

Применение в биологии
В биологии кластеризация имеет множество приложений в самых разных областях. Например, в биоинформатике с помощью нее анализируются сложные сети взаимодействующих генов, состоящие порой из сотен или даже тысяч элементов. Кластерный анализ позволяет выделить подсети, узкие места, концентраторы и другие скрытые свойства изучаемой системы, что позволяет в конечном счете узнать вклад каждого гена в формирование изучаемого феномена.
В социологии в информатике
Группирование результатов поиска: Кластеризация используется для «интеллектуального» группирования результатов при поиске файлов, веб-сайтов, других объектов, предоставляя пользователю возможность быстрой навигации, выбора заведомо более релевантного подмножества и исключения заведомо менее релевантного — что может повысить юзабилити интерфейса по сравнению с выводом в виде простого сортированного по релевантности списка.
Clusty[1] — кластеризующая поисковая машина компании Vivísimo
Nigma — российская поисковая система с автоматической кластеризацией результатов
Quintura — визуальная кластеризация в виде облака ключевых слов
Сегментация изображений (image segmentation): Кластеризация может быть использована для разбиения цифрового изображения на отдельные области с целью обнаружения границ (edge detection) или распознавания объектов.
Интеллектуальный анализ данных (data mining): Кластеризация в Data Mining приобретает ценность тогда, когда она выступает одним из этапов анализа данных, построения законченного аналитического решения. Аналитику часто легче выделить группы схожих объектов, изучить их особенности и построить для каждой группы отдельную модель, чем создавать одну общую модель для всех данных. Таким приемом постоянно пользуются в маркетинге, выделяя группы клиентов, покупателей, товаров и разрабатывая для каждой из них отдельную стратегию.
Метод обработки пространственно-временных совокупностей
Методы обработки временных, пространственных и пространственно-временных совокупностей
Эти методы занимают ведущее место с точки зрения формализованного прогнозирования и существенно варьируют по сложности используемых алгоритмов. Выбор того или иного метода зависит от множества факторов, в том числе и от имеющихся в наличии исходных данных. Как видно из названия раздела, по этому параметру можно выделить три типовые ситуации.
Первая ситуация - наличие временного ряда - встречается на практике наиболее часто: финансовый менеджер или аналитик имеет в своем распоряжении данные о динамике показателя, на основании которых требуется построить приемлемый прогноз. Иными словами, речь идет о выделении тренда. Это можно сделать различными способами; упомянем о двух:
простом динамическом анализе,
анализе при помощи авторегрессионных зависимостей.
Первый способ базируется на предпосылке, что прогнозируемый показатель (Y) изменяется прямо (обратно) пропорционально с течением времени. Поэтому для определения прогнозных значений показателя Y строится, например, следующая зависимость:
![]()
(2.1)
где t -- порядковый номер периода.
Параметры уравнения регрессии (а, Ь) находят, как правило, методом наименьших квадратов. Подставляя в формулу нужное значение t, рассчитывают требуемый прогноз.
Пример. На рис. 2.1 изображен тренд финансового показателя, построенный по статистическим данным. Он задается формулой:
У = -529 + 0.275t
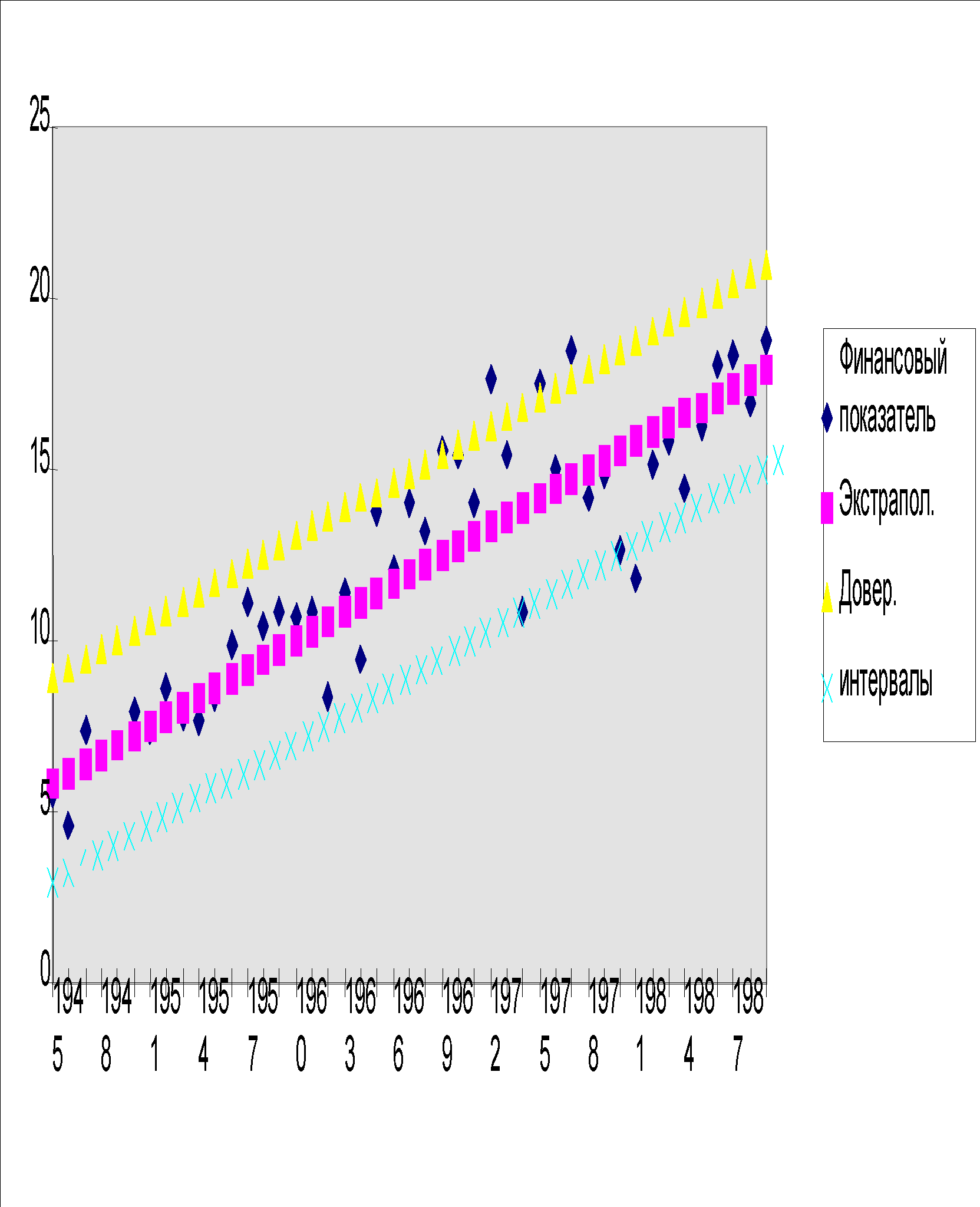
Рис2.2. Экстраполяция финансового показателя по формуле У = -529 + 0.275t с указанием верхней и нижней границ доверительного интервала.
В основу второго способа заложена достаточно очевидная предпосылка, что экономические процессы имеют определенную специфику. Они отличаются, во-первых, взаимозависимостью и, во-вторых, определенной инерционностью. Последнее свидетельствует, что значение практически любого экономического показателя в момент t определенным образом зависит от состояния этого показателя в предыдущих периодах (в данном случае мы абстрагируемся от влияния других факторов), т.е. значения прогнозируемого показателя в прошлых периодах должны рассматриваться как факторные признаки. Уравнение авторегрессионной зависимости в наиболее общей форме имеет вид
![]()
(2.2)
где Yt - прогнозируемое значение показателя Y в момент t;
Yt-1- значение показателя Y в момент (t-1);
Aj - j-й коэффициент регрессии.
Достаточно точные прогнозные значения можно получить уже при k= 1.
На практике также нередко используют модификацию приведенного уравнения, вводя в него в качестве фактора период (момент) t. В этом случае уравнение регрессии будет иметь вид
![]()
(2.3)
Коэффициенты регрессии данного уравнения можно найти методом наименьших квадратов. Соответствующая система нормальных уравнений будет иметь вид
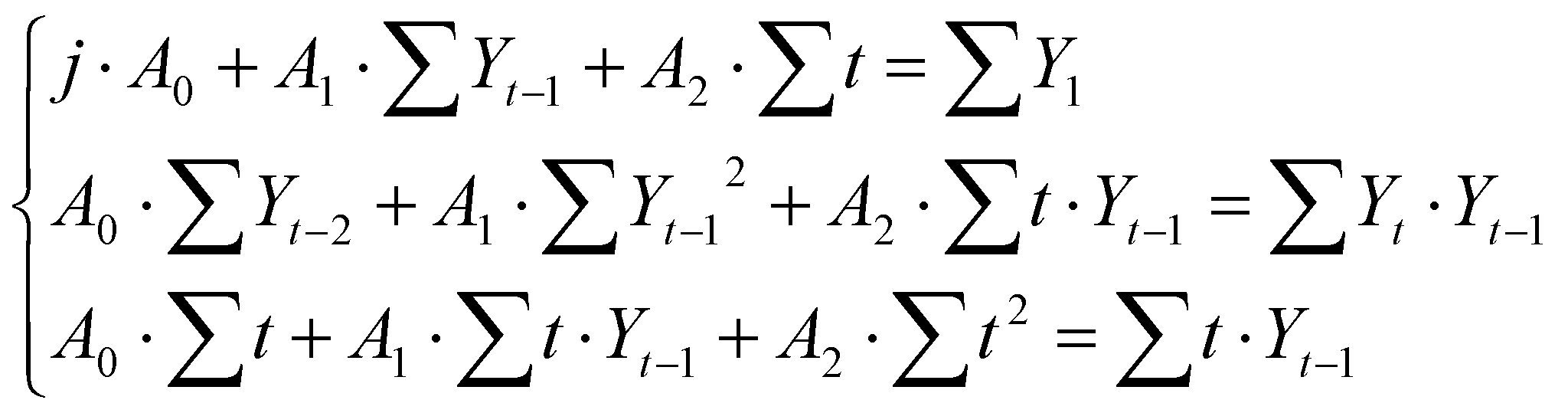
(2.4)
где j - длина ряда динамики показателя Y, уменьшенная на единицу.
Пример. Используя аппарат авторегрессионных зависимостей. построить уравнение регрессии для прогнозирования объема реализации на основании данных о динамике этого показателя (тыс.руб) 17, 16, 21, 24, 23, 26, 28.
Решение. Уравнение регрессии будем строить в виде уравнения (2.3). Промежуточные данные для построения системы нормальных уравнений представлены в Таблице 2.1.
Yt-1 |
t |
Yt |
Yt-12 |
t2 |
t*Yt-1 |
t*Yt |
Yt * Yt-1 |
Yi |
17 16 21 24 23 26 |
1 2 3 4 5 6 |
16 21 24 23 26 28 |
289 256 441 576 529 676 |
1 4 9 16 25 36 |
17 32 63 96 115 156 |
16 42 72 92 130 168 |
272 336 504 552 598 728 |
17.5 20.8 21.6 23.3 26.6 28.2 |
127 |
21 |
138 |
2767 |
91 |
479 |
520 |
2990 |
- |
В последней строке таблицы стоят суммы по соответствующему столбцу.
Система нормальных уравнений в соответствии с (2.4) имеет вид:
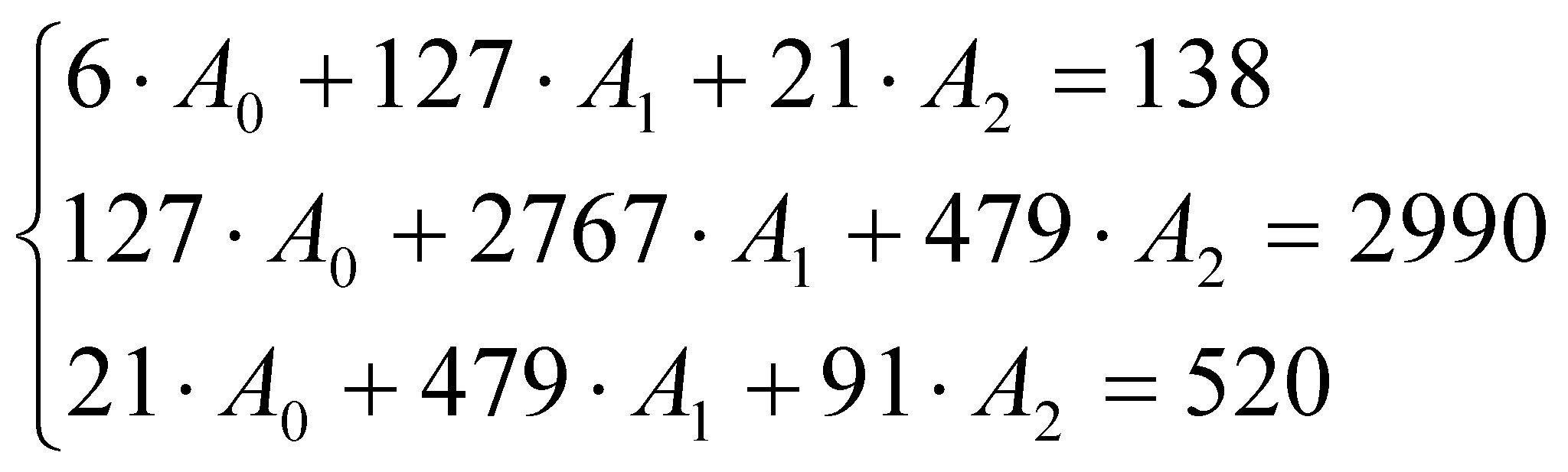
Из решения этой системы уравнений получаем уравнение регрессии:
![]()
Вторая ситуация - наличие пространственной совокупности - имеет место в том случае, когда по некоторым причинам статистические данные о показателе отсутствуют либо есть основание полагать, что его значение определяется влиянием некоторых факторов. В этой ситуации может применяться многофакторный регрессионный анализ, представляющий собой распространение простого динамического анализа на многомерный случай. При этом в результате качественного анализа выделяется k факторов (X1, X2, … Xk), влияющих, по мнению аналитика, на изменение прогнозируемого показателя (Y). Строится чаще всего линейная регрессионная зависимость типа:
![]()
(2.5)
где Aj- коэффициенты регрессии, j =1,2,...,k.
Расчетная таблица для определения параметров уравнения регрессии методом наименьших квадратов может иметь такой вид:
Прибыль тыс. руб. Y |
Затраты на 1 руб. произведенной продукции, тыс.руб X1 |
Стоимость основных фондов. тыс.руб X2 |
X12 |
X1X2 |
X1Y |
X22 |
X2Y |
221 1070 1001 606 779 789
|
96 77 77 89 82 81 |
4,3 5,9 5,9 3,9 4,3 4,9
|
48 841 1 144 900 1 002 000 367 236 606 841 622 520 |
412,8 454,3 454,3 347,1 352,6 396,9 |
21 216 82 390 77 077 53 934 63 878 63 909 |
18,49 34,81 34,81 15,21 18,49 24,01 |
950,3 6313,0 5905,9 2363,4 3349,7 3866,1 |
4466 |
502 |
29,2 |
3 792 338 |
2418 |
362404 |
145,82 |
22748,4 |
Третья ситуация - наличие пространственно-временной совокупности - имеет место в том случае, когда:
а) ряды динамики недостаточны по своей длине для построения статистически значимых прогнозов;
б) аналитик намерен учесть в прогнозе влияние факторов, различающихся по экономической природе, и их динамики.
Исходными данными служат матрицы показателей, каждая из которых представляет собой значения тех же показателей за различные периоды или на разные последовательные даты. Методы обработки таких совокупностей хорошо описаны в отечественной литературе и включают, в частности, осреднение параметров одногодичных уравнений регрессии, метод заводо-лет и ковариационный анализ.