

Сортировка и поиск
Алгоритмы поиска занимают важное место в прикладных алгоритмах. Обычно данные хранятся в определенном образом упорядоченном наборе.
Основная задача поиска — найти элемент, удовлетворяющий некоторым условиям.
Классификация алгоритмов поиска. Все методы можно разделить на статические и динамические. При статическом поиске массив значений не меняется во время работы алгоритма. Во время динамического поиска массив может перестраиваться или изменять размерность.
Примером статического поиска будет поиск слова в словаре. При этом словарь (массив слов) не будет изменяться во время поиска. Примером динамического поиска может служить попытка найти определенную карту в колоде. Откладывая в сторону ненужные карты, Вы облегчаете себе задачу поиска, уменьшая количества оставшихся карт в колоде, которые еще нужно перебрать, тем самым перестраивая массив значений во время поиска.
Также методы поиска можно разделить на методы, использующие истинные ключи и на методы, работающие по преобразованным ключам. В данном случае ключом называют то значение, которое мы ищем.
Поиск в колоде карт – поиск по истинным ключам, то есть имеете дело с тем, что есть. Поиск в словаре – поиск по преобразованным ключам, так как все слова отсортированы в алфавитном порядке, то есть массив значений изменен перед началом поиска. Этот порядок создан специально для облегчения поиска и вовсе не является естественным для списка слов.
Третий вариант классификации – методы основанные на сравнении самих значений и методы, основанные на их цифровых свойствах. Так называемые методы хэширования.
Под сортировкой понимают процесс перестановки объектов данного множества в определенном порядке.
Цель сортировки — облегчить последующий поиск элементов в отсортированном множестве. Следовательно, методы сортировки важны особенно при обработке данных.
Зависимость выбора алгоритма от структуры данных — явление довольно
частое, и в случае сортировки она настолько сильна, что методы сортировки обычно разделяют на две категории: сортировка массивов (внутренняя сортировка) и сортировка файлов (внешняя сортировка). Массивы обычно располагаются в оперативной памяти, для которой характерен быстрый произвольный доступ; файлы хранятся в более медленной, но более вместительной внешней памяти, на дисках.
Алгоритмы сортировки массивов можно разбить на три класса:
1) сортировка включениями;
2) сортировка выбором;
3) сортировка обменом.
Типы программных данных
Тип данных – определяет множество значений, набор операций, которые можно применять к таким значениям и способ реализации хранения значений и выполнения операций. Любые данные, которыми оперируют программы, относятся к определённым типам.
Процесс проверки и накладывания ограничений на типы используемых данных называется контролем типов или типизацией программных данных. Различают следующие виды типизации:
Статическая типизация — контроль типов осуществляется при компиляции.
Динамическая типизация — контроль типов осуществляется во время выполнения.
Контроль типов также может быть строгим и слабым.
Строгая типизация — совместимость типов автоматически контролируется транслятором:
Номинативная типизация — совместимость должна быть явно указана (наследована) при определении типа.
Структурная типизация (англ. structural type system) — совместимость определяется структурой самого типа (типами элементов, из которых построен составной тип).
Слабая типизация — совместимость типов никак транслятором не контролируется. В языках со слабой типизацией обычно используется подход, когда совместимость определяется и реализуется общим интерфейсом доступа к данным типа.
Типы данных бывают следующие:
Простые.
Перечислимый тип. Может хранить только те значения, которые прямо указаны в его описании.
Числовые. Хранятся числа. Могут применяться обычные арифметические операции.
Целочисленные: со знаком, то есть могут принимать как положительные, так и отрицательные значения; и без знака, то есть могут принимать только неотрицательные значения.
Вещественные: с запятой (то есть хранятся знак и цифры целой и дробной частей) и с плавающей запятой (то есть число приводится к виду m*be, где m — мантисса, b — основание показательной функции, e — показатель степени (порядок), причём в нормированной форме 1<=m<b, e – целое число и хранятся знак и числа m и e).
Символьный тип. Хранит один символ. Могут использоваться различные кодировки.
Логический тип. Имеет два значения: истина и ложь. Могут применяться логические операции. Используется в операторах ветвления и циклах. В некоторых языках является подтипом числового типа, при этом ложь=0, истина=1.
Множество. В основном совпадает с обычным математическим понятием множества. Допустимы стандартные операции с множествами и проверка на принадлежность элемента множеству. В некоторых языках рассматривается как составной тип.
Составные (сложные).
Массив. Является индексированным набором элементов одного типа. Одномерный массив — вектор, двумерный массив — матрица.
Строковый тип. Хранит строку символов. Аналогом сложения в строковой алгебре является конкатенация (прибавление одной строки в конец другой строки). В языках, близких к бинарному представлению данных, чаще рассматривается как массив символов, в языках более высокой абстракции зачастую выделяется в качестве простого.
Структура. Набор различных элементов (полей записи), хранимый как единое целое. Возможен доступ к отдельным полям записи. Например, struct в C.
Файловый тип. Хранит только однотипные значения, доступ к которым осуществляется только последовательно (файл с произвольным доступом, включённый в некоторые системы программирования, фактически является неявным массивом).
Класс.
Другие типы данных. Такие типы данных представляют объекты компьютерного мира, то есть являются исключительно компьютерными терминами.
Указатель. Хранит адрес в памяти компьютера, указывающий на какую-либо информацию, как правило — указатель на переменную.
Ссылка.
Все данные можно разделить на статические и динамические.
Статическими данными называются такие, память под которые выделяется во время компиляции и сохраняется в течение всей работы программы.
Для динамических данных память распределяется в процессе выполнения программы. Использование динамических данных дает следующие преимущества
позволяет увеличить объем обрабатываемых данных;
если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации;
использование динамической памяти позволяет создавать структуры данных переменного размера.
Объединение простых данных в составные (структуры, классы) называется структуризацией данных. Структуризация данных позволяет упростить процесс программирования за счет применения средств и методов, разработанных непосредственно для работы с данными определенной структуры или класса.
Наиболее часто используемыми сложными структурами данных являются
стек
список
очередь
дерево
сеть
Стек (англ. stack — стопка) – структура данных с методом доступа к элементам LIFO (англ. Last In – First Out, «последним пришел — первым вышел»). Чаще всего принцип работы стека сравнивают со стопкой тарелок: чтобы взять вторую сверху, нужно снять верхнюю. Добавление элемента, называемое также проталкиванием (push), возможно только в вершину стека (добавленный элемент становится первым сверху). Удаление элемента, называемое также выталкивание (pop), возможно также только из вершины стека, при этом, второй сверху элемент становится верхним.
Список – это структура данных, состоящая из элементов одного типа, связанных между собой.
Различают
однонаправленный список (каждый элемент списка имеет указатель на следующий за ним элемент, другими словами – хранит информацию о расположении следующего элемента, кроме того есть переменная, указывающая на первый элемент списка);
двунаправленный список (каждый элемент списка имеет указатель на следующий за ним элемент и указатель и на предшествующий элемент, кроме того есть переменная, указывающая на первый элемент списка);
циклический список (последний элемент списка содержит указатель, связывающий его с первым элементом).
Для реализации списка необходима реализация следующих методов:
помещение элемента в конец списка;
получение данных о элементе списка;
перемещение по элементам списка;
удаление элемента из списка.
Очередь – структура данных с дисциплиной доступа к элементам «первый пришёл – первый вышел» (FIFO, First In – First Out). Добавление элемента (принято обозначать словом enqueue – поставить в очередь) возможно лишь в конец очереди, выборка – только из начала очереди (что принято называть словом dequeue – убрать из очереди), при этом выбранный элемент из очереди удаляется.
Дерево – это связный граф (граф, между любой парой вершин которого существует по крайней мере один путь), не содержащий циклов. В дереве существует только по одному пути между парами вершин.
Граф – совокупность объектов со связями между ними.
Пример дерева
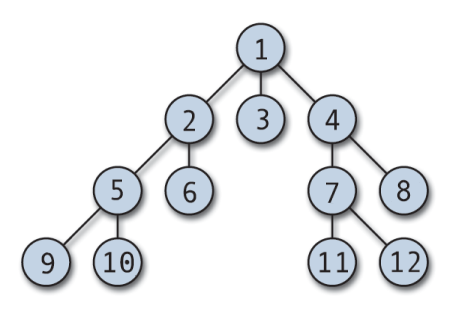
С понятием дерева связываются следующие определения
Узел – объект, над которым осуществляется обратотка.
Вершина (корень) – конечная цель, требующая решения.
Степень узла – количество исходящих дуг.
Концевой узел (лист) — узел со степенью 1.
Узел ветвления — неконцевой узел.
Уровень узла — длина пути от корня до узла.
Остовное дерево (остов) — это подграф данного графа, содержащий все его вершины и являющийся деревом. Рёбра графа, не входящие в остов, называются хордами графа относительно остова.
Сеть – структура данных, подобная иерархической (дерево), но отличающаяся от нее тем, что каждая запись может вступать в любое количество поименованных связей с другими записями как исходная или порожденная, или как то и другое.