

Статистика
.pdfТогда ранговый коэффициент корреляции Спирмена вычисляется по формуле:
|
|
1 |
(n3 − n)−∑n (xi(k ) − xi( j) )2 −T (k ) −T (j ) |
|
|
||||||||||||
τ S = |
|
6 |
. |
(4.3.3) |
|||||||||||||
|
|
|
|
|
|
|
i=1 |
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
ˆkj |
|
[ |
1 |
(n3 − n)− 2T (k )][ |
1 |
(n3 − n)− 2T (j )] |
|
|
|||||||||
|
|
|
6 |
6 |
|
|
|||||||||||
Для проверки гипотезы об отсутствии статистически значимой |
|||||||||||||||||
корреляционной связи проверяется гипотеза |
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
H0 : τkjS |
= 0 . |
|
|
|
|
||||
Гипотеза H0 принимается при уровне значимости α = 0.05 , если |
|||||||||||||||||
|
|
|
|
|
|
|
|
τ S |
|
|
|
|
|
|
|
||
|
|
|
|
|
t = |
|
ˆkj |
n − 2 < tγ , f , |
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
1−(τˆkjS )2 |
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
где tγ , f − пороговое значение распределения Стьюдента с параметрами
γ =1−α 2 , f = n − 2 . В противном случае, гипотезаотклоняется.
2 , f = n − 2 . В противном случае, гипотезаотклоняется.
Если необходимо определить степень тесноты статистической
связи между m ранжировками, |
2 ≤ m ≤ p , то для этого используется |
|||||||||
коэффициент конкордации Кендалла: |
|
|
|
|||||||
|
|
|
12 |
|
n m (k j ) |
m(n +1) 2 |
|
|||
ˆ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
W (m)= |
m |
2 |
(n |
3 |
|
∑ |
∑xi − |
2 |
. |
(4.4.4) |
|
|
|
− n)i=1 |
j=1 |
|
|
||||
Здесь
m − количество выбранных для анализа ранжировок; n − длина ранжировок;
k j , j =1, m − номера отобранных для анализа ранжировок.
0 ≤W (m)≤1.
33

Формула (4.4.4) также пригодна только для случая, если ни одна из исследуемых ранжировок не содержит повторяющихся рангов. Иначе, используя поправки (4.3.2), коэффициент конкордации рассчитывается по формуле:
|
n |
m (k j ) |
|
m(n +1) 2 |
|
|||
|
|
∑xi − |
|
|
|
|
||
ˆ |
∑ |
2 |
|
|
|
|||
i=1 |
j=1 |
|
|
|
|
|
||
W (m)= |
m2 |
(n3 − n) |
− m∑m |
T (k j ) |
. |
(4.3.5) |
||
|
|
12 |
|
j=1 |
|
|
|
|
Для проверки гипотезы об отсутствии статистически значимой корреляционной связи между выбранными ранжировками проверяется гипотеза
H0 : W (m)= 0 .
Гипотеза H0 принимается при уровне значимости α = 0.05 , если m(n −1)Wˆ (m)< χα2,n−1 .
Впротивном случае, гипотеза отклоняется.
Задача.
Втаблице приведены данные успеваемости учеников одного класса по математике, физике, литературе и иностранному языку.
|
Математика |
Физика |
Литература |
Ин. яз. |
1 |
3 |
3 |
4 |
4 |
2 |
5 |
5 |
5 |
5 |
3 |
4 |
4 |
4 |
3 |
4 |
4 |
3 |
4 |
4 |
5 |
3 |
3 |
4 |
5 |
6 |
3 |
4 |
5 |
4 |
7 |
5 |
5 |
4 |
5 |
8 |
5 |
4 |
4 |
5 |
34

9 |
4 |
4 |
5 |
5 |
10 |
3 |
3 |
4 |
3 |
11 |
4 |
3 |
4 |
3 |
12 |
4 |
4 |
5 |
5 |
13 |
5 |
5 |
5 |
5 |
14 |
3 |
4 |
3 |
4 |
15 |
3 |
3 |
3 |
3 |
16 |
5 |
5 |
4 |
4 |
17 |
4 |
4 |
4 |
4 |
18 |
4 |
4 |
3 |
3 |
19 |
5 |
4 |
4 |
4 |
20 |
5 |
5 |
4 |
3 |
21 |
3 |
3 |
5 |
5 |
22 |
4 |
3 |
5 |
5 |
23 |
4 |
4 |
5 |
4 |
24 |
3 |
3 |
5 |
4 |
25 |
4 |
5 |
4 |
4 |
Определить, есть ли связь между успеваемостью учащихся по каждой паре предметов.
Решение. Применение пакета Statistica для расчетов коэффициентов Спирмена дает следующие результаты:
|
Математика |
Физика |
Литература |
Ин. яз. |
|
|
|
|
|
|
|
Математика |
* |
τ = 0.7294 |
τ = 0.0649 |
τ = 0.2157 |
|
t = 5.113 |
t = 0.312 |
t = 1.059 |
|||
|
|
||||
|
|
|
|
|
|
Физика |
τ = 0.7294 |
* |
τ = 0.0465 |
τ = 0.1557 |
|
t = 5.113 |
t = 0.223 |
t = 0.756 |
|||
|
|
||||
|
|
|
|
|
|
Литература |
τ = 0.0649 |
τ = 0.0465 |
* |
τ = 0.58556 |
|
|
t = 0.312 |
t = 0.223 |
|
t = 3.464 |
|
|
|
|
|
|
|
Ин. яз. |
τ = 0.2157 |
τ = 0.1557 |
τ = 0.5856 |
* |
|
t = 1.059 |
t = 0.756 |
t = 3.464 |
|||
|
|
||||
|
|
|
|
|
35
Так как у нас имеется |
25 наблюдений, то есть |
n = 25 , то число |
||||||||
степеней свободы |
f = n − 2 = 23 . |
Пороговое значение распределения |
||||||||
Стьюдента |
при |
уровне |
значимости |
α = 0.05 |
и |
f = 23 |
равно |
|||
t0.975,23 = 2.068658 . |
Сравнивая |
значения |
величин |
t |
из |
таблицы с |
||||
пороговым значением, получаем, что в тех случаях, когда |
t ≥ tγ , f |
|||||||||
выносится |
решение |
о |
наличии |
статистически |
значимой |
|||||
корреляционной |
связи. |
Такая |
ситуация имеет |
|
место |
для пар |
||||
«Математика – Физика» и «Литература – Иностранный язык», в то время, как для других пар предметов такой связи нет. Так, например, если учащийся имеет хорошие результаты по математике, у него, вероятно, будут хорошие результаты по физике, при этом это ничего не говорит об его успеваемости по другим предметам. И наоборот.
4.4 Корреляционный анализ категоризованных данных. Таблицы сопряженности.
Пусть рассматриваются n объектов на наличие в них двух признаков A и B . Пусть при этом признак A может иметь m различных значений, а B − k различных значений. Обозначим через nij количество элементов выборки, обладающих i -тым значением признака A и j -тым значением признака B . Предполагается, что один и тот же объект не может обладать одновременно несколькими уровнями одного признака.
Необходимо установить, влияет ли наличие у объекта признака A , на проявление в нем признака B , или обуславливает ли изменение уровней признака A изменения признака B .
36

Категоризованные данные – это набор перекрестных частот nij ,
i =1, m , j =1, k , ∑nij = n двух признаков A и B , значения которых
i, j
зафиксированы на конечном числе уровней. Данные (частоты) представляются в таблице сопряженности следующего вида:
Уровни |
|
Уровни признака |
B |
Σ |
|||
признака A |
|
|
|
|
|
|
|
1 |
|
2 |
… |
|
k |
|
|
|
|
|
|
|
|
|
|
1 |
n11 |
|
n12 |
… |
|
n1k |
n1• |
2 |
n21 |
|
n22 |
… |
|
n2k |
n2• |
… |
… |
|
… |
… |
|
… |
… |
|
|
|
|
|
|
|
|
m |
nm1 |
|
nm2 |
… |
nmk |
nm• |
|
Σ |
n•1 |
|
n•2 |
… |
n•k |
n |
|
Статистический анализ перекрестных частот позволяет ответить на вопрос о существовании зависимости между признаками непараметрически, т.е. при неизвестных распределениях рассматриваемых величин.
Степень тесноты статистической зависимости двух признаков можно определить с помощью коэффициента X 2 квадратичной сопряженности признаков A и B
|
|
|
m k |
2 |
|
X |
|
= n |
∑∑ |
nij |
−1 . |
|
2 |
|
|
|
|
|
|
i=1 j=1 ni•n• j |
|
||
37

Величина X 2 равна нулю при строгой статистической независимости признаков A и B . С ростом степени зависимости признаков величина X 2 может расти до +∞ . В предположении статистической независимости переменных A и B величина X 2
имеет χ2 -распределение с (m −1)(k −1) степенями свободы. Если выполнено неравенство
X 2 < χα2,(m−1)(k−1) ,
при уровне значимости α гипотеза H0 об отсутствии значимой статистической связи между A и B принимается.
Замечание. Аналогичным образом проверяется гипотеза о независимости двух случайных выборок. В этом случае в качестве уровней признаков берутся варианты рассматриваемых случайных величин.
Самый простой случай, когда признаки имеют всего два возможных уровня: наличие это признака у объекта, либо его отсутствие. Тогда таблица сопряженности имеет вид:
Уровни |
Уровни признака |
B |
||||||
признака A |
|
|
|
|
|
|
||
B |
|
|
|
|
Σ |
|||
B |
||||||||
|
A |
n11 |
n12 |
|
n1• |
|||
|
|
|
n21 |
n22 |
|
n2• |
||
|
A |
|
||||||
Σ |
n•1 |
n•2 |
|
n |
||||
Тогда условие независимости признаков A и B по теореме умножения вероятностей может записано в виде
P(A)= P(A | B)= P(A | B ),
38
|
|
|
P(A)= P(A | B)= |
P(AB) |
. |
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
P(B) |
|
|
|
|
|
|||||
Запишем оценки соответствующих вероятностей через частоты |
||||||||||||||||||||||
указанные в таблице: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
P(A)= |
|
n11 + n12 |
, |
|
P(AB) |
= |
|
|
n11 |
|
|
. |
|
|
|||||||
|
|
|
n |
|
P(B) |
|
n + n |
21 |
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11 |
|
|
|
|
||||
Приравнивая |
последние |
|
величины и |
выражая |
n11 получаем |
|||||||||||||||||
соотношение, справедливое при независимости признаков A и B : |
|
|||||||||||||||||||||
|
|
|
n = |
(n11 + n12 )(n11 + n21 ) |
. |
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
11 |
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
Если признаки A и B зависимы, |
то будут |
наблюдаться |
||||||||||||||||||||
отклоненияот этого равенства. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
Так, если n |
> |
(n11 + n12 )(n11 + n21 ) |
, то говорят, |
что признаки A |
и |
|||||||||||||||||
|
|
|||||||||||||||||||||
11 |
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
B положительно связаны. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Иначе, если n < |
(n11 + n12 )(n11 + n21 ) |
, то говорят, что признаки |
A |
|||||||||||||||||||
|
||||||||||||||||||||||
|
11 |
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
и B отрицательно связаны.
По статистическим данным получить равенство крайне сложно, поэтому речь идет о степени отклонения от него. Величиной характеризующей это отклонение является
D = n − |
(n11 + n12 )(n11 + n21 ) |
= |
n11n22 − n12n21 |
. |
|
|
|||
11 |
n |
|
n |
|
|
|
|||
На базе нее строится коэффициент сопряженности в виде:
Q = |
|
nD |
|
|
= |
n11n22 |
− n12n21 |
. |
||||
|
n n |
22 |
+ n |
n |
21 |
|
n n |
22 |
+ n |
n |
21 |
|
|
11 |
12 |
|
11 |
12 |
|
|
|||||
39
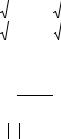
Тогда гипотеза об отсутствии статистически значимой корреляционной связи между исследуемыми признаками принимается, если
В противном случае гипотеза отклоняется и выносится решение о статистической связи.
Также может быть использован коэффициент
Υ = |
|
n11n22 |
− |
n12n21 |
|
, |
||||
|
|
|
|
|
|
|
|
|||
n n |
22 |
+ |
n |
n |
21 |
|||||
|
|
|
|
|||||||
|
|
11 |
|
12 |
|
|
|
|||
который, очевидно, связан с Q следующим соотношением
Q= 1+2ΥΥ2 .
Υ≤1.
Υ= 0 и Q = 0 при статистической независимости признаков A и B .
40