

Математическое обеспечение
Разрабатываемая система будет служить для прогноза синдрома внезапной смерти грудных детей. Прогноз будет ставиться с помощью статистических методов. На вход будут подаваться данные: год рождения, адрес проживания, группа крови, резус фактор, короткие данные про перенесенные раньше болезни, их последствия и другое. На выходе получаем прогноз риска синдрома внезапной смерти, который может быть высоким и низким.
Существуют более 200 классических методов статистического анализа. Выбор метода зависит от решаемой задачи, а также от типа собранных данных. Кроме того, у каждого метода имеются свои предпосылки и ограничения. Иногда одну и ту же задачу можно решить с помощью 4-5 различных методов. По всем вышеуказанным причинам к выбору метода нужно подходить достаточно осторожно.
Статистические методы обработки стали привычным и широко распространенным аппаратом для работников медицины и здравоохранения, например диагностические таблицы, пакеты прикладных программ для статистической обработки данных на ЭВМ.
Статистическая совокупность — понятие, лежащее в основе всех статистических методов. Объекты, с которыми имеют дело в медицине, обладают большой вариабельностью — их характеристики меняются во времени и пространстве в зависимости от многих факторов, а также существенно отличаются друг от друга, Характеристики таких объектов обычно представляют в виде матрицы наблюдений, где столбцы соответствуют различным признакам, а строки — либо разным объектам, либо последовательным во времени наблюдениям за одним и тем же объектом.
Из-за вариабельности измеряемых признаков приходится считать их значения случайными величинами и пользоваться вероятностными (стохастическими) постановками задач: матрица наблюдений является выборкой, или выборочной совокупностью случайных величин из некоторой генеральной совокупности. Сама генеральная совокупность обычно трактуется как множество всех объектов определенного типа или как совокупность всех возможных реализаций какого-либо явления. Основными задачами статистического исследования являются выявление и анализ закономерностей, присущих объектам в выборке, с целью установления возможности и достоверности перенесения сделанных выводов на генеральную совокупность.
Признаки, характеризующие объекты в медицине и здравоохранении, подразделяются на количественные, порядковые и качественные. Для количественных признаков можно указать точную характеристику — число (например, вес, рост, величина АД, данные анализов), Для порядковых признаков (ранговых, если каждой градации ставится в соответствие число — ранг) точная характеристика невозможна, но можно указать степень выраженности соответствующего свойства (хрипы в легких — единичные, множественные; интенсивность кашля — слабая, средняя, сильная, очень сильная). Качественные признаки не поддаются упорядочиванию или ранжированию (цвет глаз — голубой, серый, карий).
Закон распределения случайной величины — это функция, определяющая вероятность того, что какой-либо признак примет заданное значение (если он дискретен) или попадает в заданный интервал значений (если он непрерывен). При большом числе выборочных данных, значения которых варьируют незначительно, закон распределения может быть аппроксимирован гистограммой. Для построения гистограммы интервал значений признака разбивается на равные участки, для которых подсчитывается частота попадания случайной величины. При бесконечном увеличении числа наблюдений и участков частота стремится к вероятности, а вид гистограммы приближается к кривой, выражающей функцию плотности (или плотности вероятности) случайной величины.
Законы распределения могут быть одномерными и многомерными. В последнем случае закон описывает вероятность появления сочетанных значений признаков или попадания их в некоторую область пространства признаков. В прикладной статистике особую роль играют несколько наиболее часто используемых законов распределения. Наиболее разработана гипотеза о нормальном распределении (закон Гаусса), функция плотности вероятности f (x) для которого имеет вид:
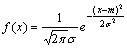 ,
,
де М — математическое ожидание,
s — среднеквадратическое (стандартное) отклонение,
е — основание натуральных логарифмов (e = 2.718...).
Величина s, возведенная в квадрат, называется дисперсией: D = s2Дисперсия характеризует разброс (вариабельность) случайной величины около среднего значения. При нормальном распределении случайной величины ее наблюдаемые значения с большой вероятностью (равной 0,9972) отклоняются от М в ту или другую сторону не более чем на 3s (правило трех сигм).
Оценка математического ожидания М по выборке (называемая выборочным средним) тоже является случайной величиной. Она описывается так называемым распределением Стьюдента. Это распределение зависит от числа наблюдений (числа степеней свободы) и приводится в справочниках по прикладной статистике. Критерий Стьюдента (t-критерий) используется для оценки и сравнения средних значений нормально распределенных случайных величин. Имеется обобщение закона и критерия Стьюдента на многомерный случай.
Выборочная дисперсия также является случайной величиной, распределение которой получило название распределения c2 (хи-квадрат) Пирсона (по имени одного из основоположников биометрии). Таблицы значений c2 включены во все пособия по статистике. На основании распределения c2 строятся доверительные интервалы случайных величин.
Для сравнения выборочных дисперсий двух серий наблюдений используют распределение Фишера, которое зависит от числа степеней свободы обеих выборок и также представлено в табличной форме. Критерий Фишера (F-критерий) применяется для сравнения выборочных дисперсий и формирования оценок в регрессионном, дисперсионном и дискриминантном анализе.
Перечисленные типы распределений относятся к непрерывным случайным величинам. Для дискретных случайных величин используется распределение Пуассона (закон редких явлений). Для таких же величин применяется закон распределения числа взаимоисключающих событий при конечном числе испытаний (биномиальное распределение). Эти распределения употребляются для описания случайных значений параметров в медицинской диагностике, при анализе популяционных процессов и т.п.
Статистическое оценивание применяют в медицинских исследованиях, когда получаемых данных недостаточно для установления вида функции распределения случайных величин. В этом случае предполагают, что реализуется один из законов распределения, а матрицу наблюдений используют для оценки параметров этого закона.
Статистические оценки могут быть точечными или интервальными. В первом случае оценка дается в виде чисел (как правило, это среднее значение и дисперсия). Во втором случае определяется интервал, в котором исследуемая случайная величина находится с заданной вероятностью. Получаемые оценки должны относиться к генеральной совокупности. Интервальная оценка генерального среднего (математического ожидания) производится на основе распределения Стьюдента (при числе наблюдений не более 50—60) или на основе гипотезы о нормальном распределении (при большем числе наблюдений). Для оценки генеральной дисперсии применяется распределение c2. Интервал, в котором с заданной вероятностью находится генеральный параметр, называется доверительным интервалом, сама такая вероятность — доверительной вероятностью. В медицинских исследованиях используют три порога доверительной вероятности b: 0,95; 0,99; 0,999. Чем точнее требуется результат, тем большим порогом задается исследователь и тем шире (при прочих равных условиях) получается доверительный интервал. В статистике наряду с понятием доверительной вероятности употребляется термин «уровень значимости». Соответственно применяются три уровня значимости 0,05; 0,01 и 0,001.
Дисперсионный анализ — статистический метод, применяемый для выявления влияния отдельных факторов (количественных, порядковых или качественных) на изучаемый признак и оценку степени этого влияния. Если изучается действие количественного фактора, то предварительно производится его разбивка на градации. Для каждой градации подсчитывается среднее значение изучаемого признака, затем дисперсия среднего по градациям фактора относительно общего среднего и, наконец, общая дисперсия изучаемого показателя (независимо от значения фактора).
В теории дисперсионного анализа показано, что общая дисперсия D равна дисперсии средних по градациям фактора DF (доля дисперсии за счет действия исследуемого фактора — объясненная дисперсия) плюс остаточная дисперсия за счет действия случайных факторов (DS): D = DF + DS. Чем больше эта величина, тем сильнее влияние фактора на изучаемый признак.
Кластерный анализ — группа методов статистической обработки, которая включает методы классификации объектов, в т.ч. автоматические, на основе их сходства. Кластерный анализ, как и факторный, «сжимает» информацию. Но если факторный анализ снижает размерность пространства признаков, то кластерный уменьшает число рассматриваемых объектов. Совокупность объектов разбивается на кластеры — группы объектов, обладающие сходными свойствами, поэтому вместо всей группы можно рассматривать один объект, характеризующий ее. Так, ряд административных территорий может быть представлен в виде одного кластера, объединяющего регионы с одинаковой эпидемиологической обстановкой. Кластерный анализ включает методы, которые исходно не принимают во внимание вероятностную природу обрабатываемых данных. При постановке задач кластеризации число кластеров, на которое должно быть разбито исходное множество объектов, может задаваться заранее или выявляться в процессе решения.
Алгоритмы кластерного анализа направлены на получение наилучшего в определенном смысле качества разбиения совокупности объектов на группы.
Другие методы прикладной статистики (исследование временных рядов и краткосрочное прогнозирование развивающихся во времени процессов, планирование эксперимента и др.) учитывают специфику задач и возможности использования для их решения ЭВМ.
Если для решения каких-либо задач не удается найти строгие формальные методы, то прибегают к интуитивно найденным способам, эффективность которых проверяется на практике. Поскольку подобные приемы являются результатом и имитируют интеллектуальную деятельность человека, они получили название эвристик. Эвристические методы применяются для таких задач анализа данных, как классификация, распознавание образов и т.п.
Прогноз будет ставится в среде MATLAB 6.0, с использованием Statistics Toolbox.
Заключение
Во время преддипломной практики были приобретены практические навыки работы с рабочими инструкциями и документами, которые регламентируют последовательность реализации системы в процессе диагностирования.
Специализированная компьютерная система определения степени риска синдрома внезапной смерти грудного ребенка актуальна на сегодняшний день. Разработаны проектные решения по техническому, программному и информационному обеспечениям, рассмотрены основные цели, функции и назначения разрабатываемой системы.
Недостатками данной СКС является недостаточная система факторов в базе данных и из-за этого невыявления СВС в некоторых случаях. Но, так как в системе учитывается дальнейшая возможность усовершенствования и дополнения с целью расширения ее функциональных возможностей, то в дальнейшем данная СКС будет незаменима в работе врачей.
Список литературы
М. А. Школьникова, Л. А. Кравцова “Синдром внезапной смерти младенцев”, Медпрактика-М, 2004 г.
Фролов А.В., Фролов Г.В. Аппаратное обеспечение IBM PC: в 2-х частях. Часть первая. - М.: «Диалог-МИФИ», 1992.-208 с.
Материалы первой и второй производственной практики
Приложение А