

4.4. Морфологический анализ
Стадия морфологического анализа (МА) является наиболее проработанным лингвистическим этапом процесса обработки естественного текста. За последние два десятилетия создано, по крайней мере, несколько десятков алгоритмов для разных языков, в том числе 10-12 для русского. Прежде, чем приступить к изложению основных методов и алгоритмов МА, необходимо ознакомится с терминологией, используемой в морфологии.
Основные термины морфологии
МА тесно связан с морфологическим уровнем языка, единицей которого является морфема. Морфемы по обязательности наличия в слове делятся на: корневые (корни) — обязательные; аффиксальные (аффиксы) - необязательные.
Корень — основная значимая часть слова. Является обязательной частью любого слова — не существует слов без корня (кроме редких вторичных образований с утраченным корнем типа русского вы-ну-ть (префикс-суффикс-окончание).
Аффикс — вспомогательная часть слова, присоединяемая к корню и служащая для словообразования и выражения грамматических значений. По положению относительно корня:
-
префиксы — перед корнем (традиционное название в русском языке — приставки);
-
постфиксы — после корня.
По словоизменяющей функции:
-
словонеизменяющие аффиксы — передают грамматическое и лексическое значение;
-
флексии — словоизменяющие аффиксы, которые передают реляционное, т.е. указывающее на связь с другими членами предложения, значение и являются показателем комплекса грамматических категорий, выражающихся в словоизменении (в русском языке обычно называются окончаниями, так как являются исключительно постфиксами).
Различают внутреннюю и внешнюю флексию. Внутренняя флексия – это такой способ словоизменения, при котором формы слова образуются изменением звуков внутри основы (родилась — родился, пеку — пёк). Внешняя флексия (фузия) – словоизменение, пользующееся синтетическими аффиксами (пол-е, пол-я, пол-ей). Языки, в которых словоизменительное и словообразовательное значение выражается преимущественно флексией, называются флективными.
В отличие от флексии основа – это неизменяемая часть слова, которая выражает его лексическое значение, то есть соотнесённость звуковой оболочки слова с соответствующими предметами или явлениями объективной действительности. Применительно к русскому языку основа – это часть слова без окончания. В английском языке основа слова, как правило, полностью совпадает с самим словом.
Следовательно, слово можно представить следующим образом
префикс+корень+постфикс=СЛОВО=основа+флексия
Парадигма (от греч. παράδειγμα, «пример, модель, образец») — в лингвистике список словоформ, принадлежащих одной лексеме и имеющих разные грамматические значения. Обычно представлена в виде таблицы. Словоизменительная парадигма выступает образцом того, как строятся словоизменительные формы для целых классов лексем (склонений существительных, спряжений глаголов и т. п.)
Построение парадигм — одно из первых лингвистических достижений человечества; вавилонские глиняные таблички с перечнями парадигм обычно считаются первым памятником лингвистики как науки.
Обычно парадигмы упорядочены в некотором традиционном порядке граммем, например, парадигма русского склонения записывается в порядке падежей И — Р — Д — В — Т — П: рука, руки, руке, руку, рукой, о руке
Парадигма личного спряжения в европейских языках записывается обычно в порядке иду-идёшь-идёт (и соответственно лица называются первым, вторым и третьим), а, например, в арабском языке порядок обратный.
Лемма — это начальная (словарная) форма лексемы. Процесс привода словоформы к лемме — её словарной форме называется лемматизацией. В русском языке начальными формами являются:
-
для существительных — именительный падеж, единственное число;
-
для прилагательных — именительный падеж, единственное число, мужской род;
-
для глаголов, причастий, деепричастий — глагол в инфинитиве.
Примеры: кошками → кошка, бежал → бегать, боязненных → боязненный
Морфологическая информация, этапы морфологического разбора текста
Цель МА — определить принадлежность некоторой словоформы к парадигме определенной лексемы и грамматические признаки для этой словоформы – морфологическую информацию (МИ) для использования ее на последующих этапах обработки ЕЯ текста.
Так для существительных этими признаками будут: род, число, падеж и склонение, для прилагательных: род, число и падеж; для глаголов - время, лицо, число, спряжение, вид; для местоимений – число и лицо. Классификация морфологических признаков слов русского языка изображена на рисунке 5.1.
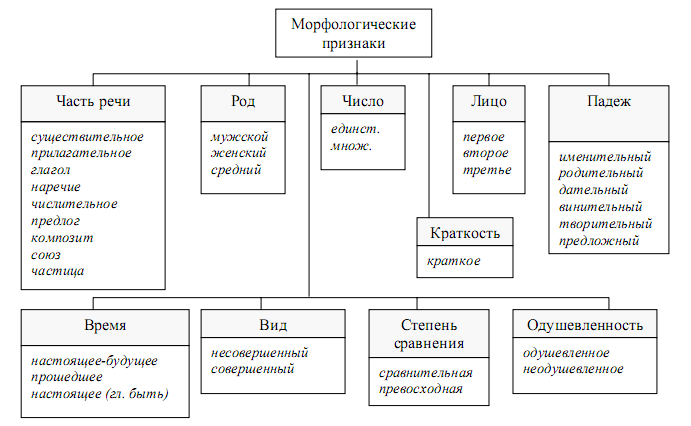
Рис.5.1. Морфологические признаки слов русского языка
Для русского языка, как и для большинства синтетических языков, задача лексико-грамматического разбора решается довольно просто и почти стопроцентной точностью, благодаря их развитой морфологии. В аналитических языках, например английском, где широко представлена лексическая многозначность, простой алгоритм, сопоставляющий каждому слову в тексте наиболее вероятный для данного слова морфологический класс, дает лишь около 90% точности.
Для синтетических языков морфологический разбор текста включает:
-
Выделение внутри предложений отдельных словоформ.
-
Определение всех вариантов комбинаций основ и аффиксов для каждой словоформы и, соответственно, вариантов грамматических форм.
-
Устранение грамматической неоднозначности на основе комбинаторного словаря, содержащего все контексты употребления слов.
Для увеличения точности разбора используются два типа алгоритмов: вероятностно-статистические и основанные на продукционных правилах.
Алгоритмы, основанные на продукционных правилах, используют правила, которые строятся автоматически на основе некоторого корпуса текстов или создаются лингвистами.
Вероятностно-статистические алгоритмы используют, в основном, два источника информации.
-
Словарь словоформ, в котором каждой словоформе соответствует множество лексико-грамматических классов, которые могут быть у данной словоформы. Для каждого лексико-грамматического класса указывается частота его встречаемости относительно других морфологических классов данной словоформы.
-
Информация о встречаемости всех возможных последовательностей морфологических классов попарно, по тройкам, по четверкам и т.д. с относительной частотой такой пары (тройки, четверки и т.д.). Эта информация обрабатывается неким статистическим алгоритмом (например, на основе скрытых цепей Маркова) для нахождения наиболее вероятного лексико-грамматического класса для каждого слова в предложении.
Оба подхода дают примерно одинаковый результат на уровне 96-98 % точности.
Существует несколько классификаций основных видов алгоритмов морфологического анализа. По использованию словарей системы МА можно разделить на словарные (со словарем словоформ или со словарем основ) и бессловарные, а по организации алгоритмов — на методы с декларативной, процедурной и комбинированной ориентацией.
Обзор основных алгоритмов морфологического анализа
МА со словарем основ является наиболее распространенным способом анализа. Для его проведения требуется словарь основ слов и ряд вспомогательных таблиц.
Если слово имеет несколько вариантов основ, то словарь, как правило, содержит все варианты. Обычно в этом случае один из вариантов основы помечается как основной, а другие варианты содержат ссылку на него. Это необходимо для дальнейшего семантического анализа, чтобы устранить различные смысловые трактовки для одного и того же слова. Дополнительные таблицы содержат, как правило, список возможных вариантов изменяемых частей слов (в русском языке – окончаний) с соответствующим им значением грамматических признаков.
В общем случае производится поиск всего слова в словаре основ, если слово не найдено, от него отделяется последняя буква и производится повторный поиск. Так продолжается до тех пор, пока основа не будет найдена либо пока не останется букв. В случае удачного поиска из словаря извлекаются варианты частей речи, соответствующих этой основе. Затем производится поиск в таблице изменяемых частей слова. При этом пропускаются варианты соответствующие частям речи, к которым данная основа не может относиться. Таким образом, определяются грамматические признаки разбираемой словоформы.
Безсловарный МА проводится без использования словарей основ или начальных форм, а лишь с использованием таблицы аффиксов, списка слов-исключений и списка служебных неизменяемых слов (например, союзов, междометий, предлогов). Этот способ используется достаточно редко.
Существуют три основных метода реализации МА: декларативный, процедурный и комбинированный. При декларативном методе в словаре хранятся все возможные словоформы каждого слова с приписанной им МИ. В этом случае задача МА состоит просто в поиске словоформы в словаре и переписывании из словаря МИ, поэтому можно считать, что в этом методе отсутствует как таковой морфологический анализ, а хранится только его результат. Так как количество различных словоформ у каждого слова довольно велико, декларативный метод требует больших затрат памяти вычислительной системы, что порождает ряд технических проблем, заключающихся в больших затратах труда на создание и поддержание словаря, в высокой избыточности информации. Достоинствами метода является высокая скорость анализа, а также универсальность по отношению к множеству всех возможных словоформ русского языка.
Процедурный МА выполняет следующие функции: выделяет в текущей словоформе основу, идентифицирует ее и приписывает данной словоформе соответствующий комплекс МИ. Процедурный метод предполагает предварительную систематизацию морфологических знаний о ЕЯ и разработку алгоритмов присвоения МИ отдельной словоформе. Недостатком такого подхода является высокая трудоемкость составления словарей совместимости. При этом наличие в русском языке большого числа слов-исключений не позволяет сколько- нибудь автоматизировать этот процесс. Для проведения анализа словоформы необходимо наличие словарей «приставка-корень», «корень – суффикс - флективный класс», «флективный класс – окончание - МИ».
Существует два подхода к решению задачи процедурными методами.
Первый подход предполагает наличие словаря основ и словаря аффиксов. Для слова выполняется процедура поиска в словаре основ. При этом ищутся все основы, с которых может начинаться анализируемое слово. Если очередная основа удовлетворяет этому условию, то из словаря аффиксов извлекается строка, содержащая все возможные аффиксы для данной основы. Каждый аффикс из этой строки поочередно присоединяется к основе, и результат сравнивается с анализируемым словом. В случае их точного совпадения формируется очередная запись в список результатов поиска: по порядковому номеру аффикса в строке аффиксов определяются переменные морфологические параметры слова (например, для существительного - число и падеж), а по словарной информации данной основы - его постоянные параметры (для существительного — род и одушевленность).
Если в результате такого поиска не найдено ни одного успешного варианта, то проводится поиск среди исключений. Исключения присутствуют в словаре основ наряду с обычными основами. И те, и другие имеют в словаре информацию о постоянных морфологических признаках и о номере строки допустимых аффиксов.
Разница между исключениями и обычными основами состоит в том, что, во-первых, строка с неизменной частью слова у исключений пустая, и, во-вторых, номер строки аффиксов для исключений относится не к файлу аффиксов, а к отдельному файлу исключений. Структура этого файла точно такая же, но в него внесены целые словоформы, а не их окончания. Таким образом, при поиске среди исключений приходится просматривать все словоформы всех присутствующих в словаре исключений. Это занимает много времени, поэтому поиск среди исключений проводится только в том случае, когда не найдено ни одного варианта среди обычных основ. Сам анализ проводится точно так же. Если некоторая словоформа некоторого исключения точно совпадает с анализируемым словом, то по номеру словоформы определяются переменные морфологические параметры слова, а по словарной информации самого исключения — постоянные параметры слова.
Если после поиска среди исключений все равно не найдено ни одного варианта, то проверяется наличие у анализируемого слова возвратного суффикса ся, сь, или приставок не, ни. Если они есть, то они отсекаются от анализируемого слова, и процедура поиска повторяется сначала. При этом морфологические параметры находимых основ модифицируются специальной процедурой. В случае, когда все этапы поиска дали отрицательный результат (не найдено ни одного варианта), пользователю выдается запрос на ввод новой основы в словарь. В случае его отказа это сделать выполнение морфологического анализа прекращается. Если же новое слово введено в словарь, то вся процедура поиска повторяется сначала.
Второй подход предполагает наличие словаря начальных форм и МИ, необходимой для словоизменения (как-то, часть речи, род и т.д.), а также массивов окончаний и программной реализации правил чередования в основе. Подход состоит в том, что слово последовательно причисляется к каждой из частей речи. Последовательно выбираются окончания для этой части речи. В случае, если окончание одной из косвенных форм совпадает с концовкой слова, совпадающая часть отбрасывается, производятся чередования в основе, если слово соответствует шаблону чередования, и к полученной основе добавляется окончание леммы. При построении леммы запоминается промежуточная информация.
Таким образом, все леммы, которые можно построить, вместе с промежуточной информацией собираются в список. Каждое слово этого списка ищется в словаре лемм. Результатом лемматизации является список слов, найденных в словаре, для которых промежуточная информация соответствует грамматической информации из словаря.
Работающая система, в которой реализован процедурный МА, занимает значительно меньший объем памяти, но при этом увеличивается время поиска МИ за счет разбиения словоформы на составляющие и применения процедур совместимости. Исходя из этого, процедурный метод удобнее применять в системах с относительно небольшим количеством пользователей, в то время как декларативный – в системах с частым обращением к лингвистическому анализатору. Другим существенным недостатком процедурных методов является отсутствие универсальности, т.к. существует большое количество слов, которые нельзя представить в виде суммы неизменной основы и аффикса, например, существительное год, которое имеет во множественном числе родительного падежа форму лет; местоимение я и т. д.
В системах реальной степени сложности чаще используется комбинированный вариант МА. При этом используется как словарь словоформ, так и словарь основ. На первом этапе проводится поиск по словарю словоформ, как при декларативном методе, и в случае успешного поиска анализ на этом завершается. В противном случае задействуется словарь основ и процедурный метод анализа.
В последние годы активно развивается направление, использующее универсальные математические модели в форме открытой системы уравнений, позволяющих путем вычисления осуществлять нормализацию словоформ, получение грамматической информации и синтез словоформ. Такой подход вызван стремлением преодолеть ограниченность существующих алгоритмов МА.
Анализ показал, что наиболее распространенным методом МА является декларативный, что объясняется простотой его алгоритма и удобством кодирования. После МА лексеме приписывается кортеж с совокупностью морфологической информации, которая поступает на вход синтаксического анализатора, рассмотренного в следующих лекциях.
В первом и во втором случае сталкиваемся с резервированием лишнего места и необходимостью использования сложных процедур интерпретации.
Третий способ хранения МИ – в виде битовых полей. Он сочетает в себе удобства обработки и экономное хранение МИ, поэтому более предпочтителен. Рассмотрим способы задания морфологической информации с помощью битовых полей, примененные в модуле морфологического анализа LINGUIST, в модуле лемматизации, разработанном в отделе РРО ИПИИ.
Формат представления морфологической информации модулем морфологического анализа LINGUIST
МИ слова в модуле LINGUIST полностью описывается структурой TGramInfo. Эта структура содержит три поля, первое из которых (wInfo) относится к самому слову – описывает постоянную МИ, а два других (gInfo & Flags) описывают его форму – переменная МИ:
typedef struct _GramInfo
{
WORD16 wInfo;
WORD16 gInfo;
WORD16 Flags;
} TGramInfo;
Первое поле (wInfo), а точнее, младшие его 6 бит, содержат информацию о типе слова (части речи) по классификации LINGUIST, приведенной в таблице 6.1. Второе поле структуры TGramInfo - gInfo - содержит информацию о форме слова (такую, как падеж или род, то есть переменная МИ), приведенную в таблице 6.2.
Таблица 6.1 – Описание постоянной МИ в модуле LINGUIST
|
wInfo & 0x3F |
Часть речи |
|
|
0x01 |
Глагол несовершенного вида |
|
|
0x02 |
Непереходный глагол несовершенного вида |
|
|
0x03 |
Глагол совершенного вида |
|
|
0x04 |
Непереходный глагол совершенного вида |
|
|
0x05 |
Двувидовой глагол |
|
|
0x06 |
Непереходный двувидовой глагол |
|
|
0x07 |
Неодушевленное существительное мужского рода |
|
|
0x08 |
Одушевленное существительное мужского рода |
|
|
0x09 |
Одушевленное - неодушевленное существительное мужского рода |
|
|
0x0A |
Неодушевленное существительное мужского рода |
|
|
0x0B..0x0C |
Одушевленное существительное мужского рода |
|
|
0x0D |
Неодушевленное существительное женского рода |
|
|
0x0E |
Одушевленное существительное женского рода |
|
|
0x0F |
Одушевленное - неодушевленное существительное женского рода |
|
|
0x10 |
Неодушевленное существительное среднего рода |
|
|
0x11 |
Одушевленное существительное среднего рода |
|
|
0x12 |
Одушевленное - неодушевленное существительное среднего рода |
|
|
0x13 |
Неодушевленное существительное общего рода |
|
|
0x14 |
Одушевленное существительное общего рода |
|
|
0x15 |
Неодушевленное существительное мужского/среднего рода |
|
|
0x16 |
Одушевленное существительное мужского/среднего рода |
|
|
0x17 |
Неодушевленное существительное женского/среднего рода |
|
|
0x18 |
Неодушевленное существительное множественного числа |
|
|
0x19..0x1A |
Прилагательные |
|
|
0x1B |
Притяжательные местоимения |
|
|
0x1C |
Местоименные прилагательные |
|
|
0x1D..0x20 |
Местоимения |
|
|
0x21..0x22 |
Числительное |
|
|
0x23 |
Собирательное числительное |
|
|
0x24 |
Порядковое числительное |
|
|
0x25..0x27 |
Имена собственные |
|
|
0x28..0x29 |
Отчества |
|
|
0x2A |
Фамилии |
|
|
0x2B..0x2F |
Географические названия |
|
|
0x30 |
Вводное слово |
|
|
0x31 |
Междометие |
|
|
0x32 |
Предикатив |
|
|
0x33 |
Предлог |
|
|
0x34 |
Союз |
|
|
0x35 |
Частица |
|
|
0x36 |
Наречие |
|
|
0x37 |
Сокращенное существительное |
|
|
0x38 |
Сокращенное прилагательное |
|
|
0x39 |
Сокращенное вводное слово |
|
|
0x3A |
Обособленная сравнительная степень |
|
|
0x3B..0x3C |
Аббревиатура |
|
Таблица 6.2 – Описание переменной МИ в модуле LINGUIST
|
Бит |
Значение |
Значение |
|
0-2 |
0x0001 |
инфинитив |
|
0x0002 |
Повелительное наклонение |
|
|
0x0003 |
будущее время |
|
|
0x0004 |
настоящее время |
|
|
0x0005 |
прошедшее время. |
|
|
3-4 |
0x0008 |
первое лицо |
|
0x0010 |
второе лицо |
|
|
0x0018 |
третье лицо. |
|
|
5-6 |
0x0000 |
личная форма глагола |
|
0x0020 |
действительное причастие |
|
|
0x0040 |
страдательное причастие |
|
|
0x0060 |
деепричастие. |
|
|
7 |
0x0080 |
Сравнительная степень прилагательных. |
|
8 |
0x0100 |
Краткая форма прилагательных и страдательных причастий. |
|
9-10 |
0x0200 |
мужской род, единственное число |
|
0x0400 |
женский род, единственное число |
|
|
0x0600 |
средний род, единственное число |
|
|
11 |
0x0800 |
Множественное число склоняющихся слов. |
|
12-14 |
0x1000- 0x7000 |
Падеж. Может иметь значение от 0 до 7, что соответствует восьми падежам – именительному, родительному, дательному, винительному, творительному, предложному, второму родительному и второму предложному соответственно. |
|
15 |
0x8000 |
Возвратная форма. Бит выставлен у возвратных форм глаголов и некоторых прилагательных и произошедших от них существительных. |