперництва;
- уникайте затримок AGI;
- уникайте конфліктів банків;
- не змішуйте 16-розрядний і 32-розрядний коди;
- розгортайте цикли;
- використовуйте одноциклові команди.
Залежність даних може спричиняти до регістрового суперництва, яке не дає двом командам паруватися. Регістрове суперництво може бути викликане залежністю потоку або залежністю виводу. Антизалежність не викликає регістрового суперництва. Тобто, дві антизалежні команди можуть паруватись.
Блокування генерації адреси - Address Generate Interlock (AGI) відбувається тоді, коли регістр, який використовується, як база або індексний компонент ефективного обчислення адреси, був регістром команди адресата, яка виконується в невідкладному попередньому циклі. Конфлікти AGI викликають 1-циклову затримку на стадії D2 в процесорі Pentium. Через те, що більш ніж одна команда може виконатися за цикл на процесорі Pentium, конфлікти AGI можуть бути викликані командами, які закінчилися до трьох команд назад.
Кеш-пам'ять даних процесора Pentium як і кеш команд, поділена на вісім банків, з чергуванням за межами в 4 байт. Кеш даних подвійно портовий і може бути доступним одночасно інструкціям в обох конвеєрах. Однак, якщо обидві команди звертаються до даних з одного банку кешу даних, відбувається банківський конфлікт. Коли відбувається банківський конфлікт, команда V-конвеєра затримується на один цикл на стадії D2.
Змішування 16-розрядного і 32-розрядного коду потребують багато команд знакового розширення і префіксні команди. Префіксні інструкції збільшують час декодування. Префіксні команди займають два цикли на стадії D2: в першому циклі префікс декодується, а в другому циклі декодується безпосередньо команда.
В дійсності, префікси обмежують парування, так як UV-команда без префікса, стає PU-командою з префіксом. Також, якщо команди V-конвеєра стала в чергу під час обробки префікса, префікс може оброблятися і більше двох циклів.
Є декілька причин для розгортання циклів в цілочисленому коді:
- Зменшується переповнення переходів.
- Зменшується кількість разів, коли умова перевіряється в кінці циклу.
- Збільшується можливість парування.
Однак, розгорнення циклів збільшує розмір вашого коду.
Процесор Pentium підтримує порядок доступів до пам'яті. Це означає, що, якщо команда U-конвеєра потребує більш ніж один цикл для виконання, команда V-конвеєра затримується, доки команда в конвеєрі U робить останній доступ до пам'яті. Таким чином, щоб виставити можливості для парування, інколи краще вибрати послідовність одноциклових команд, ніж відповідних багатоциклових команд.
Цей метод називається завантаженням/збереженням стилю генерування коду.
Парування має більшу ефективність, коли використовуються одноциклові команди, тому що:
- одноциклові команди виконуються за один цикл, таким чином збільшуючи можливість планування;
- за винятком команд завантаження/збереження, одноциклові команди не звертаються до пам'яті;
Процесор Pentium має динамічну схему передбачення переходів з 256-вхідним буфером переходів (BTB);
Перехід, який передбачений вірно, не зазнає затримки в виконанні. Команда переходу, яка передбачена помилково, простоює штрафні цикли. Це додає 3-циклову або 4-циклову затримку, залежно від типу команди переходу і конвеєра виконання.
Основне перевпорядковування блоків є асемблерною технікою, яка включає таке організовування вашого коду:
- найчастіше розгалуження, що відбулося є розгалуженням по замовчуванню;
- "не взятий" код розміщується наскільки можливий далі від "взятого" коду, ідеально, якщо в кінці функції або файла.
Процесор Pentium має два вбудованих кеші (першого рівня): кеш команд і кеш даних.
Коли процесор запитує інформацію, він спочатку перевіряє відповідний вбудований кеш. Якщо інформація доступна в кеш-пам'яті, це називається кешовим попаданням; інакше відбувається кешовий промах.
Коли відбувається промах, процесор перевіряє кеш другого рівня (на материнській платі). Якщо запит знайдено в цьому кеші, мінімальне покарання буде 3 штрафних цикли. Якщо запит і тут не досягає цілі, або немає кешу другого рівня, процесор повинен дістати цю інформацію з пам'яті. Це спричиняє мінімальну затримку в 7 циклів, а можливо і в 10 циклів!
Процесор Pentium може мати доступ до даних в будь-якому байтовому розміщенні. Однак, невирівняне розташування в кеші даних потребує додатково 3 цикли обробки. Щоб уникнути цього, необхідно вирівняти об'єкти даних відповідно до їхнього розміру.