

1.4. Отслеживание состояний кэш-памяти
Все процессоры, применяемые в системах общего назначения, оснащаются кэш-памятью, которая позволяет согласовывать высокое быстродействие процессора с невысоким быстродействием памяти. Единица данных, передаваемая в кэш-память, называется строкой памяти и имеет достаточно большую длину – до 32 байтов или даже до 64 байтов. Чтение и запись такой строки производится обычно за несколько обращений к памяти, как правило, за 2-4 обращения. Естественно, что состояние кэш-памяти должно однозначно соответствовать состоянию основной памяти, т.е. кэш-память и основная память должны быть когерентны. Если при чтении данных из кэш-памяти происходит промах, то строка данных читается из основной памяти и одновременно загружается в кэш-память. Если при чтении данных слово находится в кэш-памяти, то слово передается в процессор. При записи слова и при промахе кэша, и при попадании в кэш новое слово записывается и в кэш-память и в основную память. За счет этого и обеспечивается когерентность кэш-памяти и основной памяти.
Естественно, что в параллельных системах, в первую очередь в мультипроцессорных, а также в пределах плат вычислительных модулей, содержащих 2, или более процессоров, мультикомпьютерных систем должны обеспечиваться правила когерентности кэширования данных, сохраняющие идентичность данных в кэш-памятях и основной памяти параллельной системы. Для этого используются различные правила обеспечения когерентности данных, которые будут описаны при изложении принципов
построения когерентных параллельных систем.
1.5. Классификация параллельных систем
 За
последние три десятилетия было построено
очень большое количество параллельных
систем – от коммерческих мультипроцессоров
Cray 1 до суперкомпьютеров
программы ASCI, способных
выполнять 100 TFLOPS=1014
FLOPS (операций с плавающей
точкой в секунду). Для классификации
параллельных систем используется
несколько различных способов. Мы
воспользуемся принципом классификации
Флинна, представленным на рис.1.11.
За
последние три десятилетия было построено
очень большое количество параллельных
систем – от коммерческих мультипроцессоров
Cray 1 до суперкомпьютеров
программы ASCI, способных
выполнять 100 TFLOPS=1014
FLOPS (операций с плавающей
точкой в секунду). Для классификации
параллельных систем используется
несколько различных способов. Мы
воспользуемся принципом классификации
Флинна, представленным на рис.1.11.
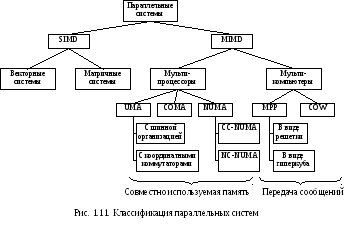
Параллельные системы разделяются на два класса: системы SIMD (Single Instruction stream Multiple Data stream один поток команд, несколько потоков данных) содержат один управляющий процессор, выдающий по одной команде, но при этом есть несколько арифметико-логический устройств, которые могут одновременно обрабатывать несколько наборов данных, и системы MIMD (Multiple Instruction stream Multiple Data stream несколько потоков команд, несколько потоков данных), в которых независимые процессоры работают как части большой системы.
Параллельные системы класса SIMD подразделяются на векторные системы, обрабатывающие наборы данных векторы и строки матриц, и матричные системы, способные выполнять операции над элементами матриц размерностью NxN, где N число арифметико-логических устройств в каждой строке матрицы. И в настоящее время векторные и матричные системы широко применяются для решения научных задач математического моделирования самых разных физических систем. Принципы построения этих систем подробно описаны, и мы сосредоточим снимание на параллельных системах класса MIMD.
Параллельные системы класса MIMD распадаются на мультипроцессоры (с памятью совместного использования) и мультикомпьютеры (системы с передачей сообщений).
Существует три типа мультипроцессоров. Они отличаются по способу реализации памяти совместного использования: системы UMA (Uniform Memory Access архитектура с однородным доступом к памяти), NUMA (Non Uniform Memory Access – архитектура с неоднородным доступом к памяти) и COMA (Cache Only Memory Access архитектура с доступом только к кэш-памяти). В машинах UMA каждый процессор имеет одно и тоже время доступа к любому модулю памяти. Иными словами, каждое слово памяти можно считать с той же скоростью, что и любое другое слово памяти. Если это технически невозможно, самые быстрые обращения замедляются, чтобы соответствовать самым медленным, поэтому программисты не увидят никакой разницы. Такая однородность делает производительность предсказуемой, а этот фактор очень важен для написания эффективных программ. Мультипроцессоры NUMA не обладают этим свойством. Обычно есть такой модуль памяти, который расположен близко к каждому процессору, и доступ к этому модулю памяти происходит гораздо быстрее, чем к другим. С точки зрения производительности очень важно, куда помещаются программа и данные. Машины COMA тоже с неоднородным доступом, но по другой причине. Подробнее каждый из этих трех типов мы рассмотрим позднее, когда будем изучать соответствующие категории.
Во вторую подкатегорию MIMD попадают мультикомпьютеры, которые в отличие от мультипроцессоров не имеют памяти совместного использования на архитектурном уровне. Другими словами, операционная система в процессоре мультикомпьютера не может получить доступ к памяти, относящейся к другому процессору, просто путем выполнения команды LOAD. Ему приходиться отправлять сообщение и ждать ответа. Именно способность операционной системы считывать слово из отдаленного модуля памяти с помощью команды LOAD отличает мультипроцессоры от мультикомпьютеров. Как мы уже говорили, даже в мультикомпьютере пользовательские программы могут обращаться к другим модулям памяти с помощью команд LOAD и STORE, но эту иллюзию создает операционная система, а не аппаратное обеспечение. Разница незначительна, но очень важна. Так как мультикомпьютеры не имеют прямого доступа к отдаленным модулям памяти, они иногда называются машинами NORMA (NO Remote Memory Access без доступа к отдаленным модулям памяти).
Мультикомпьютеры можно разделить на две категории. Первая категория содержит процессоры MPP (Massive Parallel Processors процессоры с массовым параллелизмом) – дорогостоящие суперкомпьютеры, которые состоят из большого количества процессоров, связанных высокоскоростной коммуникационной сетью. В качестве примеров можно назвать Cray T3E и IBM SP/2. Вторая категория мультикомпьютеров включает рабочие станции, которые связываются с помощью уже имеющейся технологии соединения. Эти примитивные машины называются NOW (Network Of Workstations сеть рабочих станций) и COW (Cluster Of Workstation кластер рабочих станций).
Самый нижний уровень подкатегорий, представленный на рис.1.11, будет рассмотрен в последующих разделах.
Алфавитный указатель
А
адаптивная маршрутизация 18
алгоритм выбора маршрута 17
архитектура
с доступом только к кэш-памяти 23
с неоднородным доступом к памяти 23
с однородным доступом к памяти 23
Б
бисекционная пропускная способность 12
блокировка начала очереди 16
блокируемая сеть 21
буферизация на входе 16
буферизация на выходе 16
В
векторная система 23
Г
гиперкуб 14
Д
двойной тор 13
диаметр 12
З
закон Амдала 8
К
канал
дуплексный 11
полудуплексный 11
связи 11
симплексный 11
кластер рабочих станций 24
когерентность памяти 21
кольцо 13
коммуникационная система 11
коммутатор 11
коммутация каналов 14
с промежуточным хранением 15
координатный коммутатор 18
коэффициент разветвления 12
куб 13
М
маршрутизация от источника 17
масштабируемость 7
матричная система 23
многоступенчатая сеть 19
мультикомпьютер 6
мультипроцессор 5
О
общая буферизация 16
омега-коммутатор 19
омега-сеть 19
П
пакет 15
параллелизм
блоков 10
потоков 10
процедур 10
процессов 11
полное межсоединение 13
поток 9
пропускная способность 8
пространственная маршрутизация 18
процессоры с массовым параллелизмом 24
Р
размерность сети 12
расслоенная память 21
расширяемость 7
решетка 13
С
сетка 13
сеть рабочих станций 24
системы без доступа к отдаленным модулям памяти 24
система с распределенной памятью 6
система с совместно используемой памятью 5
статическая маршрутизация 18
степень узла 12
строка памяти 21
Т
топология 11
Список литературы
-
Таненбаум Э. Архитектура компьютера. Пер. с англ. Изд. 4-е, СПб, Питер, 2002, 704 с. (глава 8).
Содержание
Введение…………………………………………………………………………………….........3
1. Информационные модели параллельных систем………………………..........5
-
Мультипроцессорные и мультикомпьютерные системы……………………...5
-
Организация параллельных вычислений…………………………...…..............9
-
Коммуникационные системы…………………………………………….........11
-
Отслеживание состояний кэш-памяти………………………………………...21
-
Классификация параллельных систем………………………………………...22
Алфавитный указатель…………………………………………………………………………25
Список литературы……………………………………………………………………………..28