

Статистический анализ результатов имитации
Инструмент анализа данных «Корреляция». Определим степень тесноты взаимосвязей между переменными V, P, Q, NCF и NPV. При этом в качестве меры будем использовать коэффициент корреляции r. Выбираем в главном меню «Сервис»/«Анализ данных»/«Корреляция». Заполняем поля диалогового окна.
рис. 11 Заполнение окна инструмента «Корреляция»
Вид полученной таблицы:
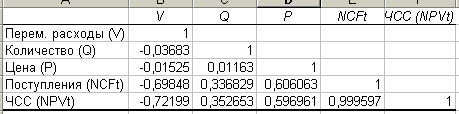
рис. 12 Результаты корреляционного анализа
Результаты корреляционного анализа представлены в виде квадратной матрицы, заполненной только наполовину, поскольку значение коэффициента корреляции между двумя случайными величинами не зависит от порядка их обработки. Нетрудно заметить, что эта матрица симметрична относительно главной диагонали, элементы которой равны 1, так как каждая переменная коррелирует сама с собой.
Как следует из результатов корреляционного анализа, выдвинутая гипотеза о независимости распределений ключевых переменных V, Q, P в целом подтвердилась. Значения коэффициентов корреляции между переменными расходами, количеством и ценой близки к 0.
В свою очередь величина показателя NPV зависит от величины потока платежей (r=0,999). Кроме того, существует корреляционная зависимость средней степени между Q и NPV (r=0,35), P и NPV (r=0,596). Между величинами V и NPV существует сильно выраженная обратная зависимость (r= -0,72).
Инструмент анализа данных «Описательная статистика».
Определим параметры описательной статистики для переменных V, Q, P,NCF, NPV. Выбираем в главном меню «Сервис»/«Анализ данных»/«Описательная статистика». Заполняем поля диалогового окна.

рис. 13 Заполнение полей диалогового окна «Описательная статистика»
Результатом выполнения указанных действий будет формирование отдельного листа, содержащего вычисленные характеристики описательной статистики для исследуемых переменных.

рис. 14 Описательная статистика для исследуемых переменных
Медиана – это значение случайной величины, приходящейся на середину совокупности, т.е. середина численного ряда или интервала. В данном примере, как следует из полученных результатов, для всех переменных значения медиан лежат чуть выше средних, что наводит на мысль о левосторонней асимметричности их распределений.
Мода – наиболее вероятное значение случайной величины.
Эксцесс характеризует остроконечность (положительные значения) или пологость (отрицательные значения) распределения по сравнению с нормальной кривой.
Асимметричность (коэффициент асимметрии или скоса - s) характеризует смещение распределения относительно математического ожидания. В частности в данном случае распределение всех переменных скошено влево, т.е. его более длинная часть лежит левее центра (мат. ожидания). Асимметрию распределений переменных V, P, Q можно считать несущественной, чего нельзя сказать о распределении NCF и NPV.
Осуществим оценку значимости коэф-та асимметрии и эксцесса для NPV.
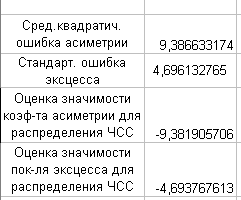
рис. 15 Показатели
По результатам расчета асимметрию следует считать существенной. Таким образом, наше первоначальное предположение о левосторонней скошенности распределения NPV подтвердилось. Величиной эксцесса нельзя пренебречь, так как его следует считать существенным.
Уровень надежности показывает величину доверительного интервала для математического ожидания согласно заданному уровню надежности или доверия. Для рассматриваемой задачи это означает, что с вероятностью 95% величина математического ожидания NPV попадет в интервал 2793,899 34,171.
ЗАДАЧА 1. Осуществить имитационное моделирование рисков инвестиционного проекта по исходным данным, приведенным в табл.1 Приложения — с помощью встроенных функций Excel и путем использования инструмента «Анализ данных» этой же программы.
В задаче необходимо выполнить следующее:
Сформировать шаблон № 1 в соответствии с образцом, приведенным на рис.1, 2 и табл. 6–9.
Ввести значения постоянных величин в соответствующие ячейки листа «Результаты анализа».
Ввести значения диапазонов изменений ключевых переменных в соответствующие ячейки листа «Имитация».
Задать требуемое число экспериментов.
Установить курсор в ячейку А11 и вставить необходимое число строк в шаблон (номер последней строки будет вычислен в Е7).
Скопировать формулы блока А10.Е10 требуемое количество раз.
Перейти к листу «Результаты анализа» и проанализировать полученные результаты.
Построить графики V, P, Q, NCF и NPV.
Сформировать элементы оформления листа «Имитация», определить необходимые имена для блоков ячеек и задать требуемые формулы шаблона № 2 в соответствии с образцом, приведенным на рис.10, 11 и табл. 11–13
Ввести исходные значения постоянных величин в ячейки листа «Результаты анализа». Перейти к листу «Имитация». Ввести значения ключевых переменных и соответствующие вероятности.
Установить курсор в ячейку А13 и приступить к проведению имитационного эксперимента согласно описанной в разделе 4.1.4.2 последованости действий.
Произвести анализ полученных результатов моделирования.
Произвести статистический анализ имитационной модели:
с помощью инструмента анализа данных «Корреляция» определить степень тесноты взаимосвязей между переменнымиV, P, Q, NCF и NPV и проанализировать полученные результаты;
с помощью инструмента анализа данных «Описательная статистика» определить параметры описательной статистики для переменных V, P, Q, NCF и NPV и проанализировать полученные результаты;
произвести оценку значимости коэффициента асимметрии и эксцесса для распределения NPV.