

4. Распределенная обработка данных
4.1. Режимы работы с базой данных
В зависимости от характера решаемых задач, обрабатываемой информации, используемой СУБД, работа с базами данных может быть организована различными способами (рис. 7):
Режим работы с БД
Многопользовательский
Последовательный
С централизованной БД
С распределенной БДПараллельный


Однопользовательский
Рис. 7. Режимы работы с базами данных [ 4 ]
Если с базой данных, размещенной на автономном или входящем в состав локальной вычислительной сети компьютере, в течение одного или нескольких сеансов работает только один человек, такой режим называется однопользовательским (монопольным).
В рамках последовательного многопользовательского режима к базе данных имеют доступ несколько человек, которые сменяют друг друга в процессе работы.
Параллельные режимы работы с базой данных предполагают, что с одной и той же базой данных одновременно работают несколько пользователей.
Несмотря на очевидную простоту рассмотренных понятий, студенты часто неправильно их интерпретируют, полагая, что сам факт одновременного выполнения заданий с помощью СУБД MS Access во время лабораторных занятий на компьютерах, включенных в локальную вычислительную сеть, обеспечивает параллельный режим работы. При этом забывается, что каждый пользователь работает со своей локальной базой данных, сохраняемой под уникальным именем.
Для обеспечения надежной и качественной работы с базой данных в монопольном и последовательном многопользовательском режимах обычно не требуются сложные специальные методы и технологии. Необходимый результат может быть достигнут с помощью простых организационных мер: регламентации действий и ограничения полномочий отдельных пользователей, внедрения детально разработанных инструкций о характере и последовательности выполняемых действий и т. д.
Монопольный и последовательный многопользовательский режимы в основном применяются для работы с небольшими, локальными базами данных (учет поступления товаров в отдельный магазин, решение несложной научно-исследовательской задачи и т. д.). Если база данных предназначена для обеспечения деятельности даже небольших организаций, фирм, учреждений, с высокой степенью вероятности можно ожидать, что она будет эксплуатироваться в параллельном режиме.
Для понимания особенностей параллельного режима работы с базой данных предварительно рассмотрим фундаментальные понятия клиент и сервер.
4.2. Архитектура «клиент-сервер»
Термины «клиент» и «сервер» изначально применялись для архитектуры программного обеспечения, которое можно было разделить на два вычислительных процесса. Клиентский процесс запрашивает некоторые услуги у сервера, серверный процесс предоставляет эти услуги клиенту. Один сервер может обслуживать несколько клиентов.
В дальнейшем, в связи с развитием вычислительных сетей, возникла возможность распределения указанных задач между отдельными компьютерами. Поэтому в настоящее время под клиентом и сервером обычно понимают разные компьютеры, выполняющие эти задачи. По мнению К. Дж. Дейта, такое понимание терминов «клиент» и «сервер» является небрежным, но очень распространенным [ 2 ].
С позиций теории баз данных сервер – это собственно СУБД. Сервер обеспечивает хранение и обработку данных, их защиту и целостность и т.д.
Клиенты представляют собой различные приложения, выполняемые «над» СУБД. Они могут быть написаны непосредственно пользователями в процессе работы с базой данных на одном из языков программирования (С++, Pascal и т.д.) или являться встроенными приложениями, поставляемыми производителями СУБД или другими организациями (процессоры языков запросов, генераторы отчетов и приложений, графические бизнес-системы и т. д.) [ 2 ].
Исходя из рассмотренных положений, архитектуру «клиент-сервер» можно представить в следующем общем виде [ 2 ]:
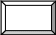
Пользователи
