

Биометрия_пособие2
.pdf1.2. Дисперсионный анализ
1.Запустить программу Exсel (см. 1.1);
2.Ввести данные (например, в столбец «А» данные первой выборки, а в столбец «B» данные второй выборки и т.д.) (см. 1.1);
3.Открыть функцию «Сервис», выбрать «Анализ данных» и нажать «ОК» (см. 1.1);
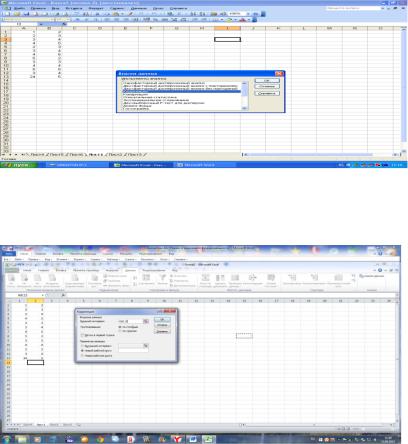
4.Выбрать в «Инструмент анализа» «Однофакторный дисперсионный анализ» и нажать «ОК»:
5.Ввести входной интервал по столбцам. Для этого нужно выделить, нажав и удерживая левую кнопку мыши, набранные значения. Входной интервал впишется автоматически. Установить «Альфа» - 0,05. Нажать «ОК»:
41
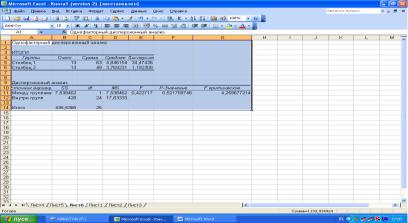
6.На экран выведется таблица результатов дисперсионного анализа. В «Итогах» по столбцам будет отражено количество данных по столбцам, сумма данных, среднее и дисперсия:
Выделив и скопировав таблицу, ее можно вставить в текст, например, в документ Word.
1.3. Корреляционный анализ
1.Запустить программу Exсel (см.1.1);
2.Ввести данные (например, в столбец «А» данные первой выборки, а в столбец «B» данные второй выборки и т.д.) (см.1.1);
3.Открыть функцию «Сервис», выбрать «Анализ данных» и нажать «ОК» (см.1.1);
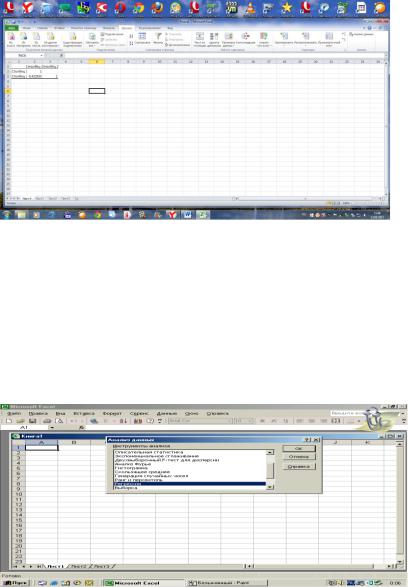
4.Выбрать в «Инструмент анализа» «Корреляция» и нажать
«ОК»:
42
5.Ввести входной интервал по столбцам. Для этого нужно выделить, нажав и удерживая левую кнопку мыши, набранные значения. Входной интервал впишется автоматически. Нажать
«ОК»:
6.На экран выведется таблица результатов корреляционного анализа по столбцам, где будет представлен(ы) коэффициент(ы) корреляции (r):
43
Все полученные данные сохраняются обычным путем (см.1.1).
1.4. Регрессионный анализ
1.Запустить программу Exсel (см.1.1);
2.Ввести данные (например, в столбец «А» данные первой выборки, а в столбец «B» данные второй выборки и т.д.) (см.1.1);
3.Открыть функцию «Сервис», выбрать «Анализ данных» и нажать «ОК» (см.1.1);
4.Выбрать в «Инструмент анализа» «Регрессия» и нажать
«ОК»:
5. Ввести входные интервалы по столбцам. Для этого нужно
44
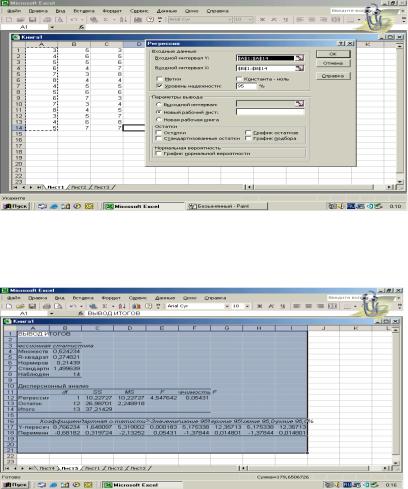
выделить, нажав и удерживая левую кнопку мыши, набранные значения в столбце «А» для входного интервала Y и значения в столбце «В» для входного интервала Х:
6. На экран выведется таблица результатов регрессионного анализа. В «Итогах» нужно использовать коэффициенты для функции У = аХ + в, где «а» - коэффициент Х, а «в» - коэффициент У:
Все полученные данные сохраняются обычным путем.
45
Тема 2. Обработка опытных данных в программе
Statisticа
Расчет описательных статистик проводится при помощи модуля Basic Statistic/Tables. В этом модуле объединены наиболее часто использующиеся на начальном этапе обработки данных
процедуры.
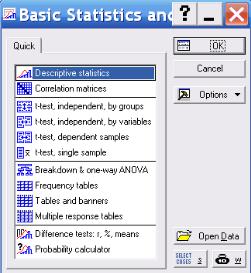
В стартовой панели модуля приводится перечень статистических процедур этого модуля
(рис. 2.1).
Рис. 2.1. Стартовое окно модуля с перечнем статистических процедур, где:
Descriptive statistics - Описательные статистики; Correla-
tion matrices - Корреляционные матрицы; Breakdown & oneway ANOVA - Классификация и однофакторный дисперсионный анализ и др.
2.1. Модуль «Описательные статистики»
(Descriptive statistics)
Возможности этой процедуры лучше всего изучить на примере. Пусть имеется выборка объемом 45 измерений, представляющая собой результаты обмера и взвешивания двустворчатых моллюсков, обитающих в реке Белой в районе города Стерлитамака. Файл данных (рис. 2.2) содержит 4 переменных: VAR1длина раковины, мм; VAR2выпуклость раковины, мм; VAR3высота раковины, мм; VAR4вес моллюска, г.
46
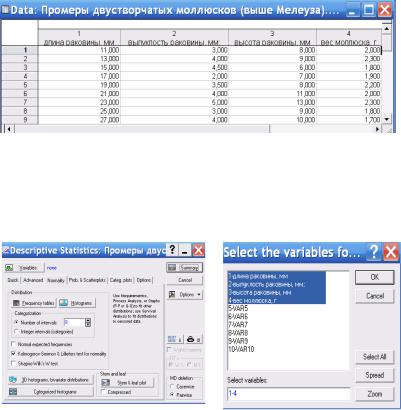
Рис. 2.2. Окно файла данных
После выбора процедуры Descriptive statistics на экране появится одноименное диалоговое окно (рис. 2.3). В этом окне при помощи кнопки Variables нужно выбрать переменные для анализа (рис.2.4).
Рис. 2.3. Диалоговое окно |
Рис. 2.4. Окно выбора |
Descriptive statistics |
переменных |
На первом этапе обработки данных часто возникает необходимость в их группировке. Группировка позволяет представить первичные данные в компактном виде, выявить закономерности варьирования изучаемого признака. Количество классов можно приблизительно наметить, пользуясь следующими рекомендациями: при количестве наблюдений 25-40 - 5-6 классов, при количестве наблюдений 40-60 - 6-8 классов, 60-100 - 7- 10, 100-200 наблюдений - 8-12, более 200 наблюдений - 10-15
47
классов.
Для построения гистограмм и таблиц частот используется группа кнопок Distribution окна Descriptive statistics. Число классов (интервалов) группировки данных устанавливается при помощи счетчика переключателя Number of intervals окна Descriptive statistics. Справа от кнопок Distribution находятся две опции Categorization (Группировка), позволяющие задать число интервалов группировки или установить величину интервала равную целому числу. Если активировать переключатель
Integer intervals (categories), то классы (интервалы) группи-
ровки будут представлять из себя целые числа.
Результаты группировки моллюсков по выпуклости раковины (переменная Var2) представлены в таблице 2.1.
Таблица 2.1
Результаты группировки моллюсков по выпуклости раковины
|
Count (кол-во) |
Cumulative |
Percent |
Cumul % |
% of all |
Cumulative % |
|
|
|
|
|
|
|
0,0<x<=2,0 |
1 |
1 |
2,2 |
2,2 |
2,2 |
2,2 |
2,0<x<=4,0 |
8 |
9 |
17,8 |
20,0 |
17,8 |
20,0 |
4,0<x<=6,0 |
6 |
15 |
13,3 |
33,3 |
13,3 |
33,3 |
6,0<x<=8,0 |
14 |
29 |
31,1 |
64,4 |
31,1 |
64,4 |
8,0<x<=10,0 |
8 |
37 |
17,8 |
82,2 |
17,8 |
82,2 |
10,0<x<=12,0 |
4 |
41 |
8,9 |
91,1 |
8,9 |
91,1 |
12,0<x<=14,0 |
2 |
43 |
4,4 |
95,6 |
4,4 |
95,6 |
14,0<x<=16,0 |
2 |
45 |
4,4 |
100,0 |
4,4 |
100,0 |
Missing |
0 |
45 |
0,0 |
|
0,0 |
100,0 |
Для представления распределения переменных на гистограммах предназначена кнопка Histograms окна Descriptive statistics.
На гистограмму при необходимости можно наложить плотность нормального распределения, проверить близость рас-
48
пределения к нормальному виду при помощи критериев Колмо- горова-Смирнова, Лилиефорса; вычислить статистику ШапироУилкса. Для этого в группе опций Distribution необходимо установить флажок напротив соответствующих статистик. Значения статистик показываются прямо на гистограммах.
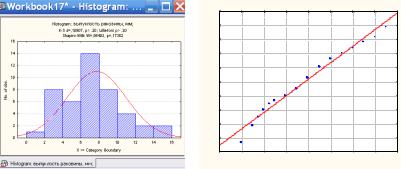
На рис. 2.5 в качестве примера приводится гистограмма распределения выпуклости раковины (переменная Var2). На гистограмме показана кривая плотности нормального распределения, а также критерий Колмогорова-Смирнова (d). О нормальности распределения можно судить по графику на нормальной вероятностной бумаге, который строится при помощи опции Normal probability plots окна Descriptive statistics
(рис.2.3). Чем ближе распределение к нормальному виду, тем лучше значения ложатся на прямую линию (рис. 2.6). Этот метод оценки является фактически глазомерным. В сомнительных случаях проверку на нормальность можно продолжить с использованием специальных статистических критериев (Колмо- горова-Смирнова, Омега-квадрат (w2)). Однако детальная проверка гипотезы о нормальности выборки требует довольно значительных объемов выборки (по мнению некоторых авторов не менее 100 наблюдений).
Ожи да е мые н о р ма ль н ы зн а ч е н и я
Г р а фи к н а н о рма ль о й в ер о я тн о с тн о й бма ге для в ып у кло с тиUnраi o коl oвnиgнi roыs tri s
2 ,5
2 ,0
1 ,5
1 ,0
0 ,5
0 ,0
-0 ,5
-1 ,0
-1 ,5
-2 ,0
-2 ,5
0 |
2 |
4 |
6 |
8 |
1 0 |
1 2 |
1 4 |
1 6 |
|
|
|
Зн а ч е н и я в ып у кло с и р ако в и н ы |
|
|
|
||
Рис. 2.5. Гистограмма рас- |
Рис. 2.6. График на нормаль- |
пределения выпуклости ра- |
ной вероятностной бумаге для |
ковины |
выборки выпуклости раковины |
Чтобы выбрать статистики, подлежащие вычислению, удобнее всего воспользоваться кнопкой Advanced (рис. 2.7).
49
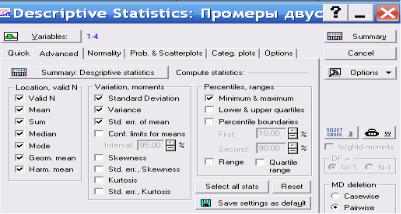
Против статистик, подлежащих вычислению, следует поставить флажок.
Рис. 2.7. Окно выбора статистик для вычисления: Valid N - объем выборки; Mean - средняя арифметическая; Sum - сумма; Median - медиана; Mode – мода; Geom. mean – геометрическое среднее; Harm. mean – гармоническое среднее; Standard Deviation - стандартное отклонение; Variance - дисперсия; Standard error of mean - стандартная ошибка среднего; 95% confidence limits of mean - 95%-ый доверительный интервал для среднего; Minimum, maximum - минимальное и максимальное значения; Lower, upper quartiles - нижний и верхний квартили; Range - размах; Skewness - асимметрия; Standard error of Skewness - стандартная ошибка асимметрии; Kurtosis - эксцесс; Standard error of Kurtosis - стандартная ошибка эксцесса.
После нажатия на кнопку «OK» окна Descriptive statistics на экране появится таблица с результатами расчетов описательных статистик (рис. 2.8). Пакет Statistica не рассчитывает такие статистики, как коэффициент вариации и относительная ошибка среднего значения (точность опыта). Но их определение не представляет большого труда. Коэффициент вариации
(%) есть отношение стандартного отклонения к среднему значению, умноженное на 100%.
50