

Лабораторная работа №11 статистический анализ и прогнозирование в ms excel
Цель работы:изучить инструмент анализаMS Excel Подбор параметра; приобрести навыки его применения для решения прикладных задач.
Методические указания
К средствам статистического анализа в среде электронных таблиц MSExcel относится, в первую очередь, Пакет анализа. Рассмотрим некоторые возможности этого Пакета.
1. Использование статистических функций.
В MSExcel имеется большое количество функций, специально предназначенных для статистического анализа данных. Большинство из них доступны постоянно, для применения некоторых следует выполнить соответствующие настройки (Параметры Excel – Надстройки – Пакет анализа). Статистические функции позволяют выполнить статистический анализ данных, например, провести аппроксимирующую прямую по множеству точек, вычислить угол наклона этой прямой, точку ее пересечения с осью Y и т.д. Полный список статистических функций приведен в категории Статистические Мастера функций.
2. Выполнение статистического анализа.
Для выполнения статистического анализа данных следует выбрать команду Анализ данных. Если эта команда недоступна, следует загрузить Пакет анализа. Затем в диалоговом окне Анализ данных следует выбрать нужную функцию, нажать кнопку ОК, установить параметры анализа. В диалоговом окне Анализ данных предлагаются следующие функции: Однофакторный дисперсионный анализ, Двухфакторный дисперсионный анализ с повторениями, Двухфакторный дисперсионный анализ без повторений, Корреляция, Ковариация, Описательная статистика, Экспоненциальное сглаживание, Двухвыборочный f-тест для дисперсии, Анализ Фурье, Гистограмма, Скользящее среднее, Генерация случайных чисел, Ранг и персентиль, Регрессия, Выборка, Парный двухвыборочный t-тест для средних, Двухвыборочный t-тест с одинаковыми дисперсиями, Двухвыборочный t-тест с различными дисперсиями, Двухвыборочный z-тест для средних. Рассмотрим некоторые из этих функций.
а) Использование равномерного распределения.
В качестве примера моделирования последовательности реальных данных рассмотрим задачу измерения среднесуточной температуры больного в течение двух недель. Пусть значения измерений среднесуточной температуры находятся в пределах от 37 до 39,8 градусов по Цельсию. Предположим, что значения в заданном интервале распределены равномерно. Для того, чтобы создать последовательность, моделирующую реальные данные, воспользуемся функцией из Пакета анализаГенерация случайных чисел. Для этого сначала следует задать на рабочем листе MSExcel диапазон, который будет содержать данную последовательность. Затем выполнить команду Сервис – Анализ данных. В появившемся окне диалога в списке Инструменты анализа выбрать элемент Генерация случайных чисел (рис.1.1).
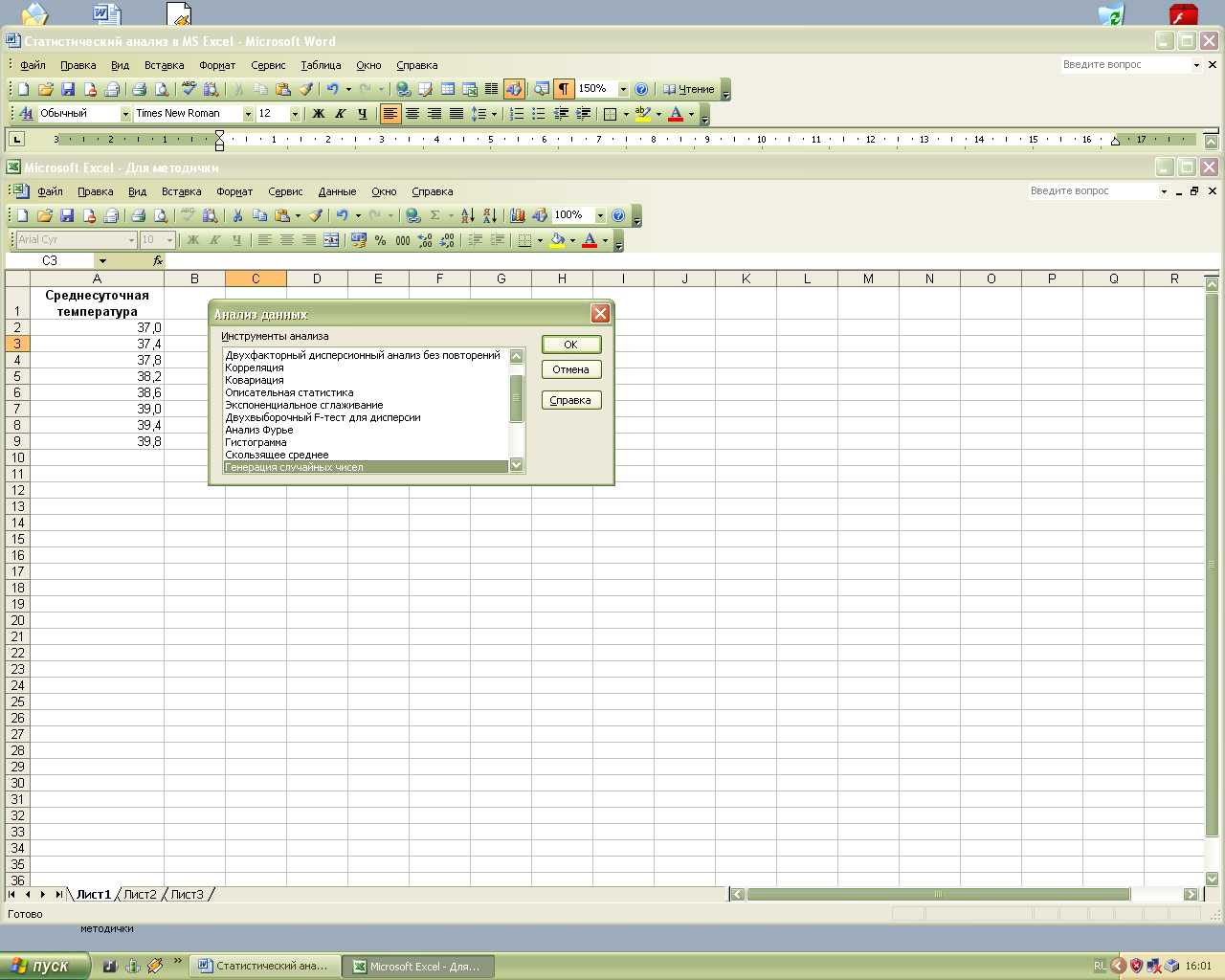
Рис.1.1. Окно диалога Анализ данных
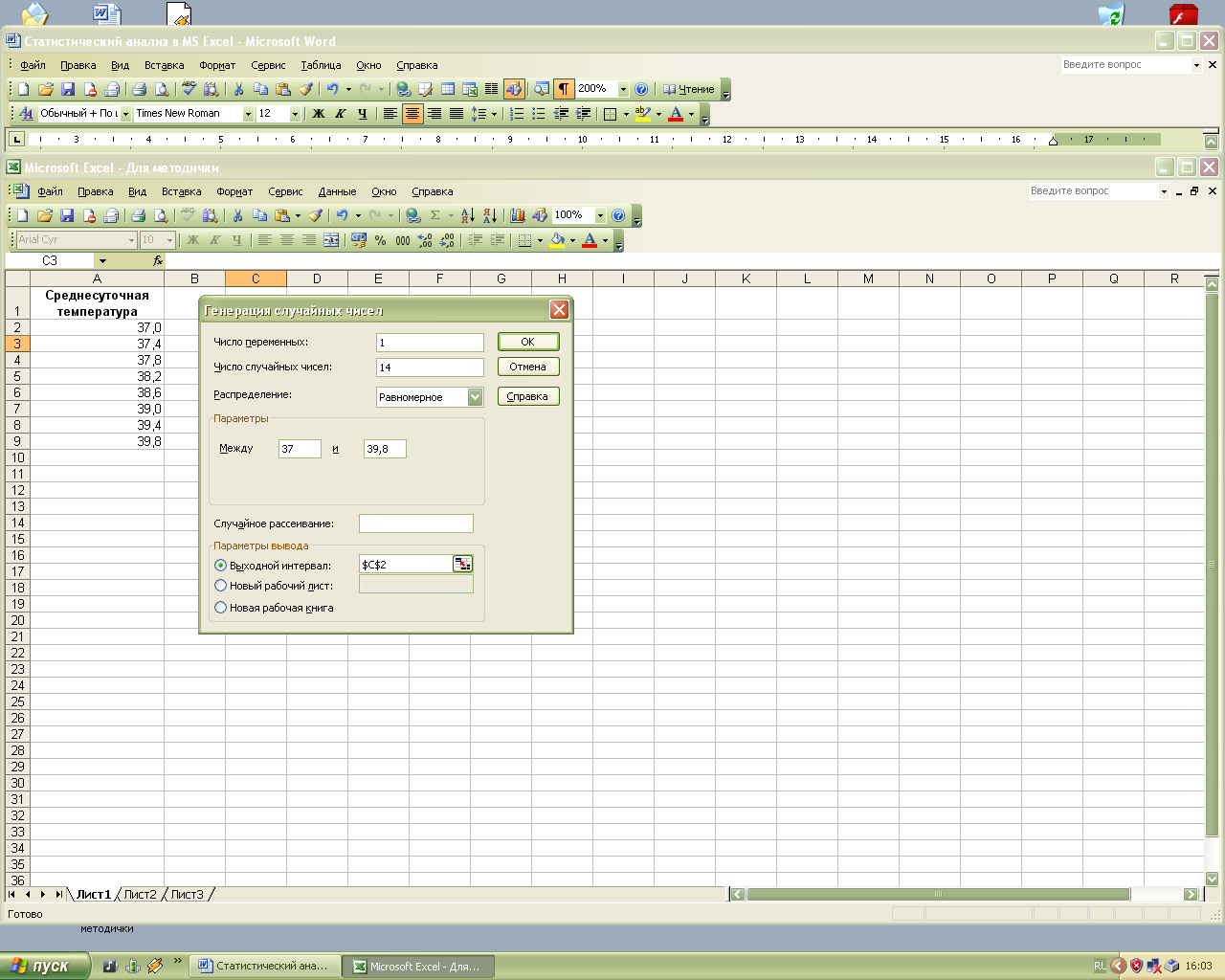
Рис.1.2. Окно диалога Генерация случайных чисел
В окне диалога Генерация случайных чисел в поле Число переменных введите единицу (рис.1.2). Это будет означать, что число столбцов, которые будут заполнены последовательностью смоделированных данных, будет равно единице. В поле Число случайных чисел ввести 14 (это соответствует числу дней, в течение которых измерялась среднесуточная температура). Затем в списке Распределение выбрать элемент Равномерное, в поляМежду и ввести значения 37 и 39,8 (эти значения определят интервал распределения среднесуточной температуры). В поле Случайное рассеивание можно ввести некоторую величину, в случае, если необходимо создать несколько одинаково распределенных последовательностей с отличающимися значениями. Если достаточно одной последовательности, оставить это поле пустым. В поле Выходной интервал ввести ссылку на первую ячейку диапазона, который должен быть заполнен последовательностью и нажать кнопку ОК для генерации последовательности. Результатом этих действий будет столбец из 14 случайных значений от 37 до 39,8, распределенных равномерно (рис.1.3).
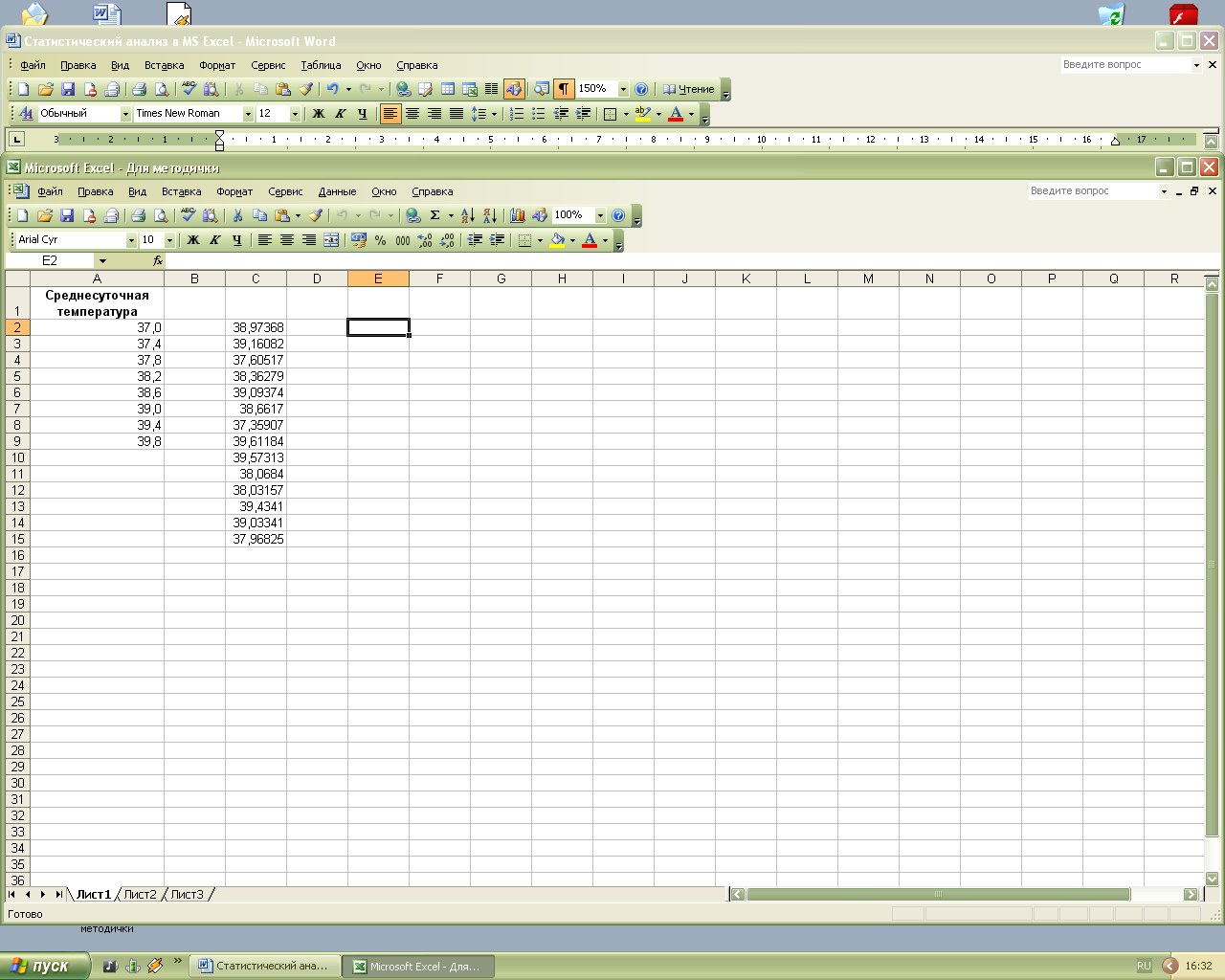
Рис.1.3. Сгенерированная последовательность случайных чисел, распределенных равномерно
б)Гистограмма.
Это средство используется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются частота попаданий для заданного диапазона ячеек. Измеряемые величины условно делятся на две группы:
- По своей природе измеряемая величина является случайной. При этом результат отдельного наблюдения такой величины заранее неизвестен.
- Измеряемая величина является по своей природе постоянной. На измерение величин такого типа оказывают влияние многочисленные неконтролируемые внешние факторы, приводящие к тому, что результаты отдельных измерений неодинаковы. Поэтому в процессе измерения постоянная величина проявляется как случайная.
Для построения гистограммы воспользуемся предыдущим примером. В списке Инструменты анализа выбрать пункт Гистограмма. В поле Входной интервал указать диапазон $С$2:$С$15. В поле Интервал карманов ввести диапазон $A$2:$A$9. Если не ввести Интервал карманов, MSExcel по умолчанию создаст равномерно распределенный диапазон. В качестве Выходного интервала ввести ссылку на левую верхнюю ячейку диапазона, в который будут помещены результаты. Установить переключатель Вывод графика (рис.1.4-1.5).
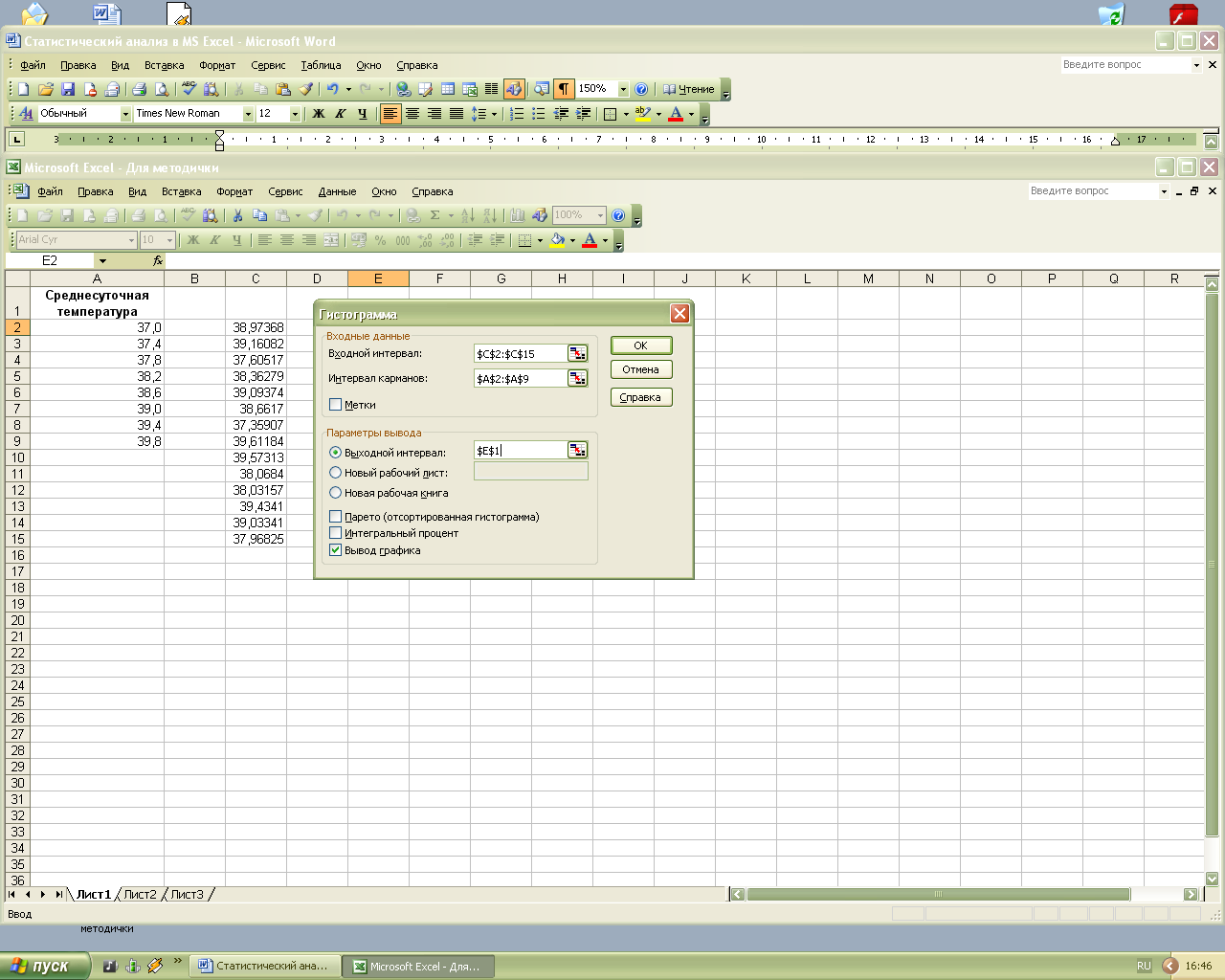
Рис.1.4. Окно диалога Гистограмма
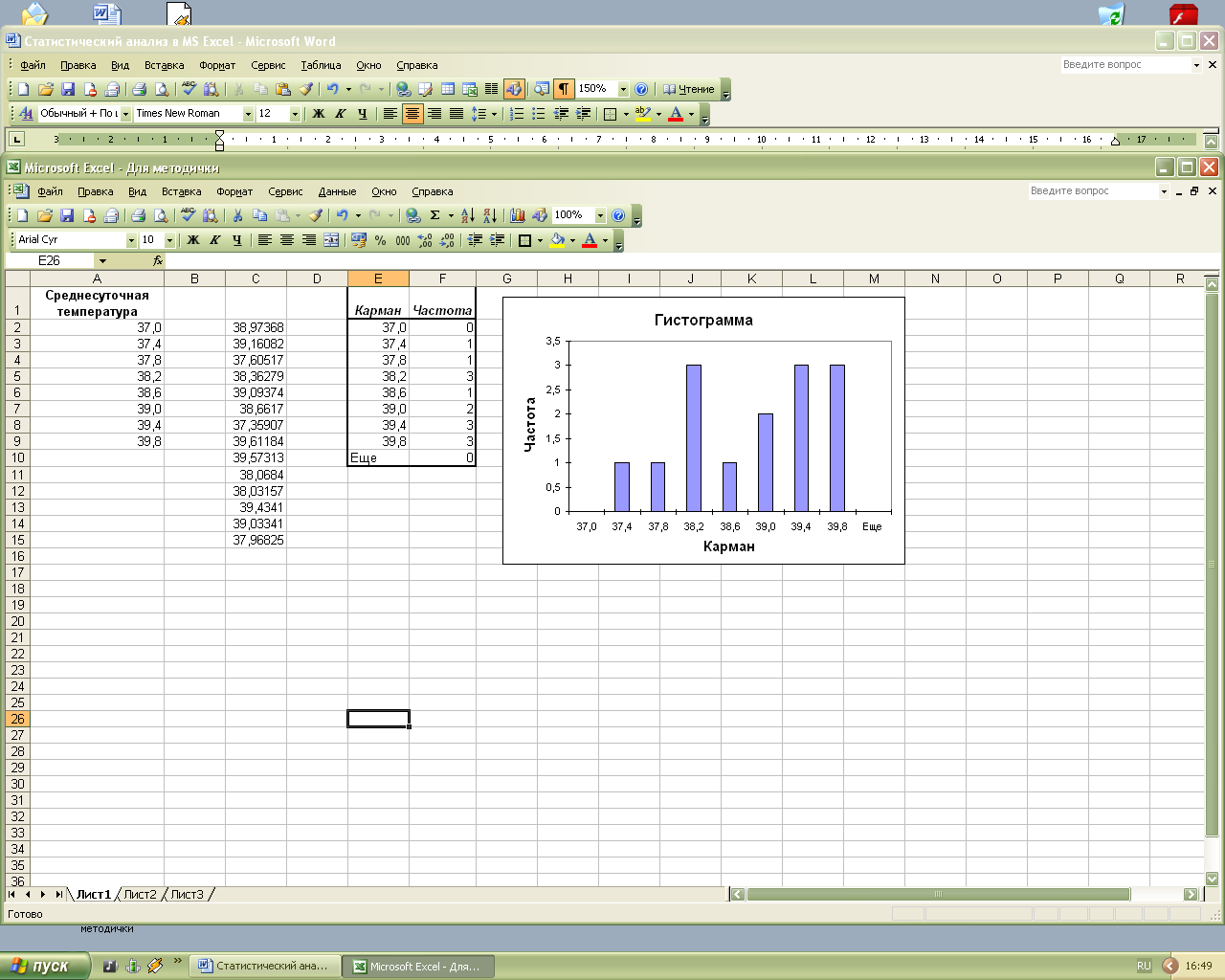
Рис.1.5. Гистограмма
При построении гистограмм можно использовать дополнительные возможности, установив соответствующие флажки в окне диалога Гистограмма:
- Парето – позволяет создавать копию результата, в которой интервалы разбиения отсортированы по возрастанию количества значений случайной величины, попавших в интервал.
- Интегральный процент – позволяет создавать дополнительный столбец в результатах, отражающий процент попаданий в каждый интервал разбиения.
При помощи построенных описанным способом гистограмм можно быстро построить необходимое распределение, если исходные значения не подвергаются изменениям. В противном случае следует воспользоваться статистическими функциями MSExcel.
в)Сглаживание данных. При анализе данных часто из-за некоторых внешних факторов и случайных колебаний исследуемые величины не имеют четко выраженной закономерности. Для того, чтобы лучше понять и увидеть на гистограмме закономерностей изменения величин, используют сглаживание колебаний. Пакет анализа предоставляет для этого два метода: Скользящее среднее и экспоненциальное сглаживание. При использовании этих методов формулы в ячейки результатов помещаются сразу, поэтому при изменении входных данных будут автоматически пересчитываться сглаживающие величины.
При использовании метода Скользящее среднее для каждого интервала вычисляется среднее арифметическое значение на основе значений из нескольких предыдущих интервалов (количество используемых для этого интервалов задается в параметрах сглаживания). При использовании метода Экспоненциальное сглаживание следующее значение вычисляется как среднее от значения точки данных на текущем интервале и экспоненциального сглаженного, полученного на предыдущей итерации. При этом все предшествующие текущему интервалы автоматически включаются в вычисления на каждой итерации; можно задать весовой коэффициент для текущего интервала, который будет являться фактором затухания. Чем выше этот коэффициент, тем выше степень затухания.
Рассмотрим применение этих методов на предыдущем примере. Для того, чтобы воспользоваться методом Скользящее среднее в окне диалога команды меню Сервис – Анализ данных следует выбрать средство Скользящее среднее (рис.1.6-1.7).
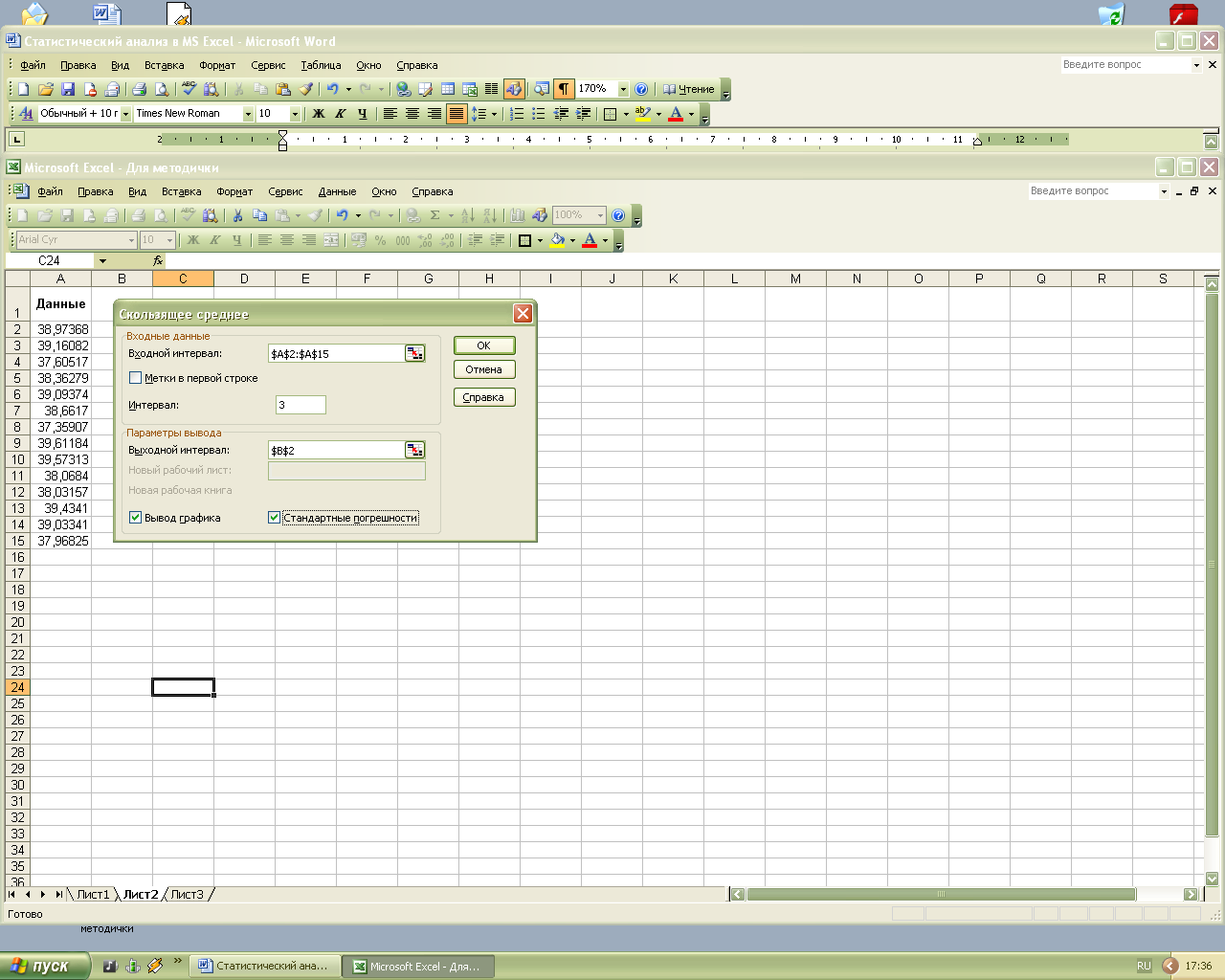
Рис.1.6. Окно диалога Скользящее среднее
Для того, чтобы правильно заполнить поля появившегося окна диалога, воспользуйтесь таблицей 1.1.
Таблица 1.1.
Данные для заполнения окна диалога Скользящее среднее
|
Поле |
Описание |
|
Входной интервал |
Диапазон исходных данных для сглаживания. |
|
Выходной интервал |
Верхняя левая ячейка диапазона результатов. Имеет столько же строк, сколько и входной диапазон. |
|
Входной интервал |
Диапазон исходных данных для сглаживания. |
|
Интервал |
Число используемых предшествующих периодов. Чем больше количество интервалов, тем выше степень сглаженности и ниже информативность. |
|
Стандартные погрешности |
В результат добавляется столбец, содержащий статистическую оценку ошибки. |
|
Вывод графика |
По результатам анализа автоматически создается диаграмма. |
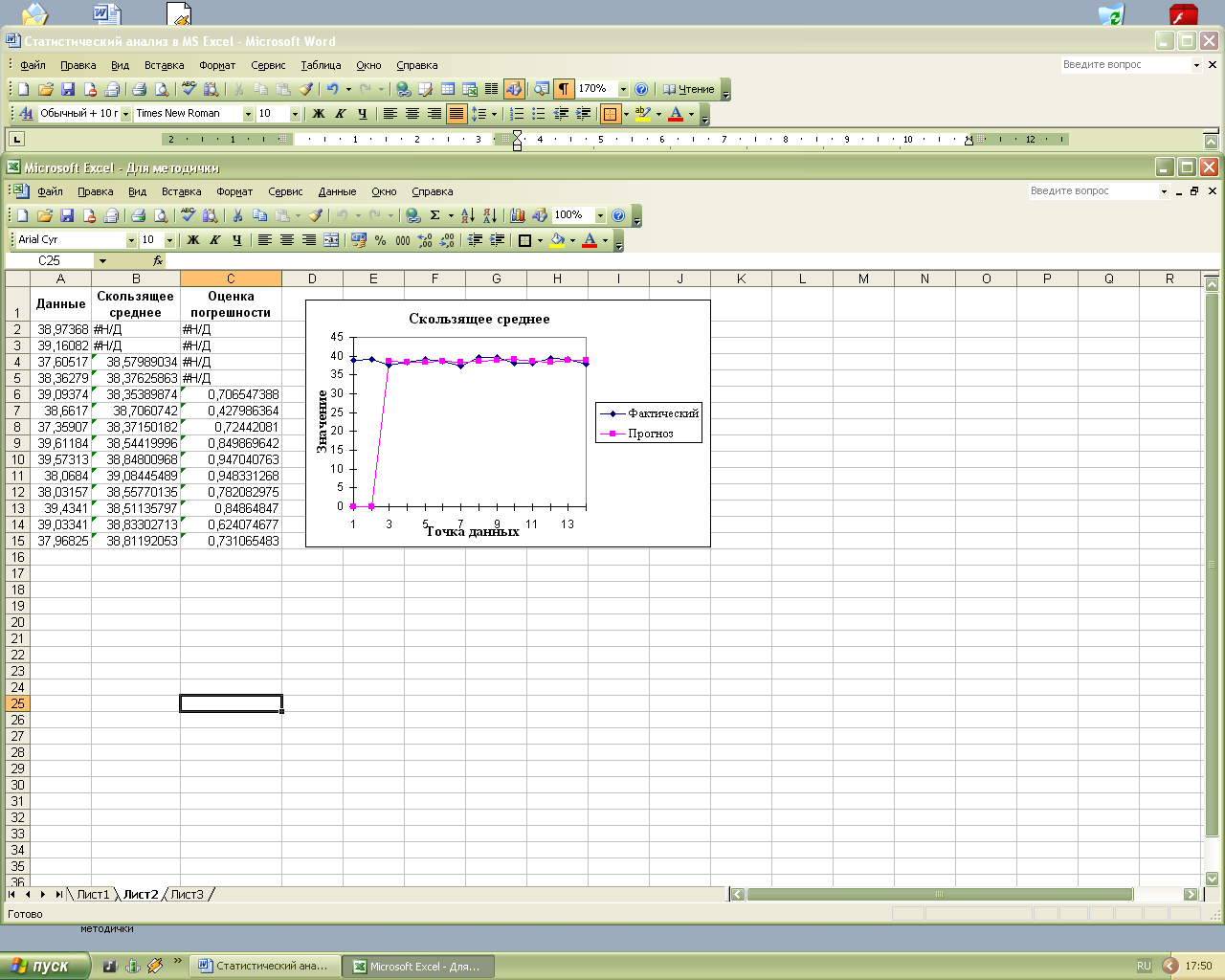
Рис.1.7. Результат работы метода Скользящее среднее
Чтобы построить Экспоненциальное сглаживание, в диалоговом окне команды меню Сервис – Анализ данных выбрать элемент Экспоненциальное сглаживание. Ниже представлены заполненные поля ввода окна диалога Экспоненциальное сглаживание (рис.1.8).
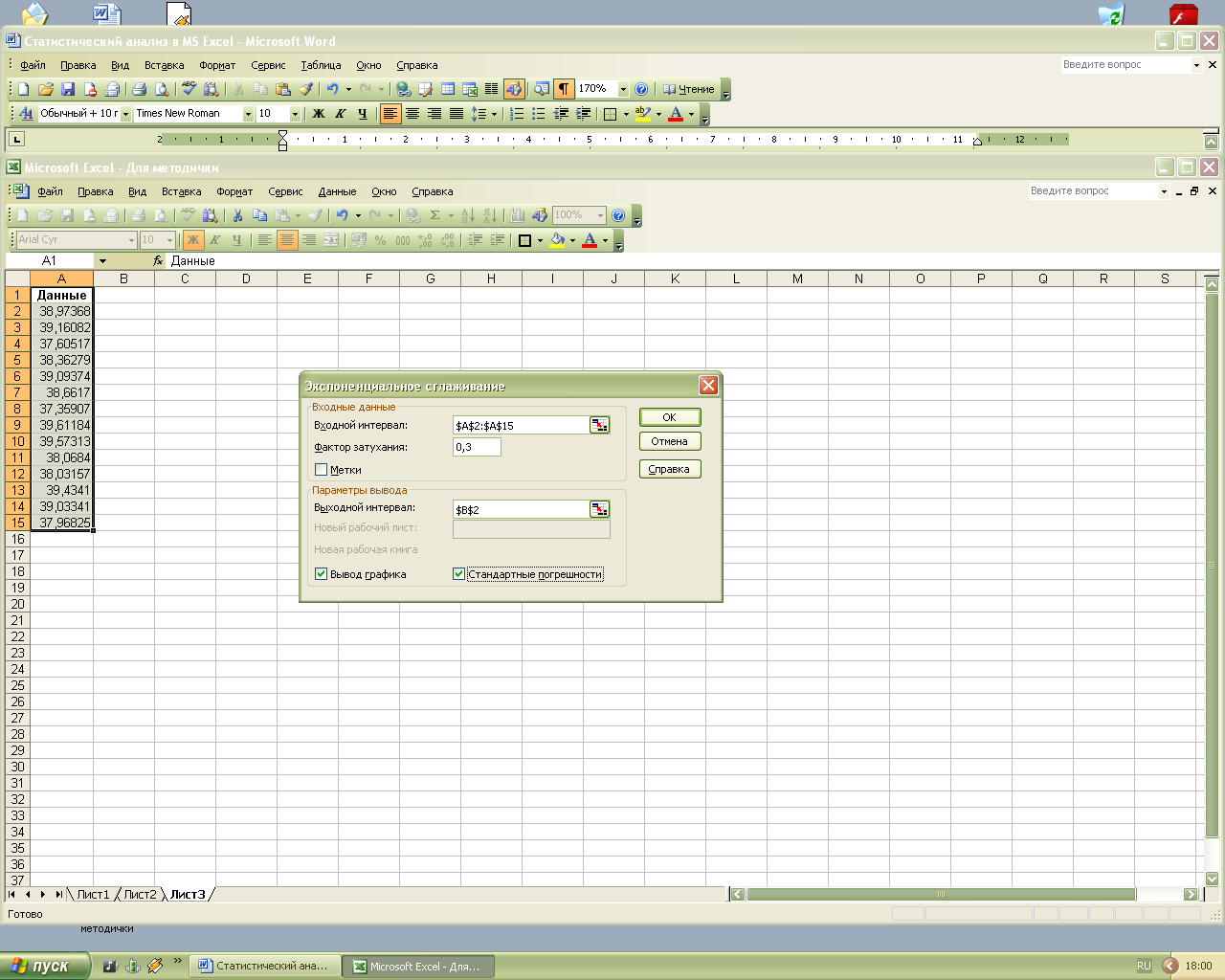
Рис.1.8. Окно диалога Экспоненциальное сглаживание
Результаты Экспоненциального сглаживания представлены ниже (рис.1.9).

Рис.1.9. Результат работы метода Экспоненциальное сглаживание
Если при применении методов Скользящее среднее и Экспоненциальное сглаживание некоторые ячейки содержат значения ошибки, это означает, что у этих ячеек не существует трех предшествующих интервалов.
Прогнозирование данных при помощи линии тренда.
Линии тренда являются статистическим инструментом, при помощи которого можно анализировать тренды и делать прогнозы, а также давать представление о степени достоверности отображаемых на диаграмме данных. Линию тренда можно добавить к любому ряду данных, использующему ненормированные плоские диаграммы. Линия тренда связывается с рядом данных, к которому была добавлена, и автоматически пересчитывается и обновляется при изменении значений любых точек ряда данных. При создании линии тренда на основе данных диаграммы применяется один их пяти типов аппроксимирующих линий: линейная, логарифмическая, полиноминальная, степенная и экспоненциальная. При построении линии тренда предоставляется возможность выбирать значения пересечения линии тренда с осью Y, добавлять к диаграмме уравнение аппроксимации и величину достоверности аппроксимации (R-квадрат). Чем ближе значение величины достоверности аппроксимации к 1, тем достовернее прогноз данных.
Для того, чтобы добавить линию тренда, следует выделить нужный ряд данных, в контекстном меню выбрать командуДобавить линию тренда.

Рис.1.10. Окно диалога Линия тренда
В появившемся окне диалога на вкладке Тип указать тип аппроксимирующей линии; на вкладке Параметры установить параметры линии тренда: автоматическое (для линии тренда используется название ряда данных), другое (позволяет ввести новое название линии тренда в текстовое поле), прогноз вперед на и назад на (соответственно прогнозируются данные вперед на указанное число периодов или определяется история данных назад на указанное число периодов); пересечение кривой с осью Y в точке (по умолчанию вычисляется на основе данных); показывать уравнение на диаграмме (Выводится уравнение аппроксимации на диаграмму в виде несвязанного текстового поля); поместить на диаграмму величину достоверности аппроксимации (осуществляется вывод на диаграмму величины R^2 в виде несвязанного текстового поля).