

10. Цепочки символов. Понятие лексемы. Задачи лексического анализатора
Лексический анализатор читает цепочки символов, составляющих исходную программу, и группирует эти символы в значащие последовательности, называющиеся лексемами.
Лексема — это цепочка терминальных символов, с которой связывают лексическую структуру, состоящую из пары вида (тип лексемы, некоторые данные). Первой компонентой пары является синтаксическая категория, такая, как „константа" или „идентификатор", а вторая—указатель: в ней указывается адрес ячейки, хранящей информацию об этой конкретной лексеме. Для данного языка число типов лексем предполагается конечным. Пару (тип лексемы, указатель) тоже будем называть лексемой, когда это не будет вызывать недоразумений.
Основная задача лексического анализа - разбить входной текст, состоящий из последовательности одиночных символов, на последовательность слов, или лексем, т.е. выделить эти слова из непрерывной последовательности символов. Все символы входной последовательности с этой точки зрения разделяются на символы, принадлежащие каким-либо лексемам, и символы, разделяющие лексемы (разделители). В некоторых случаях между лексемами может и не быть разделителей.
Лексический анализатор выдает информацию двух сортов: для синтаксического анализатора, работающего вслед за лексическим, существенна информация о последовательности классов лексем, ограничителей и ключевых слов, а для контекстного анализа, работающего вслед за синтаксическим, важна информация о конкретных значениях отдельных лексем (идентификаторов, чисел и т.д.).
Таким образом, общая схема работы лексического анализатора:
Сначала выделяется отдельная лексема (возможно, используя символы-разделители). Ключевые слова распознаются либо явным выделением непосредственно из текста, либо сначала выделяется идентификатор, а затем делается проверка на принадлежность его множеству ключевых слов.
Если выделенная лексема является ограничителем, то он (точнее, некоторый его признак) выдается как результат лексического анализа. Если выделенная лексема является ключевым словом, то выдается признак соответствующего ключевого слова. Если выделенная лексема является идентификатором - выдается признак идентификатора, а сам идентификатор сохраняется отдельно. Наконец, если выделенная лексема принадлежит какому-либо из других классов лексем (например, лексема представляет собой число, строку и т.д.), то выдается признак соответствующего класса, а значение лексемы сохраняется отдельно.
11. Лексический анализ с помощью конечных автоматов
Конечный автомат — это устройство для распознавания строк какого-либо языка. У него есть конечное множество состояний, отдельные из которых называются последними. По мере считывания каждой литеры строки контроль передается от состояния к состоянию в соответствии с заданным множеством переходов. Если после считывания последней литеры строки автомат будет находиться в одном из последних состояний, о строке говорят, что она принадлежит языку, принимаемому автоматом. В ином случае строка не принадлежит языку, принимаемому автоматом.
Формально конечный автомат определяется пятью характеристиками:
1) конечным множеством состояний К;
2) конечным входным алфавитом Σ;
3) множеством переходов δ;
4) начальным состоянием S(SK);
5) множеством последних состояний F(FK).
Конечный автомат можно записать в виде пятерки M = (A,Σ, δ,S,F).
Рассмотрим следующий пример, где состояниями являются А и В, вход-ным алфавитом - {0,1}, начальным состоянием - А, множеством последних состояний - {А}, а переходами
δ (A,0)=A,
δ(A,1)=В,
δ(В,0)=В,
δ(В,1)=A.
Эти переходы означают, что «при чтении 0 в состоянии А управление передается в состояние А» и т. д.
При чтении строки
01001011
управление последовательно передается в следующем порядке через со стояния
A, А, В, В, В, А, А, В, А.
Так как А есть последнее состояние, строка принимается конечным автоматом. Однако при чтении строки
00111
автомат проходит через состояния
А, А, А, В, А, В
в таком порядке, и поскольку В не является последним состоянием, эта строка не принимается, т. е. она не принадлежит языку, принимаемому этим автоматом. В связи с тем что нули не влияют на состояние автомата, а каждая единица изменяет его состояние с A на В и с В на A, и начальное состояние является тем же, что и последнее состояние, язык, принимаемый автоматом, состоит из тех строк, которые содержат четное число единиц.
Переходы можно представить также с помощью таблицы (табл. 1) и схематически (рис. 1).
Таблица 1 Состояния
|
А |
В |
0 |
А |
В |
1 |
В |
А |
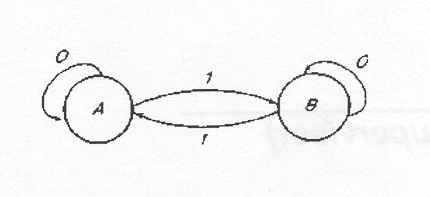
Рисунок 1
Такой автомат называют детерминированным, потому что в каждом элементе таблицы переходов содержится одно состояние. В недетерминированном конечном автомате это положение не выдерживается. Рассмотрим конечный автомат, определенный следующим образом:
M1=(K1,Σ1,δ1,S1,F1),
где K1={A,B}, Σ1={0,/}, S1={A}, F1={B}, а переходы представлены в табл. 2 или схематически на рис. 2. М, принимает строку тогда и только тогда, когда она начинается с единицы. Эта же строка не может быть принята, так как при чтении 0 не осуществляется переход с А.
Таблица 2 Состояния
|
А |
В |
0 |
|
{В} |
1 |
{A,В} |
{B} |
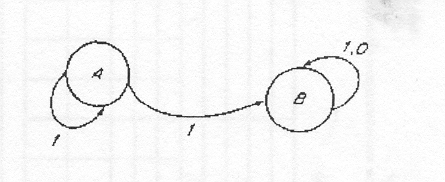
Рисунок 2
Строка 1 будет принята: здесь есть переход (в более общем случае последовательность переходов), ведущий к последнему состоянию при чтении строки. Имеется также переход к не последнему состоянию (от А к А), но это не влияет на приемлемость строки. Поэтому прежде чем прийти к выводу о том, что строка не может быть принята недетерминированным конечным автоматом, необходимо перепробовать все возможные последовательности переходов. С этой целью следует перебрать все возможности одну за другой или параллельно. Если в данный момент времени можно проходить только по одному пути (как обычно и бывает), то требуется возвратиться назад, т.е. необходимо перечитать всю строку или ее часть в процессе опробования другого пути. Очевидно, что эта процедура может оказаться весьма длительной. Существует детерминированный конечный автомат М2, соответствующий автомату М1, который принимает тот же язык,
M2=(K2,Σ2,δ2,S2,F2)
где K2 = {A,B,C}, Σ2={0, /}, S2 = {A},F2={B}, а переходы даны в табл. 3 и схематически на рис. 3.
Таблица 3
|
А |
В |
С |
0 |
С |
В |
С |
1 |
В |
В |
С |
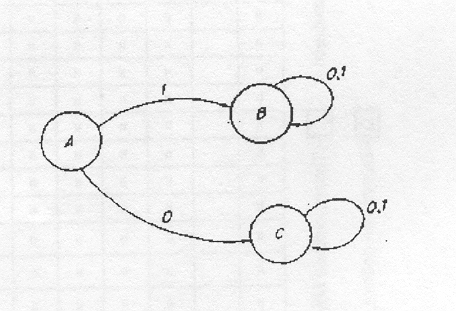
Рисунок 3
Как и M1, М2 принимает строку из нулей и единиц тогда и только тогда, когда строка начинается с единицы. Однако при распознавании строки с помощью М2 возврат никогда не требуется, так как в процессе чтения определенного входного символа из любого состояния произойдет точно один переход к другому состоянию. Это значит, что при использовании М2 время распознавания строки будет пропорционально ее длине.
Можно доказать, что каждому недетерминированному конечному автомату соответствует детерминированный конечный автомат, принимающий тот же язык. В доказательстве допускается, что состояние в детерминированном автомате соответствует подмножествам состояний недетерминированного автомата. Например, состояние В в М2 соответствует множеству состояний {А, В} в M1, а состояние С в М2 - , пустому множеству состояний в M1.
Соответствие лексическому анализу заключается в том, что каждому языку типа 3 соответствует детерминированный конечный автомат, который распознает строки этого языка. Например, строки, генерируемые грамматикой G1 с порождающими правилам
A->1A B->1B
A->1B B->0
A->1 B->1
B->0B
где А — начальный символ, распознаются с помощью М1 или М2. Грам-матику получают из недетерминированного конечного автомата M1, сле-дующим образом:
1. Начальное состояние автомата становится начальным символом предложения грамматики.
2. Переходам
δ (A, 1)=A,
δ (А, 1)=В,
δ(В, 0) = B,
δ(В,1)=В
соответствуют порождающие правила:
A->1A
A->1В
В->0В
B->1B
а тому, что в состоянии А есть переход при чтении 1 к последнему со-стоянию (В), соответствует
A->1
и аналогично
В->1
B->0
Можно также, наоборот, из грамматики вывести автомат M1. Авто-мат М2 соответствует грамматике G2 с порождающими правилами
A->1B B->0
A->0C B->1
A->1 C->0C
B->0B C->1C
B->1B
Рис. 4
которая содержит бесполезный нетерминал С, но эквивалентна G1. Грамматику G2 называют «нечистой», так как она включает нетерминал, не генерирующий никаких терминальных символов.