


56
исходя из того, что e−nc = (a* y1 −1), получим b
c = 1 ln a* y1 −1 . n b
3.3. Выбор оптимального вида прогнозной модели
Как было показано ранее, основу оценки достоверности прогноза составляет величина стандартной ошибки
S y = |
1 |
∑n (yi − ˆyi )2 . |
|
||
|
n − p i=1 |
|
Этот показатель объясняет степень приближения прогнозной модели к реальным наблюдениям за процессом, но не дает однозначного ответа о качестве модели, то есть не дает ответа на вопрос: насколько правомерен выбор именно данного вида модели?
Важным критерием, позволяющим оценить качество модели (мера качества подбора линии регрессии), является коэффициент детерминации
|
|
|
r 2 =1 − |
S y |
|
0 < r 2 <1, |
|
|
|
2 |
, |
||
|
|
|
S12 |
|||
|
|
|
|
|
|
|
где |
S12 = |
1 |
∑n (yi − yi )2 – полная дисперсия зависимой переменной, |
|||
|
||||||
|
|
n −1 i=1 |
|
|
|
|
вычисленная по эмпирическим данным динамического ряда.
Коэффициент детерминации характеризует долю объясненной регрессией дисперсии в общей величине дисперсии зависимой переменной. Чем меньше
S y2 , тем выше r 2 и тем теснее примыкают отдельные наблюдения к линии регрессии.

57
Коэффициент детерминации в виде
S 2 r = 1 − y
S12
принято называть индексом корреляции или корреляционным отношением. Для проверки значимости уравнения регрессии, в целом, используется F-
критерий Фишера.
S 2
F = 1 .
S y2
Этот критерий показывает, во сколько раз уравнение регрессии предсказывает результаты опытов лучше, чем среднее y.
Условием статистической значимости уравнения регрессии является неравенство
S 2
F = S12 ≥ Fтабл. , y
где Fтабл. – табличное значение критерия Фишера, определяемое по уровню значимости α и степеням свободы ν1 = n −1 и ν2 = n − p .
Выполнение расчетов по отысканию оптимальной формы связи при большом числе исходных данных вручную теоретически возможно, но практически требует такого количества времени, что задача становится нереальной. Поэтому для получения оптимальной парной зависимости при условии r 2 → max используют, как правило, ЭВМ.
Необходимо отметить, что до тех пор, пока не проверены все известные формы связи, исследователь не может быть уверен, что выбрана лучшая прогнозная модель. Исключение составляет случай, когда «облако» точек имеет определенную интерпретируемую форму.

58
3.4. Проверка прогнозной модели на автокорреляцию ошибок
При определении параметров уравнения регрессии с помощью МНК считается, что значения ошибок различных наблюдений независимы друг от друга. Данное предположение требует дополнительной проверки на отсутствие внутрирядной корреляции временных рядов, так как ее наличие может привести к значительному смещению дисперсий параметров модели. Таким образом, необходимо проверить модель на автокорреляцию ошибок [3].
Под автокорреляцией понимается корреляция между членами одного и того же ряда; иначе говоря, автокорреляция – это корреляция ряда y1 , y2 , y3 ,...
с рядом y[1+l ], y[2+l ], y[3+l ],... Число l характеризует запаздывание (лаг).
Корреляция между соседними членами ряда (l =1)называется автокорреляцией первого порядка.
Степень автокоррелированности ряда обычно измеряется с помощью коэффициента корреляции, который в этом случае называют коэффициентом автокорреляции R:
|
|
|
|
|
|
|
|
n∑−1(yt − y1 )(yt+1 − y2 ) |
|
|
|
|
|
|
|
|
|
R = |
t=1 |
|
, |
|
|
|
|
|
|
|
n∑−1(yt − y1 )2 ∑n (yt+1 − y2 )2 |
|||
|
|
|
|
|
|
|
|
t=1 |
t=1 |
|
|
|
1 |
|
|
n−1 |
|
|
|
|
|
где y1 |
= |
|
|
|
|
∑ yt |
– средний уровень первого ряда; |
|
||
n − |
|
|
||||||||
|
|
1 t=1 |
|
|
|
|
||||
|
|
1 |
|
|
n |
|
|
|
|
|
y2 |
= |
|
|
∑ yt |
– средний уровень второго ряда. |
|
||||
|
|
|
|
|
||||||
|
|
|
n −1t=2 |
|
|
|
|
|||
Наличие корреляции в последовательном ряду значений определяется с помощью критерия Дарбина-Уотсона, рассчитываемого по формуле
d = |
∑n (εt − εt −1 )2 |
|
t =2 |
, |
|
n |
||
|
∑εt2 |
|
|
t =1 |
|

59
где εt – остаток ( yt − ˆyt ) в момент времени t;
εt − εt −1 – правая последовательная разность остатков.
Для d-статистики найдены критические границы, позволяющие принять или отвергнуть гипотезу об отсутствии автокорреляции (табл. 3.5).
В таблице d1 и d2 являются нижней и верхней границами критерия Дарбина-Уотсона; Vi – число переменных в модели; n – длина временного ряда.
Для применения критерия Дарбина-Уотсона величина d, рассчитанная по формуле, сравнивается с табличными d1 и d2 . Возможны три случая:
1)если d1 < d2 , гипотеза об отсутствии автокорреляции в отклонениях отвергается;
2)если d1 > d2 , гипотеза об отсутствии автокорреляции в отклонениях принимается;
3)если d1 ≤ d ≤ d2 , необходимы дальнейшие исследования (например,
по большему числу наблюдений).
Таблица 3.5. Распределение критерия Дарбина-Уотсона для положительной
автокорреляции (для 5 %-ного уровня значимости)
n |
V = 1 |
|
|
V = 2 |
V = 3 |
V = 4 |
|
V = 5 |
|||||
d1 |
|
d2 |
d1 |
|
d2 |
d1 |
d2 |
d1 |
d2 |
d1 |
|
d2 |
|
|
|
|
|
||||||||||
1 |
2 |
|
3 |
4 |
|
5 |
6 |
7 |
8 |
9 |
10 |
|
11 |
15 |
1,08 |
|
1,36 |
0,95 |
|
1,54 |
0,82 |
1,75 |
0,69 |
1,97 |
0,56 |
|
2,21 |
16 |
1,10 |
|
1,37 |
0,98 |
|
1,54 |
0,86 |
1,73 |
0,74 |
1,93 |
0,62 |
|
2,15 |
17 |
1,13 |
|
1,38 |
1,02 |
|
1,54 |
0,90 |
1,71 |
0,78 |
1,90 |
0,67 |
|
2,10 |
18 |
1,16 |
|
1,39 |
1,05 |
|
1,53 |
0,93 |
1,69 |
0,82 |
1,87 |
0,71 |
|
2,06 |
19 |
1,18 |
|
1,40 |
1,08 |
|
1,53 |
0,97 |
1,68 |
0,86 |
1,85 |
0,75 |
|
2,02 |
20 |
1,20 |
|
1,41 |
1,10 |
|
1,54 |
1,00 |
1,68 |
0,90 |
1,83 |
0,79 |
|
1,99 |
21 |
1,22 |
|
1,42 |
1,13 |
|
1,54 |
1,03 |
1,67 |
0,93 |
1,81 |
0,83 |
|
1,96 |
22 |
1,24 |
|
1,43 |
1,15 |
|
1,54 |
1,05 |
1,66 |
0,96 |
1,80 |
0,86 |
|
1,94 |
23 |
1,26 |
|
1,44 |
1,17 |
|
1,54 |
1,08 |
1,66 |
0,99 |
1,79 |
0,90 |
|
1,92 |
24 |
1,27 |
|
1,45 |
1,19 |
|
1,55 |
1,10 |
1,66 |
1,01 |
1,78 |
0,93 |
|
1,90 |
25 |
1,29 |
|
1,45 |
1,21 |
|
1,55 |
1,12 |
1,66 |
1,04 |
1,77 |
0,95 |
|
1,89 |
26 |
1,30 |
|
1,46 |
1,22 |
|
1,55 |
1,14 |
1,65 |
1,06 |
1,76 |
0,98 |
|
1,88 |
27 |
1,32 |
|
1,47 |
1,24 |
|
1,56 |
1,16 |
1,65 |
1,08 |
1,76 |
1,01 |
|
1,86 |
28 |
1,33 |
|
1,48 |
1,26 |
|
1,56 |
1,18 |
1,65 |
1,10 |
1,75 |
1,03 |
|
1,85 |
29 |
1,34 |
|
1,48 |
1,27 |
|
1,56 |
1,20 |
1,65 |
1,12 |
1,74 |
1,05 |
|
1,84 |
60
Окончание табл. 3.5
30 |
|
1,35 |
1,49 |
1,28 |
|
1,57 |
1,21 |
|
1,65 |
1,14 |
|
1,74 |
1,07 |
|
1,83 |
31 |
|
1,36 |
1,50 |
1,30 |
|
1,57 |
1,23 |
|
1,65 |
1,16 |
|
1,74 |
1,09 |
|
1,83 |
32 |
|
1,37 |
1,50 |
1,31 |
|
1,57 |
1,24 |
|
1,65 |
1,18 |
|
1,73 |
1,11 |
|
1,82 |
33 |
|
1,38 |
1,51 |
1,32 |
|
1,58 |
1,26 |
|
1.65 |
1,19 |
|
1,73 |
1,13 |
|
1,81 |
34 |
|
1,39 |
1,51 |
1,33 |
|
1,58 |
1,27 |
|
1,65 |
1,21 |
|
1,73 |
1,15 |
|
1,81 |
35 |
|
1,40 |
1,52 |
1,34 |
|
1,58 |
1,28 |
|
1,65 |
1,22 |
|
1,73 |
1,16 |
|
1,80 |
36 |
|
1,41 |
1,52 |
1,35 |
|
1,59 |
1,29 |
|
1,65 |
1,24 |
|
1,73 |
1,18 |
|
1,80 |
37 |
|
1,42 |
1,53 |
1,36 |
|
1,59 |
1,31 |
|
1,66 |
1,25 |
|
1,72 |
1,19 |
|
1,80 |
38 |
|
1,43 |
1,54 |
1,37 |
|
1,59 |
1,32 |
|
1,66 |
1,26 |
|
1,72 |
1,21 |
|
1,79 |
39 |
|
1,43 |
1,54 |
1,38 |
|
1,60 |
1,33 |
|
1,66 |
1,27 |
|
1,72 |
1,22 |
|
1,79 |
40 |
|
1,44 |
1,54 |
1,39 |
|
1,60 |
1,34 |
|
1,66 |
1,29 |
|
1,72 |
1,23 |
|
1,79 |
45 |
|
1,48 |
1,57 |
1,43 |
|
1,62 |
1,38 |
|
1,67 |
1,34 |
|
1,72 |
1,29 |
|
1.78 |
50 |
|
1,50 |
1,59 |
1,46 |
|
1,63 |
1.42 |
|
1,67 |
1,38 |
|
1,72 |
1,34 |
|
1,77 |
55 |
|
1,53 |
1,60 |
1,49 |
|
1,64 |
1,45 |
|
1,68 |
1,41 |
|
1,72 |
1,38 |
|
1,77 |
60 |
|
1,55 |
1,62 |
1,51 |
|
1,65 |
1,48 |
|
1,69 |
1,44 |
|
1,73 |
1,41 |
|
1,77 |
65 |
|
1,57 |
1,63 |
1,54 |
|
1,66 |
1,50 |
|
1,70 |
1,47 |
|
1,73 |
1,44 |
|
1,77 |
70 |
|
1,58 |
1,64 |
1,55 |
|
1,67 |
1,52 |
|
1,70 |
1,49 |
|
1,74 |
1,46 |
|
1,77 |
75 |
|
1,60 |
1,65 |
1,57 |
|
1,68 |
1,54 |
|
1,71 |
1,51 |
|
1,74 |
1,49 |
|
1,77 |
80 |
|
1,61 |
1,66 |
1,59 |
|
1,69 |
1,56 |
|
1,72 |
1,53 |
|
1,74 |
1,51 |
|
1,77 |
85 |
|
1,62 |
1,67 |
1,60 |
|
1,70 |
1,57 |
|
1,72 |
1,55 |
|
1,75 |
1,52 |
|
1,77 |
90 |
|
1,63 |
1,68 |
1,61 |
|
1,70 |
1,59 |
|
1,73 |
1,57 |
|
1,75 |
1,54 |
|
1,78 |
95 |
|
1,64 |
1,69 |
1,62 |
|
1.71 |
1.60 |
|
1,73 |
1.58 |
|
1,75 |
1,56 |
|
1,78 |
100 |
|
1,65 |
1,69 |
1,63 |
|
1,72 |
1,61 |
|
1,74 |
1,59 |
|
1,76 |
1,57 |
|
1,78 |
Величина d может принимать значения в интервале 0 ≤ d ≤ 4, причем |
|||||||||||||||
различные для положительных и отрицательных коэффициентов. Чтобы |
|
||||||||||||||
проверить значимость отрицательных автокорреляций, нужно вычислить |
|
||||||||||||||
величину ( 4 −d ). Далее проверка осуществляется так же, как и в случае |
|
||||||||||||||
положительной автокорреляции. |
|
|
|
|
|
|
|
|
|
||||||
4) |
Если |
автокорреляция |
ошибок |
имеет |
место, |
то |
целесообразно |
||||||||
использовать авторегрессионные методы прогнозирования с применением
моделей типа yi,t = f (yi,t −1; yi,t −2 ;...; yi,t −k ).
61
7
8 4. Многомерное параметрическое прогнозирование. метод многомерной линейной экстраполяции
Как отмечалось выше, различают две задачи экстраполяции – статическую и динамическую. Во втором случае задача экстраполяции сводится к прогнозированию поведения процесса во времени, то есть по его наблюдаемому отрезку и на основе каких-то априорных данных следует оценить дальнейшее поведение процесса во времени.
Статическая экстраполяция связана с параметрическим прогнозированием на плоскости или с прогнозированием в пространстве. Это означает, что аргументом здесь является вектор параметров и данный вид экстраполяции состоит в оценке значений векторного поля по отдельным наблюдениям.
Содержательную задачу многомерной параметрической экстраполяции, или, другими словами, пространственной экстраполяции, удобно описывать в следующих терминах. Пусть имеется конечное множество ситуаций – точек в пространстве ситуаций, где определены в ретроспекции некоторые решения (в общем виде – численные векторы). Задача экстраполяции состоит в том, чтобы оценить значение вектора решения в ситуации, которой не содержится в указанном множестве.
В последнее время для решения такого рода задач все большее применение находит так называемый метод многомерной линейной экстраполяции (ММЛЭ).
Задачу прогнозирования часто можно представить как задачу проектирования, то есть преобразования технического задания (объема предпрогнозной информации) в проект (прогноз). Если техническое задание обозначить вектором Х, а проект – Y, то процесс проектирования (прогнозирования) реализует преобразование
Y = F0 (X ),
62
где F0 – некоторая процедура проектирования.
Для автоматизации этого процесса необходимо формализовать процедуру
F0 . Это можно сделать двояким образом.
С одной стороны, можно вскрыть причинно-следственный механизм (правила проектирования), формализовать его и, запрограммировав соответствующим образом ЭВМ, получить с ее помощью проекты Y по техническим заданиям Х. Однако, как легко заметить, этот подход требует детального изучения процесса и реализуется лишь для очень простых конкретных задач.
Можно поступить иначе. Обычно имеется опыт проектирования изделий такого ряда, то есть матрица из n прецедентов (образцов-аналогов)
|
J =< Xi ,Yi (i = |
|
|
)>, |
|
|
1,N |
||||
где X i |
– i-е задание на проектирование; |
||||
Yi |
– проект, разработанный «старым» способом по этому заданию, то |
||||
есть |
Yi = F0 (Xi ), (i = |
|
|
). |
|
|
|
||||
|
1,N |
||||
Тогда, экстраполируя этот опыт (ретроспективную информацию) на |
|||||
новое техническое задание (новый вектор параметров) X N +1 , можно получить с некоторой погрешностью, но сразу проект (прогноз) YN +1 .
Таким образом, экстраполяция сводится к оценке значения YN +1 и X N +1
и матрице прецедентов YN +1 = F (X N +1 ,I ), где F – алгоритм экстраполяции.
Отметим, что если X и Y измеряются в метрических шкалах и являются векторами
X = (x1 ,x2 ,x3 ,...,xn ), Y = (y1 , y2 , y3 ,..., ym ),
то таблицу прецедентов можно представить в виде числовой матрицы
N ×(n + m):
X1, Y1
I = ............
X n , Yn
63
= |
|
|
x11, x21, ..., xn1; y11, y21, ..., |
yn1 |
|
. |
|
.......... |
........................................x1N , x2 N , ..., xnN ; y1N , y2 N ,..., ynN.. |
|
|||
|
|
|
|
|
||
|
|
|
|
|
|
|
Выбор алгоритма экстраполяции F , очевидно, зависит от количества имеющейся информации. Пусть нам известно только k прецедентов, k < N и i =1,k . Если число k достаточно велико по сравнению с размерностью вектора X (k > n), то задачу можно решить m-кратным применением метода наименьших квадратов.
Если число наблюдений k соизмеримо с размерностью вектора X, то
можно также решить задачу путем построения линейной модели |
|
Y = L(X ). |
(4.1) |
Интерес представляет случай, когда число k наблюдений мало и недостаточно для априорного построения линейной модели, то есть
k < n +1.
Решим задачу экстраполяции в этих условиях информационной недостаточности.
Множество векторов всех возможных ситуаций X обозначим через {X}, а соответствующее множество векторов Y решений – через {Y}. Линейную
модель вида (4.1) построим на подмножествах векторов { X ′} и {Y ′}, |
|
образованных исходя из реальных наблюдений |
|
Xi →Yi , i =1,k , |
(4.2) |
где символ «→» обозначает соответствие.
Исходя из того, что элементы линейного пространства могут быть представлены в виде полиномов степени не выше n > k −1, запишем уравнения для элементов векторных подмножеств { X ′} и {Y ′}:
{X ′}= X1 + k∑−1λi (Xi +1 − X1 );
i =1

64
{Y ′}=Y1 + k∑−1µi (Yi +1 −Y1 );
i =1
где λi и µi – коэффициенты пропорциональности.
Для доопределения этих функций на подмножествах { X ′} и {Y ′} введем дополнительно две гипотезы.
I. Преобразование X ′→Y ′ линейно. Тогда для удовлетворения соответствия (4.2) следует положить
λi = µi , i =1,k −1.
II. Каждому вектору X {X} ставится в соответствие такой вектор
X ′ {X ′}, который доставляет минимум функции близости:
Φ(X , X ′)= 
 X − X ′
X − X ′
 2 .
2 .
Таким образом, сформулируем полученный алгоритм решения задачи:
•преобразуем {X} →{X ′} (гипотеза 2);
•отображаем {X ′} →{Y′} (гипотеза 1);
•отождествляем {Y′} ≡{Y}.
Проиллюстрируем идею метода на простом примере двумерного пространства ситуаций.
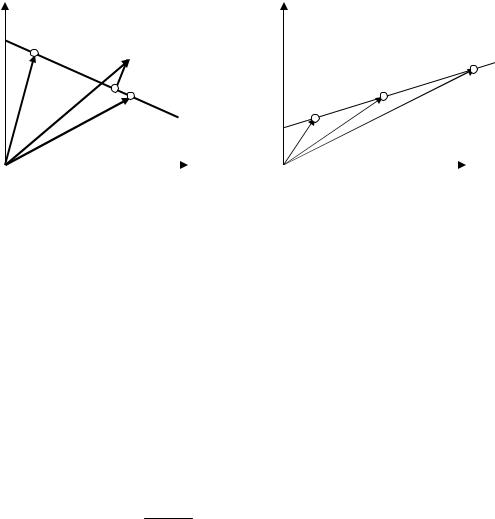
Для построения алгоритма экстраполяции введем два линейных параметризованных пространства (рис. 4.1): двумерное пространство ситуаций
X, где каждая ситуация определяется парой параметров x1 и x2 , и пространство решений Y, в котором каждое решение определяется двумя параметрами: y1 и
y2 .
Предположим, что известны две проектные ситуации X1 и X 2 , которым в пространстве решений соответствуют решения Y1 и Y2 .
|
|
|
65 |
|
|
Задача ставится следующим образом: дана проектная ситуация X3 и |
|||||
нужно найти для нее решение Y3 , располагая только указанной ситуацией. |
|||||
x2 |
|
|
y2 |
|
|
X1 |
|
X3 |
|
Y2 |
|
|
|
|
{Y′} |
||
|
|
X3′ |
Y3 |
||
|
|
|
|
||
|
|
X2 |
Y1 |
|
|
|
|
{X} |
|
|
|
|
а) |
x1 |
б) |
y1 |
|
|
|
|
|
||
Рис. 4.1. Графическая интерпретация нахождения: а) проектной ситуации X3 ; б) |
|||||
|
проектного решения Y3 , соответствующего ситуации X3 |
||||
Через известные ситуации проводим прямую линию, являющуюся подпространством проектных ситуаций { X ′}, через точки Y1 и Y2 – линию,
являющуюся подпространством решений {Y ′} (рис. 4.1). Для новой проектной ситуации X3 определим ближайшую точку на подпространстве ситуаций, для чего опустим перпендикуляр из точки X3 на линию X1 X 2 . Получим точку
X 3′, являющуюся отображением точки X3 на подпространстве ситуаций,
которая делит отрезок X1 X 2 в определенной пропорции. Разделив отрезок
Y1Y2 в подпространстве {Y ′} в этой же пропорции, получим проектное решение Y3 , соответствующее ситуации X3 .
В соответствии с изложенным алгоритмом подпространства ситуаций и решений находим { X ′}, {Y ′}по следующим формулам
{X ′} = X1 + λ(X 2 − X1 );
{Y′} =Y1 + µ(Y1 −Y2 ),
где λ и µ – коэффициенты пропорциональности.
Так как λ= µ , то
Y3 = Y1 + µ(Y2 − Y1 ),

66
где µ определяется, исходя из минимума функции близости.
Решение в числовом виде рассмотрим на основе модельного примера в
трехмерном пространстве. |
X1 (2,0; 3,0; 1,5)и X 2 (4,0; 4,5 ; 2,7), |
|||||
Имеются две проектные функции: |
||||||
для которых известны решения Y1 = 34,5 и Y2 = 49,9. Необходимо найти новое |
||||||
решение Y3 для ситуации X3 (5,5; 6,0; 4,0). |
|
|||||
Условия задачи приведены в табл. 4.1. |
|
|||||
|
|
Таблица 4.1. Условия задачи |
|
|||
|
|
|
|
|
|
|
Yi |
Xi |
|
x1 |
|
x2 |
x3 |
34,5 |
X1 |
|
2,0 |
|
3,0 |
1,5 |
49,9 |
X2 |
|
4,0 |
|
4,5 |
2,7 |
65,0 |
X3 |
|
5,5 |
|
6,0 |
4,0 |
Значение Y3 , определенное по заданному тест-базису, используем для оценки погрешности метода экстраполяции.
Так как {X ′} = X 1 + λ(X 2 − X 1 ), то
{X ′}= {[2,0 + λ(4,0 − 2,0)];[3,0 + λ(4,5 −3,0)];[1,5 + λ(2,7 −1,5)]}= = {(2 + 2λ);(3 +1,5λ)(1,5 +1,2λ)}.
Вводим в рассмотрение функцию близости:
Φ(X ′, X 3 )2 = [(2 + 2λ −5,5)2 + (3 +1,5λ − 6,0)2 + (1,5 +1,2λ − 4,0)2 ] = = (2 −3,5λ)2 + (1,5λ −3)2 + (1,2λ − 2,5)2 .
Минимизируем функцию близости, для чего определим ее производную по параметру λ:
∂∂Φλ = 7,69λ −14,5 = 0,
откуда λ =1,88.
Y3 = Y1 + λ(Y2 −Y1 )= 34,5 +1,88(49,9 −34,5)= 63,5.
Таким образом, оценка погрешности для данного примера δ = 2,35 %.
Рассмотрим пример в пятимерном пространстве.

67
Исследователю известно три ретроспективные ситуации: X1 , X 2 , X 3 ,
для которых известны выходные характеристики системы. Требуется найти оптимальную выходную характеристику системы для новой ситуации X 4 ,
Условия задачи приведены в табл. 4.2.
Как и в предыдущем примере, полагаем, что в ситуации X 4 известно точное значение выходной характеристики системы.
Решим задачу в двух вариантах. Вначале воспользуемся информацией по двум проектным ситуациям: X1 и X 2 .
Алгоритм решения задачи аналогичен рассмотренному ранее, то есть вначале составляем подпространство известных ситуаций:
{X ′}= {(2 + λ),(1 +1,5λ),(1,5 + 2λ),(2,5 + 0,5λ),(1 + λ)}.
Формируем квадратичную функцию близости новой ситуации к подпространству {X ′}:
Φ(X ′, X 4 )= (λ −5)2 +(1,5λ −7)2 + (2λ − 4,5)2 +(0,5λ −6,5)2 + (λ − 4)2 .
Таблица 4.2. Исходные данные
Yi |
X i |
x1 |
x2 |
x3 |
x4 |
x5 |
19,75 |
X1 |
2,0 |
1,0 |
1,5 |
2,5 |
1,0 |
39,00 |
X 2 |
3,0 |
2,5 |
3,5 |
3,0 |
2,0 |
47,25 |
X 3 |
4,0 |
3,5 |
5,0 |
5,0 |
3,0 |
85,50 |
X 4 |
5,0 |
8,0 |
6,0 |
6,0 |
5,0 |
Минимизируем квадратичную функцию близости, для чего находим производную по λ и приравниваем ее к нулю:
∂∂Φλ = 8,5λ −3175 = 0 .
Решая уравнение, находим параметр λ = 3,735.
По формуле экстраполяции, отождествляя λ = µ , находим выходную

68
характеристику системы в проектной ситуации X 4 :
Y4 = Y1 + λ(Y2 −Y1 )= 69,24 .
Зная точное значение выходной характеристики системы, оцениваем относительную погрешность экстраполяции δ =19,1 %.
Решим эту же задачу, используя более полную информацию – проектные ситуации X1, X 2 и X 3 .
Как и в первом случае, составляем подпространство известных ситуаций:
{X ′}={(2+λ1 +2λ2 )(,1+1,5λ1 +2,5λ2 )(,1,5+2λ+3,5λ2 ), (2,5+0,5λ1 +2λ2 )(,1+λ1 +2λ2 )},
вводим квадратичную функцию близости новой ситуации X 4 к
подпространству {X ′}:
Φ(X ′,X 4 )= (λ1 + 2λ2 −5)2 +(1,5λ1 +2,5λ2 −7)2 +(2λ1 +3,5λ2 −4,5)2 + +(0,5λ1 + 2λ2 −6,5)2 +(λ1 +2λ2 −4)2 .
Минимизируем функцию близости, для чего приравниваем производную по переменным параметрам λ1 и λ2 к нулю:
∂Φ = 8,5λ1 +15,75λ2 −31,75 = 0;
∂λ1
∂Φ =15,75λ1 + 30,5λ2 −64,25 = 0 .
∂λ2
Решая систему уравнений, находим переменные параметры λ1 и λ2 ,
минимизирующие функцию близости:
λ1 = 4,39 ; |
λ2 = 4,38 . |
Построив подпространство решений по формуле
Y4 = Y1 + µ1 (Y2 −Y1 )+ µ2 (Y3 −Y1 )
и вводя тождества λ1 = µ1 , λ2 = µ2 , находим
Y4 = 83,25.
69
Используя точное значение модельной задачи, оценим относительную погрешность экстраполяции δ = 2,7 %.
Сравнивая результаты экстраполяции характеристик системы X 4 по двум и по трем аналогам, видим, что погрешность экстраполяции снизилась с
19,1 до 2,7 %.
Таким образом, рассмотренный метод применим для восстановления линейной функции в случае малого числа наблюдений.
Если восстанавливаемая функция нелинейна, метод можно применять при любом числе наблюдений. В этом случае значение функции в новой ситуации определяется не по всем имеющимся наблюдениям, а лишь по ближайшим к новой ситуации. В результате осуществляется локально-линейное приближение нелинейной функции.
Кроме задач прогнозирования, метод применим для восстановления числовых таблиц, для оценки числовых характеристик функций, для решения задач квалиметрии и тому подобных.
В табл. 4.3 представлены в относительных единицах (по отношению к характеристикам «Онест Джон») тенденции роста качественных характеристик основных элементов, а также технического уровня летательных аппаратов США.
Таблица 4.3. Тенденции роста качественных характеристик РК
|
Год |
|
Элементы летат. аппарата |
|
Технический |
|||||
Наименование ЛА |
СУ |
|
БЧ |
ДУ |
Корпус |
x4 |
||||
принятия |
x |
|
x |
|
x |
3 |
материала |
уровень Q |
||
|
|
1 |
|
|
2 |
|
|
|
||
«Онест Джон» |
1950 |
1 |
|
1 |
1 |
1 |
|
1 |
||
«Ланс» |
1970 |
4 |
|
3 |
3 |
2 |
|
4 |
||
«Ланс-2» |
1990 |
10 |
|
8 |
6 |
5 |
|
8 |
||
Единая система |
2010 |
15 |
|
12 |
8 |
7 |
|
12 |
||
В качестве контрольного для проверки точности алгоритма используем значение Q4 =12.
|
|
|
70 |
|
|
Таким образом, имеются три альтернативы A1 (1,1,1,1), |
A2 (4,3,3,2) |
и |
|||
A3 (10,8,6,5), для которых найдены значения обобщенного показателя Q1 |
=1, |
||||
Q2 = 4 и Q3 |
= 8. |
|
|
|
|
Необходимо определить показатель технического уровня системы с |
|
||||
параметрами A4 (15,12,8,7). |
|
|
|
||
Формируем подпространство известных ситуаций: |
|
|
|||
′ |
|
k −1 |
|
+ 2λ1 + 7λ2 ); |
|
{X }= X1 + ∑λi (X i+1 |
− X1 ) = {(1 +3λ1 + 9λ2 );(1 |
||||
|
|
i=1 |
|
|
|
(1 + 2λ1 + 5λ2 );(1 + λ1 + 4λ2 )}.
Определим квадратичную функцию близости новой ситуации к подпространству {X ′}:
Φ(X ′, X 4 )= 
 X ′− X 4
X ′− X 4 
 2 = (3λ1 + 9λ2 −14)2 + (2λ1 + 7λ2 −11)2 +
2 = (3λ1 + 9λ2 −14)2 + (2λ1 + 7λ2 −11)2 +
|
+ (2λ +5λ |
2 |
− 7)2 + (λ + 4λ |
2 |
−6)2 . |
|||||||||
|
|
1 |
|
|
|
|
|
|
1 |
|
|
|
||
Решая систему уравнений, находим параметры, минимизирующие |
||||||||||||||
функцию близости: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
λ1 = −0,868; |
|
|
|
|
|
λ2 =1,811. |
|
||||||
Построив подпространство решений по формуле |
||||||||||||||
|
Qэ |
= Q + µ |
1 |
(Q |
2 |
−Q )+ µ |
2 |
(Q −Q ) |
||||||
|
4 |
1 |
|
|
|
|
1 |
|
3 |
|
1 |
|||
и вводя тождества λ1 = µ1 , |
λ2 |
= µ2 , находим экстраполированную |
||||||||||||
характеристику уровня альтернативы A |
Qэ =11,073, определяем |
|||||||||||||
|
|
|
|
|
|
|
|
|
4 |
4 |
|
|
|
|
относительную погрешность экстраполяции δ = 7,7 %. |
||||||||||||||
При предположении, что восстанавливаемая функция нелинейна, |
||||||||||||||
используем лишь ближайшие лишь к новой ситуации наблюдения, то есть A2 и |
||||||||||||||
A3 . Тогда |
(X |
2 , X 3 )= {(4 + 6λ), (3 + 5λ), (3 + 3λ), (2 + 3λ)}, |
||||||||||||
{X }= X |
||||||||||||||
′ |
′ |
|
|
|
|
|
|
|
|
|
|
|
|
|
71
минимизируя
Φ(X ′, X 4 )= (6λ −11)2 + (5λ −11)2 + (3λ −5)2 + (3λ −5)2 ,
получим λ =1,911.
Решение для ситуации A4 находим по экстраполяционной формуле
Q4э = Q2 + λ(Q3 −Q2 )= 4 +1,911(8 − 4)=11,644 .
В этом случае относительная погрешность экстраполяции δ = 2,97 %.
При решении методом пропорционального сдвига
{X ′}= p[X 1−λ(X 2 − X1 )]= p[(4 + 6λ), (3 + 5λ), (3 + 3λ), (2 + 3λ)];
Φ(X ′− A4 )= (4 p + 6λp −15)2 + (3 p + 5λp −12)2 + (3 p + 3λp −8)2 +
+(2 p + 3λp − 7)2 .
Минимизируя эту функцию по p и λ, получим p = 0,7 ; λ = 3,2 . Тогда
для ситуации A4
Q4э = p[Q2 + λ(Q3 −Q2 )]= 0,7[4 +3,2(8 − 4)]=11,76; δ =2 %.
Таким образом, алгоритм многомерной линейной экстраполяции позволяет с удовлетворительной точностью восстанавливать неизвестный обобщенный показатель прогнозируемой альтернативы объекта в условиях малого числа наблюдений.