

os2016-22-04-dist
.pdfИнтеллектуальный анализ данных (ИАД) – много определений
•ИАД — это процесс выделения из данных неявной и неструктурированной информации и представления ее в виде, пригодном для реализации
•ИАД — это процесс анализа, выделения и представления детализированных (detailed data) данных неявной конструктивной информации для решения проблем бизнеса (NCR)
•ИАД — это процесс выделения (selecting), исследования и моделирования больших объемов данных для обнаружения неизвестных до этого структур (patterns) с целью достижения преимуществ в бизнесе (SAS Institute)
•ИАД — это процесс, цель которого — обнаружить новые значимые корреляции, образцы и тенденции в результате просеивания большого объема хранимых данных с использованием методик распознавания образцов плюс [применение] статистических и математических методов (Gartner Group)
•ИАД — это процесс автоматического выделения действительной, эффективной, ранее неизвестной и совершенно понятной информации из больших баз данных и использование ее для принятия ключевых бизнес-решений
•ИАД — это процесс обнаружения в сырых данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности (GTE Labs)
ИАД – набор методов и алгоритмов
Классический набор:
• Искусственные нейронные сети
• Генетические алгоритмы |
|
• Деревья принятия решений |
ИАД |
•Кластеризация (ближайшие соседи)
•Rule induction: Извлечение полезных «Если - то» правил из баз данных
Деревья принятия решений
Пример взят из книги: В. Дюк, А. Самойленко Data Mining. Учебный курс, 2001 – Питер
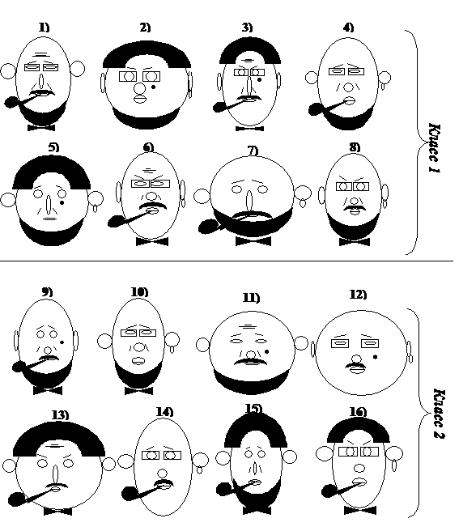
•На рисунке схематично изображены лица людей
•Эти лица по каким-то причинам (может быть важным, например болельщики «Зенита» и «Спартака») разделены на два класса
•Надо найти закономерности проведенного разделения
Выделим признаки, характеризующие изображенные лица
•x1 (голова) – круглая – 1, овальная – 0;
•x2 (уши) – оттопыренные – 1, прижатые – 0;
•x3 (нос) – круглый – 1, длинный – 0;
•x4 (глаза) – круглые – 1, узкие – 0;
•x5 (лоб) – с морщинами – 1, без морщин – 0;
•x6 (складка) – носогубная складка есть – 1, носогубной складки нет – 0;
•x7 (губы) – толстые – 1, тонкие – 0;
•x8 (волосы) – есть – 1, нет – 0;
•x9 (усы) – есть – 1, нет – 0;
•x10 (борода) – есть – 1, нет – 0;
•x11 (очки) – есть – 1, нет – 0;
•x12 (родинка) – родинка на щеке есть – 1, родинки на щеке нет – 0;
•x13 (бабочка) – есть – 1, нет – 0;
•x14 (брови) – подняты кверху – 1, опущены книзу – 0;
•x15 (серьга) – есть – 1, нет – 0;
•x16 (трубка) – курительная трубка есть – 1, нет – 0.

Строим исходную матрицу данных
№ п/ Голов Уши Нос |
Глаза Лоб Скла Губы Воло Усы |
Боро Очки Роди Бабо |
Бров |
Серьг ТрубкClass |
||||
п |
а |
дка |
сы |
да |
нка чка |
и |
а |
а |
|
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13 x14 x15 x16 |
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
2 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
3 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
4 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
5 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
6 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
7 |
1 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
8 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
9 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
2 |
10 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
2 |
11 |
1 |
1 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
2 |
12 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
0 |
2 |
13 |
1 |
1 |
0 |
1 |
1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
2 |
14 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
2 |
15 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
1 |
2 |
16 |
0 |
1 |
1 |
1 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
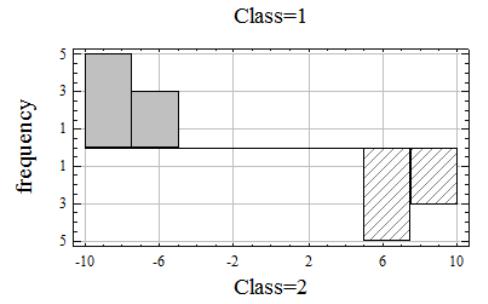
Гистограммы распределения значений дискриминантной функции
Казалось бы, мы достигли желаемой цели — правило классификации построено.
Но вряд ли такое правило способно удовлетворить разработчика интеллектуальной системы. Оно формально и не дает нового знания. Глядя на это правило, мы можем лишь перечислить признаки, вошедшие в дискриминантную функцию, и сказать, что данные признаки необходимы для разделения двух классов объектов
Хотим интерпретируемость результатов
•Основное требование к математическому аппарату обнаружения закономерностей в данных (кроме, конечно, требования эффективности) заключается в интерпретируемости результатов
•Правила, выражающие найденные закономерности, должны формулироваться на простом и понятном человеку языке логических высказываний
•Например, ЕСЛИ {(событие 1) и (событие 2) и … и (событие N)} ТО … Иными словами, это должны быть логические правила.
Классификация лиц в примере
•1. ЕСЛИ {(голова овальная) и (есть носогубная складка) и (есть очки) и (есть трубка)} ТО (Класс 1);
•2. ЕСЛИ {(глаза круглые) и (лоб без морщин) и (есть борода) и (есть серьга)} ТО (Класс 1);
•3. ЕСЛИ {(нос круглый) и (лысый) и (есть усы) и (брови подняты кверху)} ТО (Класс 2);
•4. ЕСЛИ {(оттопыренные уши) и (толстые губы) и (нет родинки на щеке) и (есть бабочка)} ТО (Класс
2).
Применим concept-learning systems (CLS)
•Алгоритм циклически разбивает обучающие примеры на классы в соответствии с переменной, имеющей наибольшую классифицирующую силу
•Каждое подмножество примеров (объектов), выделяемое такой переменной, вновь разбивается на классы с использованием следующей переменной с наибольшей классифицирующей способностью и т. д.
•Разбиение заканчивается, когда в подмножестве оказываются объекты лишь одного класса. В ходе процесса образуется дерево решений
•Пути движения по этому дереву с верхнего уровня на самые нижние определяют логические правила в виде цепочек конъюнкций