

5. Внутренняя структура записи
Логическая запись состоит из отдельных элементов, связанных определенными отношениями, и имеет многоуровневую структуру. Элементами первого, самого нижнего, уровня являются элементарные данные: числа, символы, логические данные, знаки. Элементарные данные читаются программой целиком, доступ к их частям невозможен. Эти данные не являются непосредственным объектом информационного поиска, но в ряде случаев к ним должен быть обеспечен доступ. Так, например, в процессе поиска может возникнуть необходимость сравнения отдельных символов.
Элементарные данные каждого типа имеют определенную форму представления в ОП, для их хранения выделяется строго определенный объем памяти. Знание форматов хранения элементарных данных позволяет рассчитать объем памяти, необходимый для размещения массивов данных и программ.
Элементом второго уровня является поле записи. Это последовательность элементарных данных, имеющая определенный смысл, но не имеющая смысловой завершенности. Данные, образующие отдельное поле записи, описывают соответствующий признак объекта.
Каждый признак объекта имеет наименование и значение. Так, например, для студентов, записи о которых хранятся в АИС, в качестве признаков могут использоваться номер студенческого билета, фамилия, средний балл успеваемости. Число признаков, характеризующих объект, определяет количество полей в записи. В каждом поле помещается значение соответствующего признака. Используемый для идентификации записи в процессе обработки или поиска признак называется ключевым или ключом записи. Поле записи, содержащее ключ, называется ключевым полем. Если каждое из возможных значений ключа идентифицирует единственную запись, то такой ключ называют уникальным.
Поля записи объединяются в группу данных (агрегат данных, групповое данное). Группа данных — элемент третьего уровня внутренней структуры записи — представляет собой поименованную совокупность элементов данных, рассматриваемую как единое целое. Например, группа данных, имеющая наименование АДРЕС, состоит из элементов данных ГОРОД, УЛИЦА, НОМЕР ДОМА, НОМЕР КВАРТИРЫ. Логическая запись — это поименованная совокупность полей или групп данных. Запись является отдельной логической единицей и имеет смысловую завершенность. Каждая запись описывает индивидуальный объект или класс объектов. Логическая запись является непосредственным предметом информационного поиска, основной единицей обработки информации.
Перечень полей, последовательность их расположения и взаимосвязь между ними составляют внутреннюю структуру записи, которая в конечном итоге определяет тип записи.
6. Типы структур данных
В процессе функционирования АИС записи и массивы претерпевают изменения. В массивы добавляются новые записи и удаляются ставшие ненужными. Процесс поддержания информационного массива в актуальном состоянии, заключающийся в добавлении (включении) и удалении (исключении) записей, называется ведением. Процесс внесения изменений в записи называют корректировкой или модификацией.
Структуры данных делятся на линейные и нелинейные структуры. В нелинейных структурах в отличие от линейных связь между элементами структуры (записями) определяется отношениями подчинения или
какими-либо логическими условиями. К линейным структурам данных относятся массив, стек, очередь, таблица. К нелинейным структурам принадлежат деревья, графы, многосвязные списки и списковые структуры.
Ряд структур данных после создания не позволяет включать или исключать записи, а допускает лишь их корректировку. Это структуры фиксированного размера. Структуры переменного размера позволяют включать и исключать записи, предоставляя информационному массиву возможность динамически изменяться. В первом случае необходимо заранее знать число элементов структуры и выделять блок памяти под максимальный размер информационного массива. При связанном представлении структуры переменного размера могут свободно расти и уменьшаться. Различные структуры данных предоставляют и различный доступ к своим элементам: в одних структурах доступ возможен к любому элементу, в других — к строго определенному. Ограничение в доступе сопровождается увеличением времени поиска нужных записей.
Структуры данных могут быть однородными и неоднородными. В однородных структурах все элементы представлены записями одного типа. В неоднородных структурах элементами одной структуры могут являться записи разных типов.
7. ПОСЛЕДОВАТЕЛЬНОЕ ПРЕДСТАВЛЕНИЕ ДАННЫХ В ПАМЯТИ ЭВМ.
При последовательном представлении данные в памяти машины размещаются в соседних последовательно расположенных ячейках. При этом физический порядок следования записей полностью соответствует логическому порядку, определяемому логической структурой, т.е. логическая структура поддерживается физическим порядком следования данных. Совокупность записей, размещенных в последовательно расположенных ячейках памяти, называют последовательным списком. Для хранения информационного массива в виде последовательного списка в памяти выделяется блок свободных ячеек под максимальный размер массива. Записи, имеющие следующий логический порядок: Зап. В, Зап. А, Зап. F, Зап. С, ..., Зап. N, — разместятся в памяти машины так, как это показано на рис. 7.1,а.
В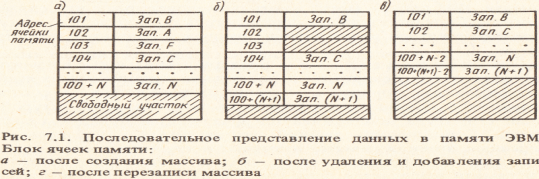 новь
появившиеся записи размещаются в
конце блока на свободном участке памяти.
Если количество новых записей окажется
больше, чем число свободных ячеек в
зарезервированном блоке, то эти
записи не удастся разместить в памяти.
Если же записей окажется меньше, чем
предполагалось, то память останется
неиспользованной.
новь
появившиеся записи размещаются в
конце блока на свободном участке памяти.
Если количество новых записей окажется
больше, чем число свободных ячеек в
зарезервированном блоке, то эти
записи не удастся разместить в памяти.
Если же записей окажется меньше, чем
предполагалось, то память останется
неиспользованной.
В процессе ведения информационного массива записи добавляются и удаляются. Вновь пришедшие записи добавляются в конец списка. Так, запись (N+ 1)-я будет размещена в ячейке с адресом 100 + (N+ 1). При удалении записей в памяти остаются свободные ячейки. На рис. 7.1,б добавлена запись (N +1) -я и удалены две записи: Зап. А и Зап. F. Ячейки 102 и 103 оказались свободными. Список, в котором содержатся свободные ячейки памяти, будет неплотным» Со временем значительное число ячеек может оказаться свободным. Для того чтобы эти участки памяти не пустовали, время от времени весь массив данных перезаписывается, при этом все записи передвигаются так, как это показано на рис. 7.1,в. Перезапись массива требует дополнительных затрат машинного времени.
8. СВЯЗАННОЕ ПРЕДСТАВЛЕНИЯ ДАННЫХ В ПАМЯТИ ЭВМ
При связанном представлении в каждой записи предусматривается дополнительное поле, в котором размещается указатель (ссылка) Физический порядок следования записей в этом случае может не соответствовать логическому порядку. В машинной памяти записи располагаются в любых свободных ячейках и связываются между собой указателями, указывающими на место расположения записи, логически следующей за данной записью. Указатель часто интерпретируют как адрес ячейки памяти, в которой хранится следующая запись.
С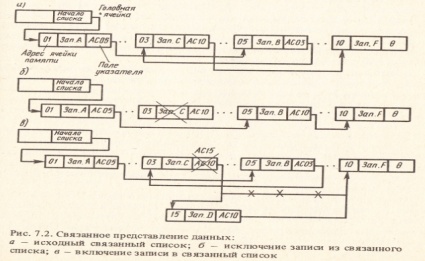 труктуры
хранения, основанные на связанном
представлении данных, называют
связанными
списками. Если
каждая запись содержит лишь один
указатель, то список односвязный,
при
большем числе указателей список
многосвязный.
труктуры
хранения, основанные на связанном
представлении данных, называют
связанными
списками. Если
каждая запись содержит лишь один
указатель, то список односвязный,
при
большем числе указателей список
многосвязный.
Пусть структура данных отображает следующую логическую последовательность записей: Зап. А, Зап. Д Зап. С, Зап. F. Записи размещены в ячейках памяти с адресами 01, 03, 05, 10. В поле указателя каждой записи размещается адрес связи (АС), определяющий адрес ячейки с логически следующей записью. Структура хранения массива представлена на рис. 7.2,а. На рисунке стрелками показан порядок чтения записей.
Одна из ячеек - головная - содержит указатель на ячейку с первой записью списка. В соответствии с указателями первым будет прочитано содержимое ячейки 01 (Зап. А), затем содержимое ячеек 05 (Зап В) 03 (Зап. С), 10 (Зап. F). Символ 0, помещенный в поле указателя последней записи списка, означает конец списка. Вместо символа © может быть использован любой другой элемент данных, который не воспримется системой как указатель.
1) Исключим из списка (рис. 7.2,а) запись С, хранящуюся в ячейке с адресом 03 и имеющую адрес связи АС 10. Для этого значение указателя предшествующей записи (Зап. В) изменим на АС 10. Теперь доступ к записи С стал невозможен и запись С оказалась исключенной из списка (рис. 7.2,6) . Освободившаяся ячейка с помощью указателей включается в связанный список свободных ячеек.
2) На рис. 7.2,в изображен связанный список с вновь включенной записью Д логически следующей за записью С. Запись D размещается в ячейке с адресом 15. После замены указателей устанавливается порядок чтения ячеек памяти 01, 05, 03, 15, 10, обеспечивающий логическую последовательность записей: Зап. Л, Зап._9, Зап. С, Зап. Д Зап. F.
Односвязный
список можно организовать в виде
замкнутого кольца
(рис.
7.3). В этом случае указателем последней
записи будет адрес первой. Такой
список называют еще циклическим.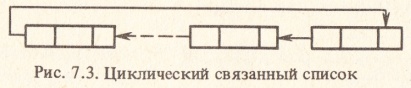
Связанное представление данных используется для хранения нелинейных структур данных, а также для реализации линейных структур в тех случаях, когда заранее не известен предельный размер информационного массива.
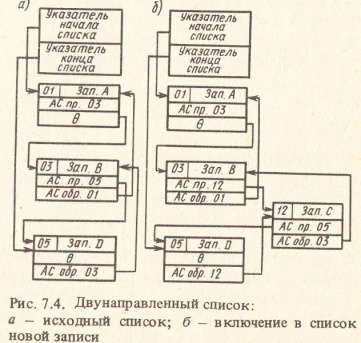
В ряде задач необходимо иметь возможность продвижения по связанному списку в обоих направлениях. Для этого в каждый элемент списка вводится дополнительный указатель, задающий продвижение по списку в обратном направлении. Такой список называется двунаправленным. В поле указателя заносится адрес ячейки с записью, логически предшествующей данной записи (рис. 7.4,а). Головная ячейка содержит в этом случае указатели на первую и последнюю ячейки списка. Поиск в двунаправленном списке возможен как с начала, так и с конца списка. В процессе добавления (удаления) записи в двусвязный список происходит изменение прямых и обратных указателей так, как это показано на рис. 7.4, б. Наличие обратного указателя позволяет упростить алгоритм изменения указателей, так как обратный указатель удаляемой записи хранит адрес ячейки с логически предшествующей записью. В односвязном списке этот адрес необходимо определять с помощью дополнительных процедур.

Для реализации связанного представления данных язык программирования должен располагать определенными средствами, а именно иметь данные типа "указатель". При работе с языками программирования, не имеющими данных типа "указатель", связанное представление моделируется с помощью структуры массива. Пусть структура данных определена как массив М(I). Для определения порядка чтения элементов массива, не совпадающего с физическим порядком их следования, можно организовать вспомогательный вектор указателей N(J), элементы которого - целые числа — определяют порядковые номера (индексы) записей основного массива. На рис. 7.5 изображены два одномерных массива: массив указателей N(J ) и основной массив записей М(I), а также моделируемый список. Процедура чтения основного массива организуется с учетом того, что I = N(J). Таким образом, вектор N(J) при изменении значения J от 1 до 4 задает следующий порядок чтения записей основного массива: Зап. А, Зап. В, Зап. С, Зап. D.