

Применение мобильных агентов в системах обработки текстовой информации.
Наиболее перспективным представляется применение технологии мобильных агентов на этапе поиска и доставки информации в клиентскую систему. В настоящее время существует достаточно большое число программ, выполняющих эту функцию, которые называются web-роботы. В процессе работы они перемещается по гипертекстовой структуре Сети, запрашивают документы и рекурсивно возвращают все документы, на которые они ссылаются. Эти программы также иногда называют "пауками", "странниками", или "червями". Такие названия, несмотря на их привлекательность, могут ввести в заблуждение, поскольку термин "паук" и "странник" создает ложное представление, будто робот сам перемещается, а термин "червь" мог бы подразумевать, что робот еще и размножается подобно вирусу-червю. В действительности, роботы реализованы как простая программная система, которая запрашивает информацию из удаленных участков интернет, используя стандартные сетевые протоколы.
Придумано много способов обмана поисковых агентов и роботов, благодаря которым они привлекаются на web-сервер для придания ему высокого имиджа. Например, в неотображаемых стандартными браузерами участках страниц записываются привлекающие агентов ключевые слова, чаще всего в нескольких экземплярах. Для обхода таких ловушек требуется оснащать поисковые агенты специальными средствами анализа обрабатываемых страниц.
Отбор информации
Главный недостаток современных web-роботов заключается в том, что анализ документа, хранящегося на удаленном сервере, производится на сервере, на котором поисковая система работает. Несмотря на применение прогрессивных методов пересылки файлов, такой механизм работы существенно повышает трафик сети и нагрузку на узлы, на которых хранится информация. Большинство таких программ осуществляют обход строго определенного набора узлов интернет с ограниченным уходом в глубину ссылок. Ситуация осложняется тем, что размеры html-файлов, в которых хранятся тексты, становятся все больше и больше а объем содержащейся в них полезной информации остается прежним.
Наиболее естественным выходом из сложившейся ситуации является перенос процедуры принятия решения "документ должен быть перенесен в клиентскую систему на обработку или нет" на сервер, на котором документ хранится или на ближайший к нему (с точки зрения сетевого расстояния). Серьезное преимущество мобильных агентов заключается в возможности осуществлять отбор искомой информации непосредственно на сервере, на котором она находится, избегая загрузки сети пересылкой не представляющих интереса документов для их оценки.
Очевидно, большинство клиентских систем не будет поддерживать таких дорогостоящих операций как морфологический и синтаксический анализ документов, особенно русскоязычных. По этой причине представляется сомнительной возможность проведения качественного семантического анализа русскоязычных документов непосредственно самим мобильным агентом, следовательно, и точность отбора не может быть высокой. Наиболее рациональным представляется "черновой", избыточный отбор информации мобильными агентами по ключевым словам и ее последующий полноценный анализ в системе обработки текстов.
Извлечение информации из специализированных хранилищ
При организации большого хранилища документов наступает момент, когда хранение документов в виде html-файлов становится невыгодным или даже невозможным. В этих случаях документы начинают хранить в полях СУБД и извлекать те из них, которые потребовал пользователь в открытые каталоги web-сервера на некоторое время, обычно не больше часа. Естественно, обычные поисковые роботы не могут получить все документы из таких хранилищ, а те которые случайно захватываются, сразу становятся "мертвыми" ссылками. С помощью технологии мобильных агентов может быть решена проблема извлечения таких документов. Например, мобильный агент может отслеживать появление временных файлов и пересылать их в "зеркало" обрабатываемого хранилища. Естественно, такому агенту не помешает способность исключения повторной пересылки одного и того же документа. Подобный агент может работать в паре с другим агентом, который имитирует работу пользователя провоцируя создание временных файлов.
Термин "хранилище данных" можно представить в виде объединения двух основных идей: интеграция разобщенных данных в едином хранилище (например, данные о браке на производстве или параметрах выпускаемых деталей) и разделение наборов данных и приложений для обработки и анализа.
Хранилище данных необходимо для единого доступа данным, например, у вас имеется производственный процесс, когда выход с одного цеха подается на вход другого цеха, при этом необходимо обеспечить беспрепятственный обмен данными между ними.
Для менеджеров по контролю качества и инженеров в свою очередь требуется система, которая позволяет: проводить анализ с учетом временных рамок, формирование произвольных запросов к системе, обрабатывать большие объемы данных, объединять данных с различных систем (например, из нескольких цехов). Простые регистрирующие системы не удовлетворяют этим требованиям - информация в регистрирующей системе актуальна только на момент подачи запроса, а в другой момент времени данные уже совершенно иные. Регистрирующие системы обычно рассчитаны на проведение жестко ограниченных операций, и создание нерегламентированного запроса могло поставить эту систему в тупик. Также были весьма ограничены возможности обработки больших массивов информации.
Хранилище данных
Хранилище данных - это "предметно-ориентированная, интегрированная, содержащая исторические данные, неразрушаемая совокупность данных, предназначенная для поддержки принятия управленченских решений". Одним из первых это определение дал Уильям Инмон в своей монографиии. Схему хранилища данных можно представить следующим образом:
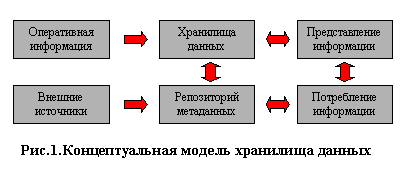
Рис.1. Схема хранилища данных
Данные из различных источников помещаются в хранилище, а их описания — в репозиторий метаданных. Конечный пользователь с помощью различных инструментов может анализировать данные в хранилище. Результатом является информация в виде готовых отчетов, найденных скрытых закономерностей, каких-либо прогнозов. Так как средства работы конечного пользователя с хранилищем данных могут быть самыми разнообразными, то теоретически их выбор не должен влиять на структуру хранилища и функции его поддержания в актуальном состоянии. Физическая реализация данной схемы может быть самой разнообразной.
Рассмотрим первый вариант - виртуальное хранилище данных, это система, предоставляющая доступ к обычной регистрирующей системе, которая эмулирует работу с хранилищем данных. Виртуальное хранилище можно организовать двумя способами. Можно создать ряд "представлений" (view) в базе данных или использовать специальные средства доступа к базе данных (например, продукты класса desktop OLAP).
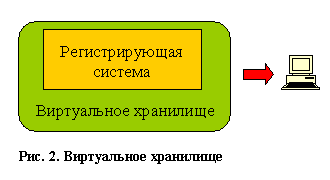
Рис.2. Виртуальное хранилище
Теперь рассмотрим основные преимущества и недостатки виртуальных хранилищ. Преимущества: простота и малая стоимость реализации, единая платформа с источником информации, отсутствие сетевых соединений между источником информации и хранилищем данных. Недостатков больше: работаем всего лишь с иллюзией хранилища данных, остаются проблемы с производительностью, трансформацией данных, интеграцией данных с другими источниками, отсутствием истории, чистотой данных, зависимость от доступности и структуры основной базы данных.
Поскольку конструирование хранилища данных — сложный процесс, который может занять несколько лет, некоторые организации вместо этого строят витрины данных (data mart), содержащие информацию для конкретных подразделений. Например, маркетинговая витрина данных может содержать только информацию о клиентах, продуктах и продажах и не включать в себя планы поставок. Несколько витрин данных для подразделений могут сосуществовать с основным хранилищем данных, давая частичное представление о содержании хранилища. Витрины данных строятся значительно быстрее, чем хранилище, но впоследствии могут возникнуть серьезные проблемы с интеграцией, если первоначальное планирование проводилось без учета полной бизнес-модели. Это второй способ.
Двухуровневая архитектура хранилища данных подразумевает построение витрин данных (data mart) без создания центрального хранилища, при этом информация поступает из регистрирующих систем и ограничена конкретной предметной областью. При построении витрин используются основные принципы построения хранилищ данных, поэтому их можно считать хранилищами данных в миниатюре.

Рис.3. Двухуровневая структура хранилища
Плюсы: простота и малая стоимость реализации; высокая производительность за счет физического разделения регистрирующих и аналитических систем, выделения загрузки и трансформации данных в отдельный процесс, оптимизированной под анализ структурой хранения данных; поддержка истории; возможность добавления метаданных.
Построение полноценного корпоративного хранилища данных обычно выполняется в трехуровневой архитектуре. На первом уровне расположены разнообразные источники данных — внутренние регистрирующие системы, справочные системы, внешние источники (данные информационных агентств, макроэкономические показатели). Второй уровень содержит центральное хранилище, куда стекается информация от всех источников с первого уровня, и, возможно, оперативный склад данных, который не содержит исторических данных и выполняет две основные функции.
Во-первых, он является источником аналитической информации для оперативного управления и, во-вторых, здесь подготавливаются данные для последующей загрузки в центральное хранилище. Под подготовкой данных понимают их преобразование и проведение определенных проверок. Наличие оперативного склада данных просто необходимо при различном регламенте поступления информации из источников. Третий уровень представляет собой набор предметно-ориентированных витрин данных, источником информации для которых является центральное хранилище данных. Именно с витринами данных и работает большинство конечных пользователей.
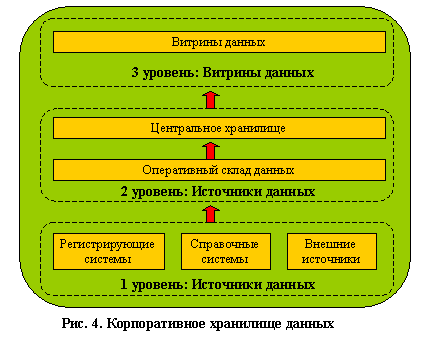
Рис.4. Корпоративное хранилище данных
Специалисты в области информационных технологий решают проблемы создания систем поддержки принятия решений (СППР, систем ППР) уже около 20 лет. Так, в начале 80-х гг эти проблемы решались с помощью информационного центра. При этом сотрудники информационного центра занимались подготовкой для ЭВМ копий данных организации в соответствии с фиксированным форматом и запуском специализированных программ, формирующих отчеты по запросам конечных пользователей. Этот метод был достаточно успешным и применялся до тех пор, пока не появились реляционные СУБД (РСУБД) и их навигационный язык - структурированный язык запросов SQL. С помощью РСУБД очень легко обрабатывать запросы, а SQL позволяет пользователю напрямую обращаться к БД и получать необходимую информацию тогда, когда это требуется. Теперь нет необходимости договариваться с информационным центром о том, какие данные можно было бы получить и какой протокол экспорта возможно использовать. Недостатком данного подхода является требование хорошей подготовки пользователя, так как для выполнения неудачно сформулированного запроса могут потребоваться многие часы машинного времени.
Чтобы удовлетворить непрерывно растущие потребности в информации, усиливается инвестирование в область создания БД, отделенных от оперативных БД производства, для выполнения запросов, требующих аналитической обработки больших массивов данных. Понятие отдельной БД для поддержки работы инженера по знаниям было новым и получило название «информационного хранилища» (по терминологии IBM) или «хранилища данных» (терминология W.H. Inmon ). Хранилище данных - это ориентированное на предметную область, интегрированное, устойчивое собрание данных для процесса поддержки принятия решений. На основе хранилища может быть легко получен репозиторий непротиворечивых исторических данных, пригодный для поддержки принятия решений.
Как правило, жизненный цикл технологии составляет примерно 9 лет и включает 3 основные стадии : нововведение, развертывание и завершенность. На протяжении первых трех лет - фазы нововведения - потребителями новой технологии становятся лишь немногие энтузиасты и сторонники. Для технологии хранилищ данных эта фаза началась с публикации в 1991 г. книги Билла Инмона «Построение хранилища данных». Он создал теоретический фундамент для хранилищ данных, определив их характеристики и подходы к построению. Сегодня технология хранилищ данных переживает фазу развертывания и подходит к началу третьей фазы развития, когда технология становится общепризнанной. Основная проблема при переходе к третьей фазе состоит в дороговизне проектов хранилищ. Так, обзор консалтинговой компании META Group за 1998 г. показал, что, в среднем, для поддержки хранилищ данных требуется около 1.8 млн. долл. на технические средства и около 1.4 млн. долл. на программные средства. Если ситуация не изменится, то большой сегмент рынка останется неохваченным и технология хранилищ данных никогда не достигнет третьей фазы развития.
Возможно, выход будет найден. Например, специалисты из исследовательской компании Gartner Group утверждают, что «Наибольшая выгода от использования технологии хранилищ данных достигается тогда, когда Вы можете поддерживать 20 различных приложений ППР на одной и той же архитектуре».
Некоторые эксперты утверждают , что извлечение данных (data mining, DM) - наиболее важное приложение технологии информационных хранилищ. Извлечение данных предполагает выявление скрытой предсказывающей информации из больших БД. В своем отчете специалисты из Gartner Group относят DM к 5 передовым технологиям, которые будут оказывать существенное влияние на широкий спектр областей промышленности в течение ближайших 3 - 5 лет. В свою очередь, META Group предсказывает рост дохода от внедрения новых инструментов DM от 3.3 билл. долл. в 1996 году до 8.4 билл. долл. в 2000 году.
В настоящем обзоре, посвященном извлечению данных, рассматриваются как вопросы, касающиеся самой технологии DM (архитектура СППР, алгоритмы DM, основные направления исследований), так и связи ее с другими технологиями (OLAP). Так как технологии DM и хранилищ данных являются передовыми и бурно развивающимися, то на сегодняшний день еще не определена устоявшаяся терминология. Более того, продолжаются споры исследователей о связи DM и СППР, DM и OLAP. Поэтому, не претендуя на полноту изложения, попытаемся нарисовать общую картину, сложившуюся в области DM, используя последние данные зарубежных исследований.
Технологические критерии:
Так как DM работает с данными из хранилища, рассмотрим сначала технологические критерии, которые необходимо учитывать при разработке системы хранилища данных. Они включают следующие:
1. Масштабируемость - это способность системы увеличивать производительность при росте требований пользователя, наращивать объем хранимых данных при увеличении количества пользователей системы и приложений, использующих хранилище.
2. Управляемость. Технология хранилищ данных требует развития и реализации новых процессов, инструментов и рабочих систем для управления извлечением, трансформацией оперативных данных, администрированием пользователей и т.п. Необходимо определить условия для поддержки управления.
3. Исполнение. От того, насколько хорошо будет реализована система, главным образом, зависит успех проекта. Существует несколько областей, накладывающих непосредственный отпечаток на представление системы: архитектура технических средств и базы данных. Технические средства предполагают использование архитектур симметричной мультиобработки (SMP) и массово-параллельной обработки (MPP). Тем не менее, существует много приложений, которые могут удовлетворительно работать на непараллельных системах. Некоторые разработчики баз данных решили поддержать архитектуру технических средств, введя параллелизм в функции БД.
4. Гибкость. Технология хранилищ данных должна быть гибкой, чтобы своевременно реагировать на изменяющиеся условия.
5. Соотношение ‘простота - скорость’ для реализации. Средства развития и поддержки, используемые вместе с хранилищами данных, являются ключом к успеху проекта. Хорошо ли интегрированы эти средства, или группе сопровождения придется бороться с их несовместимостью? Являются ли интерфейсы пользователя графическими или командными? Генерируется ли автоматически состав метаданных? Эти вопросы касаются не только исходной разработки, но и последующего сопровождения системы.
6. Интеграция инструментов предполагает хорошее и бесперебойное взаимодействие различных архитектурных компонентов. Как утверждается в журнале Datamation, «иметь хорошо и глубоко интегрированные друг с другом инструментальные средства - это необходимость, а не роскошь».
7. Полнота решения говорит о наличии всех архитектурных компонентов. Это означает, что все элементы архитектуры, необходимые для работы, реализованы и функционируют: извлечение, преобразование и хранение данных; метаданные, определяющие основные данные; требуемые аналитические и управляющие процессы.
Архитектура систем ППР:
Основу систем ППР (планово-предупредительного ремонта) составляют средства для быстрого и надежного анализа и визуализации деловой информации, а также набор инструментов, необходимых для синтеза информации с целью получения новых знаний об управляемой системе и выработки управляющих решений.
Системы ППР состоят их следующих архитектурных элементов (Рис. 1):
· хранилище информации (массив данных и знаний);
· средства управления данными (накопление, хранение, оперирование, защита и т.д.);
· средства анализа (извлечения) данных - Data mining (аналитическая обработка данных);
· средства синтеза управляющих решений (моделирование, прогнозирование, оптимизация, анализ альтернатив и т.д.).
Базовый набор инструментов систем ППР обычно включает в себя широкий ассортимент средств статистического анализа данных, средства выявления тенденций и прогнозирования, а также функции моделирования, агрегирования и объединения данных, и, наконец, средства оптимизации управляющих решений.
Так как организация хранилища данных очень важна как для успешной реализации всей СППР в целом, так и для проведения анализа данных, то рассмотрим более подробно архитектуру хранилища. По утверждению Билла Инмона, существует два наиболее общих типа информационных хранилищ: текущее хранилище с подробными данными и витрина (datamart). В текущем хранилище собираются разрозненные атомарные данные, и оно имеет очень большой объем. Для витрины характерно хранение специальных данных, необходимых для решения конкретных задач (например, одного департамента). В отмечается, что для большинства проектов разработка многоуровневого хранилища уже стала общепризнанным архитектурным решением.
Многоуровневость - это архитектурное решение проблемы контроля стоимости управления хранилищем в условиях неустойчивого информационного окружения. Базовая структура хранилища (Рис. 2) включает три составляющие:
1. Система записи (слой-источник) - это исходная система, из которой извлекаются ряды данных для хранилища. Обычно эти источники либо вертикальные интегрированные OLTP-системы, либо данные третьей стороны.
2. Базовый слой хранилища - это общий фонд данных, содержащий интегрированные и рационализированные данные из системы записи. Данные здесь хранятся в соответствии с семантикой и представляются в исторической последовательности.
3. Слой доступа к хранилищу - это слой выдачи данных, где система хранилища встречается с пользователями и их ППР-приложениями. Структуры данных могут варьироваться от стратегических данных для очень устойчивых предметных областей (домен схем типа ‘звезда’) до многомерных БД, определяемых спецификой проекта. Основные свойства уровня - понятность для делового пользователя и легкость доступа.
Как утверждается в, существует все увеличивающаяся пропасть между мощными системами хранения данных и способностью пользователей эффективно анализировать и воздействовать на информацию, которую они содержат. Требуется новый технологический скачок для структурирования и упорядочения информации в соответствии со специфическими задачами пользователя. Для этого и предназначены инструменты DM, которые наиболее эффективны при наличии интеграции с существующими информационными системами. К сожалению, сегодня многие инструменты DM действуют вне информационных хранилищ, требуя выполнения дополнительных шагов извлечения, импорта и анализа данных. Предлагается интегрированная архитектура для анализа данных из хранилища. Она связывает на основе тесного взаимодействия хранилище, OLAP-сервер и систему DM. Такая архитектура сильно отличается от традиционных СППР. Вместо того, чтобы просто направлять данные к конечному пользователю через программы подготовки отчетов и запросов, модели применяются непосредственно к данным хранилища и возвращаются результаты анализа наиболее подходящей информации. Эти результаты позволяют улучшить метаданные в OLAP-сервере, создавая слой динамических метаданных. Отчеты и визуализация оказываются полезными при планировании будущих действий.
Извлечение данных: определения, назначение
По существу, процесс извлечения (анализа) данных является частью более общего процесса, называемого принятием решений, и в силу этого служит для трансформации данных, хранимых в информационных хранилищах или витринах, в информацию, помогающую принять правильное решение. DM получило свое название благодаря сходству поиска значимой информации в больших БД и добычи в горе жилы ценной руды. Оба процесса требуют либо ‘просеивания’ огромного количества материала, либо ‘зондирования’ для определения точного местоположения искомого объекта.
Приведем несколько определений процесса извлечения данных. Традиционно цель определения и использования информации, скрытой в данных, достигалась с помощью генераторов запросов и систем, интерпретирующих данные. В этом случае необходимо было сформулировать предположение о возможном отношении в БД и перевести эту гипотезу в запрос. Данный подход к анализу данных являлся ручным, управляемым пользователем, нисходящим. В процессе DM запрос выполняется самим алгоритмом, а не пользователем, то есть извлечение данных - это управляемый данными, самоорганизующийся, восходящий подход к анализу. Более развернутое определение можно найти в : «В ходе извлечения данных осуществляется попытка сформулировать, проанализировать и выполнить основные процессы индукции, упрощающие извлечение содержательной информации и знаний из неструктурированных данных». DM полуавтоматически извлекает образцы, изменения, ассоциации и аномалии из больших массивов данных. Таким образом, DM пытается извлечь знания из данных. Заметим, что под большими массивами данных понимаются такие множества, которые слишком велики, чтобы находиться в памяти одной рабочей станции.
По сути, DM обнаруживает образцы и связи, скрытые в данных. DM - часть процесса обнаружения знаний, которая состоит в применении к данным методов статистического анализа и моделирования, чтобы найти полезные образцы и связи. Процесс обнаружения знаний описывает шаги, которые необходимо предпринять, чтобы получить результаты, имеющие смысл.
Средства извлечения данных используют данные для построения модели реального мира. В результате моделирования создается описание образцов и связей данных. Пользователь может использовать эти модели двумя способами:
1) описание образцов и связей в БД может предоставлять знания, направляющие действия пользователя (ассоциативные модели);
2) образцы могут быть использованы для предсказаний.
Извлечение данных применяется для построения моделей шести типов:
1) классификация;
2) регрессия;
3) временные ряды;
4) кластеризация;
5) анализ ассоциаций;
6) обнаружение закономерностей.
При этом модели типов 1, 2 и 3 применяются прежде всего для предсказания, модель 4 используется как для прогнозов, так и для описания, а модели 5 и 6 - прежде всего для описания поведения, определяемого данными БД. Приведем краткое описание этих моделей в соответствии с.
Классификация назначает примеры (типы) группе или классу. Существующие типы, используемые для поиска классификационного образца, могут находиться в исторической БД. Они также могут быть получены в ходе эксперимента, в котором часть исходной БД тестировалась в реальном мире, и результаты используются для создания классификационного множества данных, по которому может быть разработана модель.
Регрессия использует ряды существующих значений и их атрибуты для предсказания последующих значений.
Предсказание временных рядов, подобно регрессии, использует ряды существующих значений и их атрибутов для предсказания будущих значений. Отличие же состоит в том, что эти значения зависят от времени. Инструменты могут использовать различные свойства времени, особенно иерархию периодов, сезонность, календарные эффекты, арифметику дат, специальные соглашения вроде того, какой период прошлого влияет на будущее.
Кластеризация разбивает БД на различные группы. В отличие от классификации, заранее не известны кластеры, с которых начнется процесс, или вокруг каких атрибутов будут собираться данные. Следовательно, аналитику необходимо интерпретировать смысл кластеров.
Ассоциации - объекты, появляющиеся одновременно в данном событии или записи. Инструменты ассоциаций и упорядочения обнаруживают правила вида: «Если объект А - часть события, то в x процентах случаев объект B - часть этого события».
Обнаружение закономерностей тесно связано с анализом ассоциаций за исключением того, что связанные объекты имеют протяженность во времени. Чтобы обнаруживать эти последовательности, должны учитываться детали каждой транзакции наряду с идентификацией участников транзакций.
Средства и методы извлечения данных:
С появлением информационных хранилищ анализ данных потребовал систематического подхода. По мнению Gartner Group, извлечение данных не есть некий аналитический метод, а скорее процесс, вбирающий в себя много методов и приемов, подобранных под специфику прикладной области. Как отмечается в, из-за сложности и разнообразия данных, находящихся в разработанных хранилищах, единственный метод извлечения данных недостаточен для решения каждой задачи, даже связанной с построением одной конкретной модели. Поэтому приходится комбинировать несколько методов анализа. Алгоритмы и методы DM включают: нейронные сети, деревья решений (алгоритмы CART - классификационные и регрессионные деревья, и CHAID - автоматическое c2-выявление взаимосвязей), индукция правил (извлечение полезных ‘если - то’ правил из данных, основанное на статистической значимости), генетические алгоритмы, метод ближайшего соседа (классифицирует каждую запись из множества данных по основным комбинациям классов из k-записей исторической БД, наиболее похожих на нее), кластеризация, регрессия (линейная и логистическая), анализ временных рядов, обнаружение ассоциаций, сегментация БД. Кроме того, активно используются алгоритмы визуализации как самостоятельно, так и для улучшения результатов, полученных с помощью других алгоритмов.
Для любой конкретной задачи природа самих данных влияет на выбор метода анализа. Поясним это на примере решения задач классификации и кластеризации. Для этих задач широко используются как нейронные сети, так и символьные классификаторы, известные также как программы индукции правил или деревьев решений. Оба метода автоматически исследуют данные для поиска кластеров или образцов. Оба разбивают множество данных на значимые группы или классы. Различные по построению, оба типа основываются на индуктивной теории (обучение на примерах) и выполняют сходную работу над БД. Они разбивают или классифицируют независимые переменные по отношению к зависимым переменным или требуемому результату. Эти инструменты основываются на понятии, известном как управляемое обучение.
Но в то же время можно заметить существенные различия в применении методов. Нейронные сети требуют большого количества экспериментов и проверок, таких как установка верного числа узлов, критерия останова, обучающей выборки, импульсных коэффициентов и скрытых весов. Однако с помощью использования генетических алгоритмов для оптимизации этих установок можно повысить точность выходных данных для нейронных сетей. Другое ограничение, касающееся нейронных сетей, состоит в том, что они работают только с числами или бинарными данными. Часто требуется, чтобы данные были нормализованы и промасштабированы, включая предварительные преобразования. Результаты представляются в виде формул или массива весов. Существует еще ряд аргументов против использования нейронных сетей, например, их непрозрачность (факторы, приводящие к результирующему предсказанию, не являются очевидными) и потеря точности выходных данных.
Символьные классификаторы из области алгоритмов машинного обучения и статистические алгоритмы CHAID и CART предлагают более подходящее средство для DM, когда требуется объяснение смысла образцов. Деревья решений представляют правила, определяющие класс или значение. Такие деревья очень популярны благодаря разумной точности и понятности. Они строятся быстрее, чем нейронные сети. Но существуют и недостатки, например, стандартные алгоритмы для деревьев решений не могут обнаруживать правила, основанные на сочетаниях переменных.
В ходе международных четырехлетних экспериментальных исследований (StatLog) по сравнительному тестированию статистических алгоритмов и алгоритмов машинного обучения на масштабных приложениях для классификации, предсказания и управления был выполнен сравнительный анализ ряда классификационных систем, включая статистику, нейронные сети и символьные классификаторы, на 12 больших реальных множествах данных из областей распознавания образов, медицины, инженерии и финансов. Было обнаружено, что не существует наилучшего метода для классификации или предсказания, и исследователи пришли к заключению: точность любого метода извлечения данных, будь то нейронные сети, регрессионная статистика или символьные классификаторы, сильно зависит от структуры анализируемого множества данных. Обнаружено, что символьные классификаторы превосходят по точности нейронные сети на непараметризованных множествах данных и базах данных, содержащих большое количество нечисловых полей данных типа:
Женат - да / нет
Уровень потребления - низкий / средний / высокий
Номер по каталогу - 8M79Y.
Помимо основных, существуют еще алгоритмы и методы, являющиеся вспомогательными для извлечения данных. Чтобы лучше представить диапазон таких алгоритмов, приведем результаты последних достижений исследований по материалам трех конференций, посвященных извлечению данных (информация сгруппирована по областям и методам, связанным с извлечением данных):
Согласованное обучение. Вместо того, чтобы использовать DM для построения единственной предсказывающей модели, часто лучше построить набор или ансамбль моделей и комбинировать их, скажем, по эффективности стратегии голосования. Эта простая идея применяется в настоящее время в широком спектре контекстов и приложений. Известно, что при некоторых условиях этот метод позволяет сократить разброс в предсказаниях и, следовательно, уменьшить общую ошибку модели.
Линейная алгебра. Масштабирование (scaling) алгоритмов извлечения данных часто критически зависит от масштабирования лежащих в основе вычислений линейной алгебры. Последние работы в области параллельных алгоритмов для решения линейных систем и алгоритмов для решения разреженных линейных систем большого порядка важны для ряда приложений DM: от извлечения текстов до определения незаконного доступа в сеть.
Широкомасштабная оптимизация. Некоторые алгоритмы извлечения данных могут быть представлены как широкомасштабные, часто невыпуклые, задачи оптимизации. Разработаны параллельные и распределенные методы для задач непрерывной и дискретной оптимизации, включая методы эвристического поиска.
Эффективные вычисления и взаимодействия. Извлечение данных требует статистически интенсивных операций над большими множествами данных. Эти типы вычислений не могут быть практически осуществлены без появления мощных SMP-рабочих станций и высокопроизводительных кластеров рабочих станций. Кроме того, распределенное извлечение данных требует перемещения огромных объемов информации между географически удаленными точками, что возможно благодаря развитию сетей.
Базы данных, информационные хранилища и цифровые библиотеки. Наиболее длительной по времени частью процесса извлечения данных является их подготовка. Время выполнения этого шага может быть частично линейным по отношению к объему данных, если они находятся в БД, хранилище или цифровой библиотеке, тогда как извлечение данных из различных БД представляет собой сложную задачу. Некоторые алгоритмы, например, ассоциативные, жестко связаны с БД. В то же время существуют примитивные операции, которые при встраивании в хранилище делают реальным выполнение ряда приложений DM.
Визуализация массивных множеств данных. Визуализация - это метод для исследования тенденций (трендов) в БД, дополняемый обычно навигацией массивов данных, и визуально ориентированный на данные, чтобы обнаружить скрытые зависимости. Методы визуализации используют абстрактное представление в интерактивных, 3-D, виртуальных средах, чтобы отобразить большие объемы данных. Системы визуализации приспособлены для поддержки приложений реального времени, так как значения параметров могут быть отображены как движущееся или имитационное измерение данных. Последние достижения в многомерной визуализации позволяют выполнять ее параллельно, и, следовательно, делают практически выполнимыми задачи визуализации.
В заключение отметим, что сегодня для пользователя процесс выполнения DM включает 5 шагов:
1. Выбрать и подготовить данные для анализа.
2. Квалифицировать данные с помощью кластерного анализа или анализа характеристик. Кластеризация и сегментация данных предназначена для снижения их сложности, чтобы облегчить выполнение анализа.
3. Выбрать один или несколько инструментов DM.
4. Применить выбранные инструменты для обнаружения знаний.
5. Использовать обнаруженные знания для достижения цели исследования.
Сравнительный анализ технологии извлечения данных и других технологий и методов
Сегодня многие исследователи склонны считать, что DM связано, главным образом, с процессами индукции и в отличие от предшествующих технологий впервые позволяет получать обоснованную предсказывающую информацию по большим БД. Те, кто разделяют это мнение, представляют процесс эволюции извлечения данных примерно так, как это показано в Таблице 2 на примере решения задач маркетинга.
В то же время в отмечается, что извлечение данных может пониматься и более упрощенно и предлагаются отличительные характеристики подлинного средства DM:
1) процесс извлечения должен быть автоматизированным;
2) должен быть хороший статистический базис для отделения интересующей пользователя информации от нерелевантной.
В настоящее время наблюдается тенденция к слиянию технологий извлечения данных, OLAP и СППР . DM тесно взаимодействует и повышает эффективность применения ряда технологий:
1. Реализация запросов и генерация отчетов. DM позволяет сосредоточиться на использовании этих систем и методов, так что релевантная информация получается быстрее и экономится время аналитика.
2. Многомерные таблицы и базы данных. DM обеспечивает автоматический анализ, помогающий повысить эффективность использования данных, поддерживаемых многомерными инструментами.
3. Визуализация данных позволяет аналитику получить глубокое понимание результатов анализа данных. В то же время методы визуализации могут не справиться с огромными объемами информации базы данных, а DM дает начальные данные для продуктивного использования визуализации.
Остановимся теперь более подробно на сравнении методов DM и статистики, а также технологий извлечения данных и OLAP.
Методы статистики и извлечение данных:
Традиционно цель определения и использования информации, скрытой в данных, достигалась с помощью генераторов запросов и систем, интерпретирующих данные (пакеты статистической обработки SPSS, SAS и др.). Согласно , формальный статистический вывод - это предположение, выводимое в том смысле, что гипотеза сформулирована и доказывается на основе данных. Извлечение данных, напротив, управляется открытием в том смысле, что образцы и гипотезы автоматически извлекаются из данных. Другими словами, DM управляется данными, а статистика - человеком. Исследовательский анализ данных - область статистики, наиболее близкая к извлечению данных, работает с меньшими множествами данных, чем DM.
DM также отличается от статистики тем, что иногда цель состоит в извлечении качественных моделей, которые могут быть легко переведены в логические правила или визуальные представления; в этом смысле DM ориентируется на человека и иногда дополняется использованием человеко-машинных интерфейсов. DM - является интерактивным, полуавтоматическим процессом, начинающимся с рядов данных. Процесс DM предназначен для обнаружения скрытых данных, его результат - правила или предсказывающие модели. Как справедливо отмечается в , DM расширяет статистические подходы, допуская автоматизированную проверку большого количества гипотез и сегментацию БД. DM приобретает огромные преимущества по сравнению со статистикой при росте объема БД. В то же время следует подчеркнуть, что технология DM возникла из нескольких направлений: статистики, машинного обучения, баз данных и эффективных вычислений.
Поиск и доставка информации с узлов, имеющих периодическую связь с сетью.
Благодаря применению мобильных агентов может быть решена проблема поиска информации, находящейся на серверах, которые не имеют постоянного соединения с сетью или связаны с ней низкоскоростными каналами. Во время временного подключения к сети на такой сервер перемещается мобильный агент, который в автономном режиме осуществляет поиск и отбор необходимой информации и при появлении связи с внешним миром передает результаты своей работы клиенту.
Мониторинг данных
Не секрет, что значительное число серверов публикует очень немного новых материалов (в среднем, не более 10 статей в сутки). Ситуация осложняется тем, что такие сервера достаточно интенсивно изменяют свои оглавления, добавляя в них ссылки на документы из других серверов, рекламные баннеры и т.д. Это приводит к тому, что стандартные поисковые машины, отслеживая только изменения атрибутов файлов а не их содержание, считают такие файлы полноценными документами и доставляют их потребителям. Благодаря применению мобильных агентов, на удаленном сервере можно отслеживать появление новых документов, путем оценки их содержания принимать решение об их новизне, а потом о целесообразности доставки.
Оптимизация процедуры переноса информации
После того как мобильный агент принял решение передать определенный документ по назначению, возникает вопрос его доставки. Для снижения сетевого трафика в ходе этой процедуры может быть предложено два пути: использование прогрессивных методов передачи данных и передача только той части документа, которая отвечает поисковому запросу. В настоящее время, особенно на бесплатных новостных серверах, сложилась тенденция, при которой объем полезного сообщения не превышает 5-10% от объема страницы. Большую часть страницы занимают заголовки других сообщений, различные стили, ссылки на рекламные баннеры и т.п. Все это не только является мусором, но и будет серьезным препятствием для работы с таким документом в будущем.
Появляется необходимость разработки методов выделения из всего документа участка текста, в котором находится искомая информация для последующей его доставки. Выделение может осуществляться путем простого синтаксического разбора html-страницы, поиска "версии для печати" или с привлечением других технологий, в том числе искусственного интеллекта. Выполнение этой задачи может оказаться по силам мобильному агенту.
Мониторинг активности пользователей
Заслуживает внимания технология, при использовании которой мобильный агент собирает информацию о работе пользователей с документами web-серверов. Нечто подобное используется в системах электронной коммерции, когда фиксируется, какие именно документы пользователь просмотрел, и какое время затратил на просмотр каждого из них. На основании этих сведений можно получить оценку "значимости" документа и, имея сведения о круге интересов пользователя, даже сделать предположение о тематической направленности документа.
Система безопасности
Как и другие типы распределенных информационных систем, системы обработки текстовой информации нуждаются в средствах защиты, которые также могут быть построены на базе технологии мобильных агентов. В свое время были опубликованы достаточно многообещающие характеристики агента компании Sandia National Labs, назначение которого было направлено на самостоятельное распознавание и уничтожение вирусов до их попадания на защищаемые компьютеры и предугадывание враждебных действий. Был заявлен даже обмен информацией между несколькими копиями агента.