

Способи представлення кодів
Найпростішим способом представлення або завдання кодів є кодові таблиці, що ставлять у відповідність повідомленням хi відповідні їм коди (таблиця 3.1).
Таблиця 3.1 – Кодова таблиця для алфавіту з 8 символів кирилиці
|
Буква хi |
Число хi |
Код з основою 10 |
Код з основою 4 |
Код з основою 2 |
|
А |
0 |
0 |
00 |
000 |
|
Б |
1 |
1 |
01 |
001 |
|
У |
2 |
2 |
02 |
010 |
|
Г |
3 |
3 |
03 |
011 |
|
Д |
4 |
4 |
10 |
100 |
|
Е |
5 |
5 |
11 |
101 |
|
Ж |
6 |
6 |
12 |
110 |
|
З |
7 |
7 |
13 |
111 |
Іншим наочним і зручним способом опису кодів є їхнє представлення у виді кодового дерева (рисунок 3.1).
Для того, щоб побудувати кодове дерево для даного коду, починаючи з деякої точки - кореня кодового дерева - проводяться галузі - 0 або 1. На вершинах кодового дерева знаходяться букви алфавіту джерела, причому кожній букві відповідають своя вершина і свій шлях від кореня до вершини. Наприклад, букві А відповідає код 000, букві В – 010, букві Е – 101 і т.д.
0 1
0
1 0 1
1 0 1 0 1
0 1 0
А Б В Г
Д Е Ж З
1 2 3 4 5 6 7
8
Рис. 4.
 Корінь
Корінь
Код, отриманий з використанням кодового дерева, зображеного на рис.1, є рівномірним трьохрозрядним кодом.
Рівномірні коди дуже широко використовуються в силу своєї простоти і зручності процедур кодування-декодування: кожній букві – однакове число біт; прийняв задане число біт – шукай у кодовій таблиці відповідну букву.
Нерівномірні коди
Поряд з рівномірними кодами можуть застосовуватися і нерівномірні коди, коли кожна буква з алфавіту джерела кодується різним числом символів, приміром, А - 10, Б – 110, У – 1110 і т.д.
Кодове дерево для нерівномірного кодування може виглядати, наприклад, так, як показано на рисунку 3.2.
При використанні цього коду буква А буде кодуватися, як 1, Б - як 0, У – як 11 і т.д. Однак можна помітити, що, закодувавши, приміром, текст АББА = 1001 , ми не зможемо його однозначно декодировать, оскільки такий же код дають фрази: ЖА = 1001, АЕА = 1001 і ГД = 1001.
Такі коди, що не забезпечують однозначного декодування, називаються непрефіксними, кодами і не можуть на практиці застосовуватися без спеціальних поділяючих символів. Прикладом застосування такого типу кодів може служити азбука Морзе.

Рисунок 3.2 – Кодове дерево для нерівномірного кодування
В азбуці Морзе кожній букві або цифрі повідомлення ставиться у відповідність деяка послідовність точок (короткий сигнал) і тире (в три рази довший), які розділяють короткими паузами; пропуск між буквами відмічається довгою паузою, а пропуск між словами ще в два рази довшою паузою. Хоч цей код використовує тільки точки і тире його можна вважати трійковим, так як кожне закодоване повідомлення містить три елементарних сигнали: короткі сигнали (точки), довгі (тире), довгі паузи.
Код Бодо у відповідність кожній букві ставить послідовності з п’яти елементарних сигналів – посилок сигналу і паузи одинакової довжини. Так як при цьому всі букви передаються комбінаціями сигналів одної довжини, то в коді Бодо не потрібно спеціального знаку , який відділяє одну букву від іншої – наперед відомо, що через кожні п’ять елементарних сигналів закінчується одна буква і починається інша.
Можна побудувати нерівномірні коди, що допускають однозначне декодування. Для цього необхідно, щоб усім буквам алфавіту відповідали лише вершини кодового дерева, наприклад, такого, як показано на рисунку 3.3. Тут жодна кодова комбінація не є початком іншої, більш довгої, тому неоднозначності декодування не буде. Такі нерівномірні коди називаються префіксними.
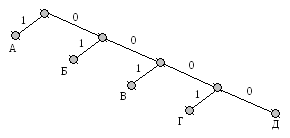
Рисунок 3.3 – Кодове дерево для коду що допускає однозначне декодування
Прийом і декодування нерівномірних кодів – процедура набагато більш складна, ніж для рівномірних. При цьому ускладнюється апаратура декодування і синхронізації, оскільки надходження елементів повідомлення (букв) стає нерегулярним. Так, приміром, прийнявши перший 0, декодер повинен подивитися в кодову таблицю і з'ясувати, якій букві відповідає прийнята послідовність. Оскільки такої букви немає, він повинен чекати приходу наступного символу. Якщо наступним символом буде 1, тоді декодування першої букви завершиться – це буде Б, якщо ж другим прийнятим символом знову буде 0, прийдеться чекати третього символу і т.д.
Розглянемо приклад кодування повідомлень хi з алфавіту обсягом K = 8 за допомогою довільного n-розрядного двікового коду.
Нехай джерело повідомлення видає деякий текст з алфавітом від А до З и однаковою імовірністю букв Р(хi ) = 1/8.
Кодуючий пристрій кодує ці букви рівномірним трьохрозрядним кодом (див. табл. 3.1).
Визначимо основні інформаційні характеристики джерела з таким алфавітом:
– ентропія
джерела ![]() ,
,![]() ;
;
– надмірність
джерела 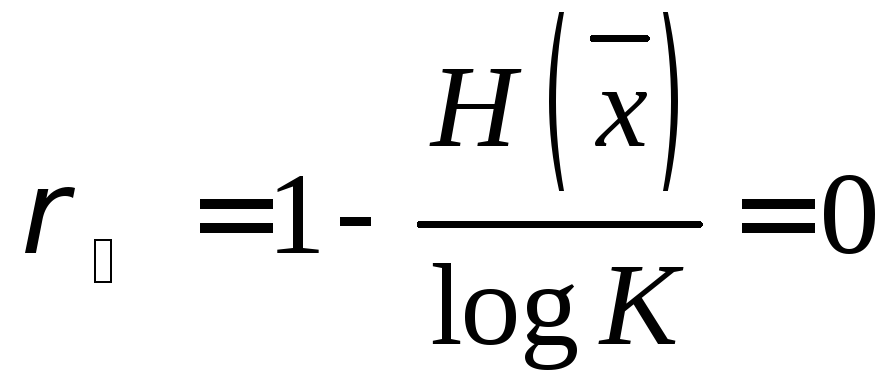 ;
;
– середнє
число символів у коді ![]() ;
;
– надмірність
коду
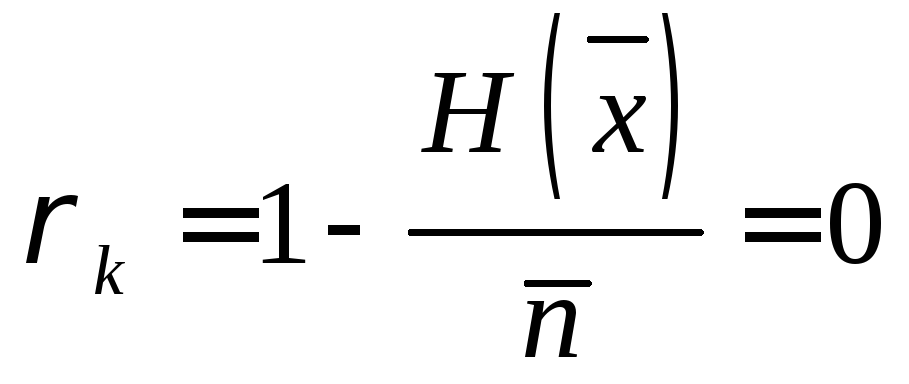 .
.
Таким чином, при кодуванні повідомлень з рівноймовірними буквами надмірність обраного (рівномірного) коду виявилася рівної нулеві.
Нехай тепер імовірності появи в тексті різних букв будуть різними (таблиця 3.2).
Таблиця 3.2 – Імовірності появи символів
|
А |
Б |
У |
Г |
Д |
Е |
Ж |
З |
|
Ра=0.6 |
Рб=0.2 |
Рв=0.1 |
Рг=0.04 |
Рд=0.025 |
Ре=0.015 |
Рж=0.01 |
Рз=0.01 |
Ентропія
джерела
![]() в цьому випадку, природно, буде
меншою
і складе
в цьому випадку, природно, буде
меншою
і складе
![]() = 1.781.
= 1.781.
Середнє число символів на одне повідомлення при використанні того ж рівномірного трьохрозрядного коду
![]()
Надмірність коду в цьому випадку буде
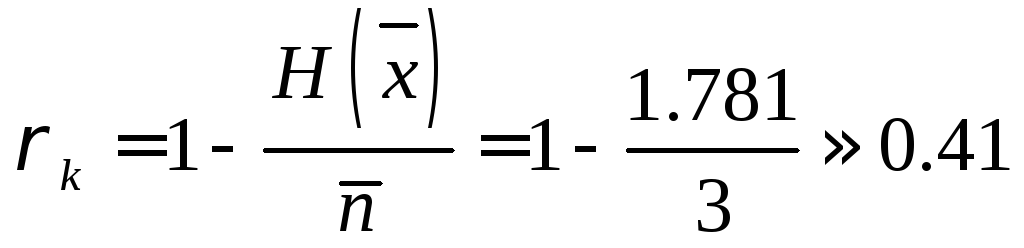 ,
,
або досить значною величиною (у середньому 4 символи з 10 не несуть ніякої інформації).