

-
Модуль статистической обработки данных
Архитектура модуля представлена на рис 5.
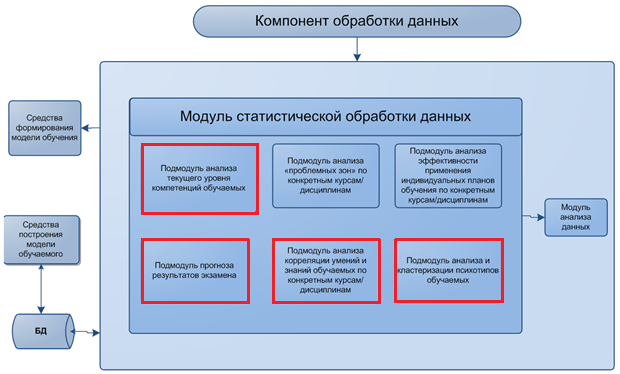
Рис.5. Архитектура модуля статистической обработки данных
Данная архитектура включает в себя 6 подмодулей: Подмодуль анализа текущего уровня компетенций обучаемых, подмодуль прогноза результатов экзамена, подмодуль анализа “проблемных зон” по конкретным курсам/дисциплинам, подмодуль анализа корреляции умений и знаний обучаемых по конкретным курсам/дисциплинам, подмодуль анализа эффективности применения индивидуальных планов обучения по конкретным курсам/дисциплинам.
Далее рассмотрим алгоритмы базовой версии модуля статистической обработки информации.
Алгоритм прогноза оценки за экзамен
Рассмотрим постановку задачи в целом.
Дано:
-
Уровень умений студентов, выявленный в ходе обучающих воздействий
-
Уровень знаний студентов, выявленный в ходе обучающих воздействий.
За уровень знаний взяты все тестирования, имеющие 100-бальную систему оценивания, все остальные работы рассматривались как уровень умений и так же переводились в 100-бальную систему оценивая.
Требуется: Спрогнозировать оценку за экзамен для каждого студента, входящего в выбранный курс.
Прогнозирование оценки происходит в несколько этапов, в соответствии с алгоритмом, который подробно описан далее. Блок-схема приведена на рис.6.
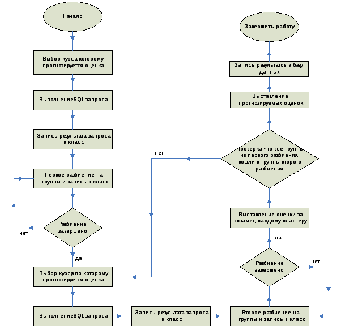 Рис.6.
Блок-схема алгоритма прогноза оценки
за экзамен.
Рис.6.
Блок-схема алгоритма прогноза оценки
за экзамен.
Шаг 1:Выбирается курс (К6, К8 или У8), которому необходимо осуществить прогноз оценки за экзамен и так же выбирается год поступления.
Шаг 2:Осуществляется выборка всех оценок по курсу, которому необходимо сделать прогноз, результат записывается в класс.
Шаг 3: Все обучаемые, входящие в курс, которому делается прогноз разбиваются на группы по следующему принципу: все оценки по очереди вычитаются друг из друга, и после каждой такой операции результатом является + или -, + означает что студент прогрессирует,- что студент деградирует. Все результаты сохраняются в другой класс.
Шаг 4: Выбирается курс, по которому будет осуществляться прогноз оценки за экзамен, так же выбирается год поступления.
Шаг5:Осуществляется выборка всех оценок по курсу, по которому осуществляется прогноз, результат записывается в класс.
Шаг 6:Все обучаемые, входящие в курс, по которому делается прогноз разбиваются на группы по следующему принципу: все оценки по очереди вычитаются друг из друга, и после каждой такой операции результатом является + или -, + означает что студент прогрессирует,- что студент деградирует. Все результаты сохраняются в другой класс.
Шаг 7: Для каждой получившейся группы вычисляется оценка за экзамен, которая равна среднему арифметическому оценок всех обучаемых, вошедших в конкретную группу.
Шаг 8: Выполняется проверка на покрытие всех групп, из прогнозируемого курса. Если не все кластеры покрыты, то возврат на шаг 4.
Шаг 9: Далее каждому студенту выставляется оценка за экзамен, на основе того, в какую группу он вошёл и какая оценка была вычислена данной группе в шаге 4.
Алгоритм прогноза экзаменационной сессии.
Рассмотрим постановку задачи в целом.
Дано:
-
Спрогнозированные оценки за экзамен, по выбранному курсу
-
Реальные оценки за экзамен, полученные студентами в выбранном курсе
Требуется: подсчитать, сколько и каких оценок прогнозируется в экзаменационную сессию, а так же на сколько был верен прогноз оценки за экзамен. Оценки отбираются из результатов прогнозирования оценок за экзамен, по каждому студенту и им сопоставляются реальные оценки, полученные студентами на экзамене. Блок-схема алгоритма приведена на рис.7.
Шаг1:Выбор курса, которому необходимо спрогнозировать результаты экзаменационной сессии.
Шаг 2:Выбираются спрогнозированные и реальные оценки за экзамен каждого студента выбранного в шаге 1 курса, и результат запроса записывается в массив.
Шаг 3:Происходит группировка всех прогнозируемых оценок за экзамен и по каждой группировке подсчитывается количество оценок.
Шаг 4: Происходит группировка всех реальных оценок за экзамен и по каждой группировке подсчитывается количество оценок.
Шаг 5:Строятся гистограммы в разрезе количества оценок за экзамен.
Шаг 6:Результат выводится на экран.
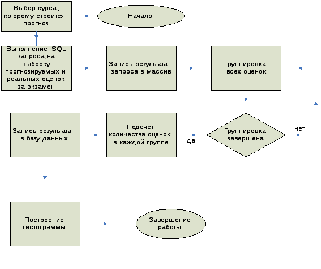 Рис.7.Блок-схема
алгоритма прогнозирования результатов
экзаменационной сессии.
Рис.7.Блок-схема
алгоритма прогнозирования результатов
экзаменационной сессии.
Алгоритм определения степени корреляции уровня умений и уровня знаний обучаемых.
Рассмотрим постановку задачи в целом.
Дано:
-
Выборка X – уровень знаний обучаемых: Результаты 1-го и 2-го тестирований, причем оценки выбирались именно за зоны, связанные с прямым и обратным выводом.
-
Выборка Y – уровень умений обучаемых: Результаты прямого и обратного вывода, в начале и в конце семестра.
Требуется: произвести анализ гипотезы о том, что уровень умений и уровень знаний имеют линейную зависимость. Выдвинуто предположение, что данные Xи Yраспределены по нормальному закону. Блок схема алгоритма изображена на рис.8.
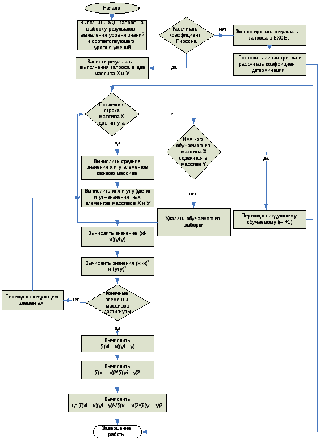
Рис.8.Блок-схема алгоритма выявления взаимосвязи между уровнем знаний и умений.
Шаг 1:Осуществляется выборка данных в массивы Xи Y, причём данные структурируются по каждому студенту.
Шаг 2: Вычисляется коэффициент корреляции Пирсона, после чего строятся точечные диаграммы для каждой пары выборок Xи Y. На диаграммах проводятся линии тренда, показывающие, на сколько плохо или хорошо прослеживается зависимость данных в выборках Xи Y.
Шаг 3: Делается вывод о том, существует ли линейная взаимосвязь между уровнем знаний и уровнем умений.
Алгоритма анализа и кластеризации психотипов обучаемых.
Рассмотрим постановку задачи в целом.
Дано:
-
Связка психотипа, выявленного у конкретного студента выбранного курса, и оценки за экзамен, полученной этим студентом
Требуется: вычислить успеваемость каждого психотипа студентов, который был выявлен в ходе тестирования обучаемых, при условии, что у этого обучаемого есть оценка за экзамен. Так же возможна группировка психотипов обучаемых, учитывая их успеваемость. Это позволит выявить, какие психотипы подвержены лучшему обучению, а какие наоборот, справляются с обучением хуже всего. Блок-схема алгоритма изображена на рис.8.
Шаг 1: Осуществляется выборка студентов одного курса, из базы данных тянутся психотипы студентов и их оценка за экзамен. Результат запроса записывается в массив X.
Шаг 2:Из массива Xудаляются записи, для которых не заполнена оценка за экзамен.
.Шаг 3:Все записи в массиве группируются по названию психотипа, оценка за экзамен для каждой группы суммируется и усредняется.
Шаг 4:Происходит группировка психотипов по следующему принципу:
-
Если балл попадает в промежуток (4;5), то психотип попадает в кластер «Психотипы с высокой успеваемостью»
-
Если балл попадает в промежуток (3;3,9), то психотип попадает в кластер «Психотипы со средней успеваемостью»
-
Если балл меньше 3 , то психотип попадает в кластер «Психотипы с низкой успеваемостью»
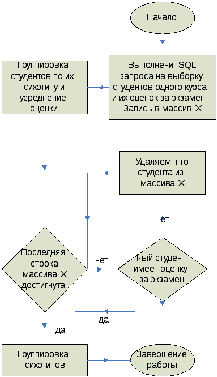
Рис.9.блок-схема алгоритма анализа и кластеризации психотипов обучаемых
Так как при мониторинге важную роль играет обработка данных, то рассмотрим параметры статистической обработки информации, используемой в процессе функционирования обучающих веб-ИЭС, характеризующих обучаемого и контингент обучаемых, сформулированные Рыбиной Г.В., для анализа огромного количества накопленных данных, с целью улучшения качества обучения и выполнения функций мониторинга.