

к.п.и
.docxПроблемы, присущие многопроцессорным системам с общей памятью, простым и естественным образом устраняются в системах с массовым параллелизмом. Компьютеры этого типа представляют собой многопроцессорные системы с распределенной памятью, в которых с помощью некоторой коммуникационной среды объединяются однородные вычислительные узлы (рис. ).
|
|

Рис. 1.2. Архитектура систем с распределенной памятью.
Каждый из узлов состоит из одного или нескольких процессоров, собственной оперативной памяти, коммуникационного оборудования, подсистемы ввода/вывода, т.е. обладает всем необходимым для независимого функционирования. При этом на каждом узле может функционировать либо полноценная операционная система (как в системе RS/6000 SP2), либо урезанный вариант, поддерживающий только базовые функции ядра, а полноценная ОС работает на специальном управляющем компьютере (как в системах Cray T3E, nCUBE2).
Процессоры в таких системах имеют прямой доступ только к своей локальной памяти. Доступ к памяти других узлов реализуется обычно с помощью механизма передачи сообщений. Такая архитектура вычислительной системы устраняет одновременно как проблему конфликтов при обращении к памяти, так и проблему когерентности кэш-памяти. Это дает возможность практически неограниченного наращивания числа процессоров в системе, увеличивая тем самым ее производительность. Успешно функционируют MPP системы с сотнями и тысячами процессоров. Производительность наиболее мощных систем достигает 10 триллионов оп/сек (10 Tflops). Важным свойством MPP систем является их высокая степень масштабируемости. В зависимости от вычислительных потребностей для достижения необходимой производительности требуется просто собрать систему с нужным числом узлов.
На практике все, конечно, гораздо сложнее. Устранение одних проблем, как это обычно бывает, порождает другие. Для MPP систем на первый план выходит проблема эффективности коммуникационной среды. Легко сказать: "Давайте соберем систему из 1000 узлов". Но каким образом соединить в единое целое такое множество узлов? Самым простым и наиболее эффективным было бы соединение каждого процессора с каждым. Но тогда на каждом узле потребовалось бы 999 коммуникационных каналов, желательно двунаправленных. Очевидно, что это нереально. Различные производители MPP систем использовали разные топологии. В компьютерах Intel Paragon процессоры образовывали прямоугольную двумерную сетку. Для этого в каждом узле достаточно четырех коммуникационных каналов. В компьютерах Cray T3D/T3E использовалась топология трехмерного тора. Соответственно, в узлах этого компьютера было шесть коммуникационных каналов. Фирма nCUBE использовала в своих компьютерах топологию n-мерного гиперкуба. Каждая из рассмотренных топологий имеет свои преимущества и недостатки. Отметим, что при обмене данными между процессорами, не являющимися ближайшими соседями, происходит трансляция данных через промежуточные узлы. Очевидно, что в узлах должны быть предусмотрены какие-то аппаратные средства, которые освобождали бы центральный процессор от участия в трансляции данных. В последнее время для соединения вычислительных узлов чаще используется иерархическая система высокоскоростных коммутаторов, как это впервые было реализовано в компьютерах IBM SP2. Такая топология дает возможность прямого обмена данными между любыми узлами, без участия в этом промежуточных узлов.
Системы с распределенной памятью идеально подходят для параллельного выполнения независимых программ, поскольку при этом каждая программа выполняется на своем узле и никаким образом не влияет на выполнение других программ. Однако при разработке параллельных программ приходится учитывать более сложную, чем в SMP системах, организацию памяти. Оперативная память в MPP системах имеет 3-х уровневую структуру:
-
кэш-память процессора;
-
локальная оперативная память узла;
-
оперативная память других узлов.
При этом отсутствует возможность прямого доступа к данным, расположенным в других узлах. Для их использования эти данные должны быть предварительно переданы в тот узел, который в данный момент в них нуждается. Это значительно усложняет программирование. Кроме того, обмены данными между узлами выполняются значительно медленнее, чем обработка данных в локальной оперативной памяти узлов. Поэтому написание эффективных параллельных программ для таких компьютеров представляет собой более сложную задачу, чем для SMP систем.
Кластерные системы
Один из первых архитекторов кластерной технологии Грегори Пфистер (Gregory F. Pfister) дал кластеру следующее определение: «Кластер — это разновидность параллельной или распределённой системы, которая:
-
состоит из нескольких связанных между собой компьютеров;
-
используется как единый, унифицированный компьютерный ресурс».
Обычно различают следующие основные виды кластеров:
-
Отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности),
-
Кластеры с балансировкой нагрузки (Load balancing clusters),
-
Вычислительные кластеры (Computing clusters),
-
GRID- (РИВС-)-системы. В настоящее время распределенную информационно-вычислительную среду среду (РИВС) принято называть GRID (вычислительная решетка). Распределенная информационно-вычислительная среда состоит, как правило, из разных аппаратно-программных платформ, содержит компьютеры разных классов, в том числе персональные компьютеры, рабочие станции, мейн-фреймы, супер-ЭВМ.
Кластерные технологии стали логическим продолжением развития идей, заложенных в архитектуре MPP систем. Если процессорный модуль в MPP системе представляет собой законченную вычислительную систему, то следующий шаг напрашивается сам собой: почему бы в качестве таких вычислительных узлов не использовать обычные серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно, появление высокоскоростного сетевого оборудования и специального программного обеспечения, такого как система MPI, реализующего механизм передачи сообщений над стандартными сетевыми протоколами, сделали кластерные технологии общедоступными. Сегодня не составляет большого труда создать небольшую кластерную систему, объединив вычислительные мощности компьютеров отдельной лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. Широкое распространение кластерные технологии получили как средство создания систем суперкомпьютерного класса из составных частей массового производства, что значительно удешевляет стоимость вычислительной системы. В частности, одним из первых был реализован проект COCOA, в котором на базе 25 двухпроцессорных персональных компьютеров общей стоимостью порядка $100000 была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью в несколько миллионов долларов США.
Конечно, о полной эквивалентности этих систем говорить не приходится. Производительность систем с распределенной памятью очень сильно зависит от производительности коммуникационной среды. Коммуникационную среду можно достаточно полно охарактеризовать двумя параметрами: латентностью - временем задержки при посылке сообщения, и пропускной способностью - скоростью передачи информации. Например, для компьютера Cray T3D эти параметры составляют соответственно 1 мкс и 480 Мб/сек, а для кластера, в котором в качестве коммуникационной среды использована сеть Fast Ethernet, 100 мкс и 10 Мб/сек. Это отчасти объясняет очень высокую стоимость суперкомпьютеров. При таких параметрах, как у рассматриваемого кластера, найдется не так много задач, которые могут эффективно решаться на достаточно большом числе процессоров.
Если говорить кратко, то кластер - это связанный набор полноценных компьютеров, используемый в качестве единого вычислительного ресурса. Преимущества кластерной системы перед набором независимых компьютеров очевидны. Во-первых, разработано множество диспетчерских систем пакетной обработки заданий, позволяющих послать задание на обработку кластеру в целом, а не какому-то отдельному компьютеру. Эти диспетчерские системы автоматически распределяют задания по свободным вычислительным узлам или буферизуют их при отсутствии таковых, что позволяет обеспечить более равномерную и эффективную загрузку компьютеров. Во-вторых, появляется возможность совместного использования вычислительных ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластеров обычно используются либо простые однопроцессорные персональные компьютеры, либо двух- или четырех- процессорные SMP-серверы. При этом не накладывается никаких ограничений на состав и архитектуру узлов. Каждый из узлов может функционировать под управлением своей собственной операционной системы. Чаще всего используются стандартные ОС: Linux, FreeBSD, Solaris, Tru64 Unix, Windows NT. В тех случаях, когда узлы кластера неоднородны, то говорят о гетерогенных кластерах.
При создании кластеров можно выделить два подхода. Первый подход применяется при создании небольших кластерных систем. В кластер объединяются полнофункциональные компьютеры, которые продолжают работать и как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории. Второй подход применяется в тех случаях, когда целенаправленно создается мощный вычислительный ресурс. Тогда системные блоки компьютеров компактно размещаются в специальных стойках, а для управления системой и для запуска задач выделяется один или несколько полнофункциональных компьютеров, называемых хост-компьютерами. В этом случае нет необходимости снабжать компьютеры вычислительных узлов графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
Рисунок
2. Тесно связанная мультипроцессорная
система
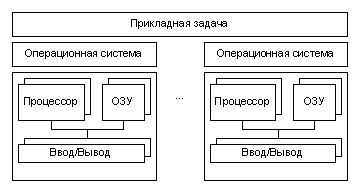 Рисунок
3. Умеренно
связанная мультипроцессорная система
Рисунок
3. Умеренно
связанная мультипроцессорная система

Разработано множество технологий соединения компьютеров в кластер. Наиболее широко в данное время используется технология Fast Ethernet. Это обусловлено простотой ее использования и низкой стоимостью коммуникационного оборудования. Однако за это приходится расплачиваться заведомо недостаточной скоростью обменов. В самом деле, это оборудование обеспечивает максимальную скорость обмена между узлами 10 Мб/сек, тогда как скорость обмена с оперативной памятью составляет 250 Мб/сек и выше. Разработчики пакета подпрограмм ScaLAPACK, предназначенного для решения задач линейной алгебры на многопроцессорных системах, в которых велика доля коммуникационных операций, формулируют следующим образом требование к многопроцессорной системе: "Скорость межпроцессорных обменов между двумя узлами, измеренная в Мб/сек, должна быть не менее 1/10 пиковой производительности вычислительного узла, измеренной в Mflops". Таким образом, если в качестве вычислительных узлов использовать компьютеры с процессорами класса Intel Core 2 Duo 2,4 ГГц (пиковая производительность 19,2 Гфлопс, т. е. 19200 Мфлопс), то аппаратура Fast Ethernet обеспечивает только 1/192 от требуемой скорости. Частично это положение исправляет переход на технологии Gigabit Ethernet.
2 Часть 2. Программное обеспечение суперкомпьютеров.
Назначение суперкомпьютеров. Области использования.
Суперкомпьютеры разрабатываются в первую очередь для того, чтобы с их помощью решать сложные задачи, требующие огромных объемов вычислений. При этом подразумевается, что может быть создана единая программа, для выполнения которой будут задействованы все ресурсы суперкомпьютера. Однако не всегда такая единая программа может быть создана или ее создание целесообразно. В самом деле, при разработке параллельной программы для многопроцессорной системы мало разбить программу на параллельные ветви. Для эффективного использования ресурсов необходимо обеспечить равномерную загрузку всех процессоров, что в свою очередь означает, что все ветви программы должны выполнить примерно одинаковый объем вычислительной работы. Однако не всегда этого можно достичь. Например, при решении некоторой параметрической задачи для разных значений параметров время поиска решения может значительно различаться. В таких случаях, видимо, разумнее независимо выполнять расчеты для каждого параметра с помощью обычной однопроцессорной программы. Но даже в таком простом случае могут потребоваться суперкомпьютерные ресурсы, поскольку выполнение полного расчета на однопроцессорной системе может потребовать слишком длительного времени. Параллельное выполнение множества программ для различных значений параметров позволяет существенно ускорить решение задачи. Наконец, следует отметить, что использование суперкомпьютеров всегда более эффективно для обслуживания вычислительных потребностей большой группы пользователей, чем использование эквивалентного количества однопроцессорных рабочих станций, так как в этом случае с помощью некоторой системы управления заданиями легче обеспечить равномерную и более эффективную загрузку вычислительных ресурсов.
В настоящее время, как уже говорилось выше, суперкомпьютерами принято называть компьютеры с вычислительной мощностью, намного превосходящей среднюю мощность недорогих общедоступных компьютеров. Эти машины используются для работы с приложениями, требующими наиболее интенсивных вычислений, в большинстве случаев - для ответа на «большие вызовы» (Grand challenges).
Grand challenges - это фундаментальные научные или инженерные задачи с широкой областью применения, эффективное решение которых возможно только с использованием мощных (суперкомпьютерных) вычислительных ресурсов. Основные области, где возникают задачи подобного рода (они же области применения суперкомпьютеров), это:
-
Предсказания погоды, климата и глобальных изменений в атмосфере,
-
Науки о материалах,
-
Построение полупроводниковых приборов,
-
Сверхпроводимость,
-
Структурная биология,
-
Разработка фармацевтических препаратов,
-
Генетика человека,
-
Квантовая хромодинамика,
-
Астрономия,
-
Транспортные задачи,
-
Гидро- и газодинамика,
-
Управляемый термоядерный синтез,
-
Эффективность систем сгорания топлива,
-
Разведка нефти и газа,
-
Вычислительные задачи наук о мировом океане и т. д.
-
Расчеты, производимые для военного ведомства – неизвестно точно, какие именно, но ясно, что очень сложные и нужные (как, например, обработка данных на РЛС).
Исключительность значения каждой из сфер в том числе отличает их от серверов и мэйнфреймов (англ. mainframe) — компьютеров с высокой общей производительностью, призванных решать типовые задачи (например, обслуживание больших баз данных или одновременная работа с множеством пользователей).
Вычислительная мощность компьютера
В свете предстоящего разбора характеристик программного обеспечения необходимо подробнее ознакомиться с тем, как именно определяется производительность компьютера.
Вычислительная мощность компьютера (производительность компьютера) — это количественная характеристика скорости выполнения определённых операций на компьютере. Чаще всего вычислительная мощность измеряется в флопсах (количество операций с плавающей точкой в секунду), а также производными от неё. Планка мощности компьютеров, для которых определена приставка «супер», в настоящее время постоянно изменяется в сторону увеличения.
Вариативность определения
Существует несколько сложностей при определении вычислительной мощности суперкомпьютера. Во-первых, следует иметь в виду, что производительность системы может сильно зависеть от типа выполняемой задачи. В частности, отрицательно сказывается на вычислительной мощности необходимость частого обмена данных между составляющими компьютерной системы, а также частое обращение к памяти. В связи с этим выделяют пиковую вычислительную мощность — гипотетически максимально возможное количество операций над числами с плавающей запятой в секунду, которое способен произвести данный суперкомпьютер. Важную роль играет также разрядность значений, обрабатываемых программой (обычно имеется в виду формат чисел с плавающей запятой). Оценка реальной вычислительной мощности производится путём прохождения специальных тестов (бенчмарков, benchmarks) — набора программ, специально предназначенных для проведения вычислений и измерения времени их выполнения. Обычно оценивается скорость решения системой большой системы линейных алгебраических уравнений, что обусловливается, в первую очередь, хорошей масштабируемостью этой задачи количеством уравнений. Наиболее популярным тестом производительности является Linpack benchmark. В частности, HPL (альтернативная реализация Linpack) используется для составлении Топ-500 листа суперкомпьютеров в мире (top500.org). Тест состоит в решении системы линейных арифметических уравнений методом LU-факторизации c выбором ведущего элемента столбца, где A – плотно заполненная матрица размерности N (первоначальный, «классический» вариант Linpack решал задачу размерности 100). Производительность в тесте Linpack измеряется в количестве производимых операций с плавающей запятой в секунду. Единицей измерения является 1 флопс, то есть одна такая операция в секунду. Поскольку количество операций, необходимое для решения задачи Linpack, известно с самого начала и зависит от ее размерности, измеряемая характеристика производительности получается как простое частное от деления этого известного числа операций на время, затраченное на решение задачи. С течением времени и увеличении вычислительной мощности компьютеров, размерность теста Linpack была увеличена до 1000. Однако с появлением все более мощных вычислительных систем и эта размерность стала чересчур малой, более того, для тестирования кластерных систем была создана отдельная версия теста в которой размерность матрицы (и некоторые другие параметры) не являются фиксированными, а задаются пользователем теста. Первоначально тест был написан на языке Fortran (и сейчас часто используется эта версия теста), однако для тестирования кластерных систем существует версия на языке C. Основное время теста (свыше 75% времени выполнения) занимает внутренний цикл, выполняющий типичную для действий с матрицами операцию. Другими популярными программами для проведения тестирования являются NAMD (решение задач молекулярной динамики), HPCC (HPC Challenge benchmark), NAS Parallel Benchmarks. Операционная система (ОС).
Операционная система. Обычно используется система Linux (91.8% от общего числа на конец 2010 г). Также продолжает использоваться Unix-система UNICOS (название нескольких вариантов операционной системы Unix, созданных компанией Cray для своих суперкомпьютеров). В кластерных системах, как было замечено выше, используются смешанные (mixed) программные решения. На долю Windows и BSD-решений остаются скромные 0, 8%. Процентное соотношение используемых ОС представлено на диаграмме

При фактической небольшой доле всех, кроме Linux, систем, логичным будет более подробно рассмотреть детище Торвальдса и его производные.
Linux
В ОС Linux имеется поддержка симметричных многопроцессорных архитектур, причем ее реализация не потребовала специальных серьезных изменений в ядре; в рамках постепенной эволюции ядра к нему был добавлен минимальный набор необходимых примитивов. Обычно используется система Linux в версиях, специально оптимизированных под распределенные параллельные вычисления. Оптимизация во многом заключалась в переработке ядра системы под новые задачи. В процессе построения кластеров выяснилось, что стандартные драйверы сетевых устройств в Linux весьма неэффективны. Поэтому были разработаны новые драйверы, в первую очередь для сетей Fast Ethernet и Gigabit Ethernet, и обеспечена возможность логического объединения нескольких параллельных сетевых соединений между персональными компьютерами (аналогично аппаратному связыванию каналов), что позволяет из дешевых локальных сетей, обладающих низкой пропускной способностью, соорудить сеть с высокой совокупной пропускной способностью. Как и в любом кластере, на каждом узле кластера исполняется своя копия ядра ОС. Благодаря доработкам обеспечена уникальность идентификаторов процессов в рамках всего кластера, а не отдельных узлов.
Абсолютно независимые процессы, не использующие совместных ресурсов, будут работать, по возможности используя каждый свой процессор со своей же порцией оперативной памяти, а их общая производительность при использовании двух процессоров вместо одного будет вдвое больше. Использование специальных средств координации необходимо только в том случае, когда два процесса пытаются одновременно получить доступ к одному ресурсу, как правило, лежащему в памяти. В этом случае операционная система должна организовать доступ к нему так, чтобы один процессор случайно не испортил результаты работы другого. Для этого в ОС Linux предусмотрена система контроля доступа к областям памяти и блокировок на чтение и запись.
UNICOS
Unicos обеспечивала работу сетевых кластеров и совместимость на уровне исходного кода с некоторыми другими разновидностями Unix. Unicos впервые была представлена в 1985 году, в качестве операционной системы суперкомпьютера Cray-2, а позднее была портирована и на другие модели Cray. Изначально основу Unicos составляла System V.2 с многочисленными добавлениями возможностей BSD (например, расширенные сетевые функции и улучшения файловой системы). Изначально система, известная сейчас как Unicos, носила название CX-OS. Это была экспериментальная система, работавшая на Cray X-MP в 1984 году до портирования на Cray-2. Она использовалась для демонстрации применимости Unix на суперкомпьютерах, прежде всего на доступном аппаратном обеспечении компании Cray. Обновление операционной системы было частью более большого движения внутри Cray Research по модернизации программного обеспечения предлагаемого компанией, включая переписывание её наиболее важного продукта, компилятора Фортрана, на языке более высокого уровня (Паскаль) с более современными оптимизацией и векторизацией. Windows Compute Cluster Server
В 2006 году корпорация Майкрософт выпустила системы Windows Server 2003 Compute Cluster Edition (CCE) и Windows Compute Cluster Server 2003 (WCCS), призванные обеспечить выполнение требований широкого ряда HPC-приложений. WCCS отличается от CCE только наличием пакета Microsoft® Compute Cluster Pack (CCP). Высокопроизводительные вычисления (High Performance Computing, HPC) — это раздел прикладной информатики, занимающийся в основном поиском путей решения задач, требующих большого количества вычислительных ресурсов. Как было упомянуто ранее, вычислительные кластеры предъявляют ряд базовых требования, которые выполняются путем установки пакета Compute Cluster Pack. CCP — это самостоятельный установочный пакет, включающий в себя следующие компоненты:
-
поддержку интерфейса MPI для отраслевого стандарта MPICH2;
-
инструменты пользователя и средства управления ресурсами кластера;
-
встроенный планировщик заданий.
Организация параллельных вычислений.
В вычислительных системах с распределенной памятью процессоры работают независимо друг от друга. Для организации параллельных вычислений в таких условиях необходимо иметь возможность распределять вычислительную нагрузку и организовать информационное взаимодействие (передачу данных) между процессорами. Наиболее распространёнными программными средствами суперкомпьютеров, также как и параллельных или распределённых компьютерных систем, являются интерфейсы программирования приложений (API) на основе MPI и PVM, и решения на базе программного обеспечения, позволяющего создавать суперкомпьютеры даже на базе обыкновенных рабочих станций и персональных компьютеров. Среди пользователей Linux популярны несколько программ: distcc, MPICH — специализированные средства для распараллеливания работы. программ. Linux Virtual Server, Linux-HA — узловое ПО для распределения запросов между вычислительными серверами. MOSIX, openMosix, Kerrighed, OpenSSI — полнофункциональные кластерные среды, встроенные в ядро, автоматически распределяющие задачи между однородными узлами. OpenSSI, openMosix и Kerrighed создают среду единой операционной системы между узлами.
Как было сказано выше, интерфейсы API обычно строятся на основе MPI и PVM. MPI (Message Passing Interface - интерфейс передачи сообщений), PVM (Parallel Virtual Machine - параллельная виртуальная машина).
Обе системы реализуют модель передачи сообщений, содержат библиотеки функций и подпрограмм для стандартных языков программирования С, С++, Fortran обеспечивают взаимодействия "точка-точка" и групповые. В то же время системы имеют и существенные отличия. И PVM, и MPI предоставляют возможность логической связи машин в единую вычислительную систему. И PVM, и MPI содержит больше количество библиотек разработки параллельных программ для языков Fortran, C, Python, Java а так же для многих других. Обе системы реализуют модель передачи сообщений.
Прикладное программное обеспечение
Иногда суперкомпьютеры используются для работы только с одним приложением, использующим всю память и все процессоры системы; в других случаях они обеспечивают выполнение большого числа разнообразных приложений. Сегодня можно говорить о том, что практически для всех задач суперкомпьютинга успешно применяются кластерные системы — от расчетов для науки и промышленности до управления базами данных. Фактически любые приложения, требующие высокопроизводительных вычислений, имеют сейчас параллельные версии, которые позволяют разбивать задачу на фрагменты и обсчитывать ее параллельно на многих узлах кластера. Например, для инженерных расчетов (прочностные расчеты, аэромеханика, гидро- и газодинамика) традиционно применяются так называемые сеточные методы, когда область вычислений разбивается на ячейки, каждая из которых становится отдельной единицей вычислений. Эти ячейки обсчитываются независимо на разных узлах кластера, а для получения общей картины на каждом шаге вычислений происходит обмен данными, распространенными в пограничных областях. Наиболее популярные параллельные прикладные программные пакеты: 1) инженерные: - СFD, CAD, CAE, т. е. гидро- и газодинамика, прочностной анализ, проектирование и расчет конструкций: программные пакеты FLUENT компании Fluent, пакеты STAR-CD и STAR CCM+, MAGMASOFT, Altair HyperWorks, в том числе российская разработка FlowVision от компании «ТЕСИС». - расчеты столкновения конструкций и FEA (конечно-элементный анализ): LS-DYNA от LSTC, программные пакеты от ABAQUS, ANSYS, MSC.Software; 2) поиск новых лекарств, генетика и др. — программные пакеты от TurboWorx; 3) ПО для обработки геофизических данных для нефтедобывающей отрасли: программные средства компаний Paradigm, Schlumberger.