

Дляттест1-Лекции
.pdfОсновная идея ввода типов изображений состоит в том, что мы можем сравнивать алгоритмы только на определенных типах изображений. Вообще говоря, бессмысленно говорить, что один алгоритм лучше другого, не указав тип изображений, на котором они сравниваются.
2Требования к алгоритмам компрессии.
Одни приложения могут предъявлять различные требования к алгоритмам
компрессии, с другой стороны для других приложений эти же требования могут быть не актуальны.
Высокая степень компрессии. Данное требование почти всегда актуально, хотя есть и исключения. Хотя в большинстве случаев приходится искать некоторый компромисс со следующим требованием, а именно
Высокое качество изображения, которое, вообще говоря, противоречит выполнению предыдущего. Кстати, довольно часто алгоритм предоставляет возможность выбора качества архивации (например, JPEG), и соответственно, степени архивации. В случае необходимости 100% соответствия используются алгоритмы сжатия без потерь.
Высокая скорость компрессии. Интуитивно понятно, что чем больше времени мы будем анализировать изображение, тем лучше будет результат. Таким образом, оно также может входить в противоречие с двумя предыдущими. В некоторых алгоритмах, например фрактальном, можно управлять временем компрессии, естественно, в некоторый (возможно незаметный) ущерб качеству.
Стоит также отметить, что важно также не только сама скорость, а скорее ее зависимость от, например, размеров изображения. Реализация фрактального алгоритма ―в лоб‖ приведет вообще говоря, к зависимости n2 от площади изображения.
Высокая скорость декомпрессии. Достаточно универсальное требование, хотя стоит отметить, что иногда более, а иногда менее актуально.
Возможность постепенного проявления изображения, т.е. возможность показать огрубленное изображение, использовав только начало файла. Данное требование стало актуально в web, когда пользователь может, например, решить, продолжать ему закачку большой картинки или нет, скачав только его часть. Иногда эта возможность является свойством алгоритма (например, wavelet), иногда алгоритм можно модифицировать. (В алгоритме Motion JPEG, например, изменили порядок записи коэффициентов, чтобы сначала шли низко, потом средне, а потом высокочастотные компоненты изображения. В алгоритме Interlaced GIF поступили еще проще, просто записывая строчки изображения не подряд, а через четыре)
Устойчивость к ошибкам, или локальность нарушений при порче фрагмента файла. В случае широковещания в сети, или цифрового телевидения, не исключена возможность того, что часть данных не дойдет до пользователя. Не хотелось бы, чтобы порча одного маленького кусочка приведет к невозможности посмотреть весь фильм целиком.
Редактируемость. Под редактируемостью понимается минимальная степень ухудшения качества изображения, при его повторном сохранении после редактирования. Если изображение было сжато с потерями, потом разжато, потом
41
слегка отредактировано (например, пара пикселей поменяли цвет), то этот параметр определит, насколько изображение потеряет в качестве еще. Иногда, изображение может терять в качестве даже безо всякого редактирования, что обусловлено, скорее всего, несовершенством реализации алгоритма, иногда же, например, при фрактальном сжатии, самим алгоритмом.
Небольшая стоимость аппаратной и (или) эффективность программной реализации. Это требование важно, например, при проектировании алгоритмов сжатия текстур, с учетом дальнейшей интеграции этих алгоритмов в видеочип. Также стоит оценить эффективность таких технологий MMX, 3DNow! и Katmai, и возможность эффективного распараллеливания алгоритмов.
Вообще говоря, в каждом конкретном случае одни требования нам более важны, другие менее важны, или совсем безразличны. Более того, иногда выбор того или иного алгоритма определяется некоторыми специфическими требованиями. Например, при архивации текстур нам бы хотелось получить информацию о конкретном пикселе как можно меньшими затратами.
3Критерии сравнения алгоритмов.
Основным критерием является коэффициент сжатия и скорость компрессии и
декомпрессии. Лучший, худший и средний коэффициенты сжатия. Следует отметить, что средний коэффициент следует считать по отношению к тем изображениям, на которые ориентирован алгоритм (например, реальную эффективность алгоритма сжатия факсимильных сообщений бессмысленно измерять на тесте из фотографий). Худший коэффициент, кстати, может быть и больше 1.
4 Алгоритмы архивации без потерь.
При рассмотрении алгоритмов без потерь, стоит отметить несколько важных моментов. Во-первых, поскольку алгоритмы не изменяют исходные данные, то мы можем считать любой алгоритм сжатия информации алгоритмом сжатия изображений без потерь (кстати, не так много алгоритмов сжатия без потерь разрабатывались специально для изображений)
Во-вторых, невозможно построить алгоритм сжатия без потерь, который для любой первоначальной цепочки данных давал бы меньшую по длине цепочку. Если есть цепочки, которые алгоритм укорачивает, то есть те, которые он удлиняет. Хотя, впрочем, можно модифицировать алгоритм, так чтобы в худшем случае увеличение составляло всего 1 бит, а именно, в случае если алгоритм увеличивает цепочку, писать в выходной поток единицу, а потом исходную цепочку, в противном случае писать ноль и архивированную цепочку.
Методы сжатия
Метод |
BMP |
GIF |
PNG |
JPEG |
RLE |
X |
|
|
X |
LZ |
|
X |
X |
|
Huffman |
|
|
X |
X |
DCT |
|
|
|
X |
42
Метод RLE – кодирование длин серий.
Последовательные пиксели с одинаковым значением кодируются с помощью пары чисел. Эти числа включают длину серии и значение пикселя. Например, 9 повторяющихся пикселей со значением равным 8, можно представить в виде 2- байтовой последовательности
09160816 вместо 081608160816081608160816081608160816
Метод LZ. Программа сжатия ведет словарь, который содержит уже встречавшиеся последовательности значений пикселей. Сжатый поток содержит коды, указывающие элементы словаря.
Кодирование Хаффмана (Huffman). Для представления значений компонент используются коды переменной длины. Значениям, которые повторяются чаще, присваиваются более короткие коды.
Метод DCT (дискретное косинусное преобразование). Блоки пикселов представляются с помощью косинусных функций с разными частотами. Высокие частоты, которые обычно вносят малый вклад в данные изображений, отбрасываются.
Большинство форматов файлов изображений используют сжатие без потерь. Под этим понимают, что если взять изображение, сжать его по технологии сжатия без потерь, а затем восстановить, то получившееся изображение будет идентично оригиналу с точностью до бита. Метод сжатия с потерями дает после распаковки изображение только близкое к оригиналу. В этом случае используют тот факт, что человеческому взгляду трудно различить почти одинаковые цвета. Методы сжатия с потерями используются потому, что они обеспечивают гораздо большую степень сжатия.
Алгоритмы сжатия для формата .BMP
Формат BMP поддерживает простое RLE-сжатие изображений с 4 и 8 битами на пиксель.
Кодирование длин серий (RLE) является одной из простейших технологий сжатия. В этом методе данные сохраняются таким образом, что повторяющиеся значения замещаются числом, равным их количеству. Данный тип сжатия подходит только для изображений с множеством повторяющихся значений, например, мультипликационные рисунки. Для изображений многих типов кодирование длин серий (RLE) создает файл, размер которого больше исходного (отрицательное сжатие). Формат сжатых данных зависит от числа битов на пиксель.
Метод сжатия RLE8
В методе сжатия RLE8 сжимаемые данные разбиваются на 2-байтовые пары. Первый байт равен количеству повторяющихся значений пикселей, а второй байт равен значению пикселя, которое повторяется. В изображении с 8 битами на пиксель байтовая последовательность:
0816 0016 16 –ая система счисления разворачивается в следующую последовательность значений пикселей
0016 0016 0016 0016 0016 0016 0016 0016 0016 (первые 00 – счетчик повтора) Счетчик повторов равный нулю используется в качестве управляющего
кода. Нулевое значение, за которым следует другое нулевое значение, означает переход к следующей строке в изображении. Нулевое значение, за которым
43

следует 1, означает конец изображения. Нуль, за которым следует байт, содержащий значение 2, изменяет текущее положение в изображении. Следующие два байта являются значениями без знака, которые равны, соответственно, числу столбцов и строк, на которые следует выполнить переход в новое положение. Этот код позволяет пропускать большое число пикселей с нулевыми значениями. Кодовая последовательность:
0416 1516 0016 0016 0216 1116 0216 0316 0016 0116
разворачивается в следующие две строки:
1516 1516 1516 1516
1116 1116 0316 0316
Конец изображения.
Из приведенного описания метода сжатия нетрудно заключить, что если изображение не содержит последовательных байтов с одинаковым значением, итоговый размер данных изображения превысит размер эквивалентных несжатых данных.
Метод сжатия RLE4
Формат RLE4 почти идентичен формату RLE8. Основное различие заключается в том, что при кодировании значений цвета байт данных, который следует за числом-счетчиком, содержит два значения пикселей. Значение четырех старших битов используется для кодирования первого и всех последующих нечетных пикселей в серии, в то время как четыре младших бита используются для кодирования второго и остальных четных пикселей. Таким образом, формат RLE4 позволяет кодировать серии одинаковых значений пикселя или два чередующихся значения. Данная закодированная пара:
0516 5616
разворачивается в следующую последовательность 4-битовых значений:
5 6 5 6 5
Все управляющие коды метода RLE4 совпадают с управляющими кодами метода RLE8. Заключение
Если вы разрабатываете программное обеспечение для чтения и записи графических файлов в среде Windows, формат Windows BMP будет наилучшим выбором для тестирования ваших программ. Его несложно реализовать и отладить, и, кроме того, файлы данного формата можно просматривать без использования специальных программных средств. При чтении или записи двоичных файлов изображений следует открывать их в двоичном режиме (binary mode).
Кодирование по Хаффману.
Один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт в изображении (статистическое кодирование). Сопоставляет символам входного потока, которые встречаются большее число раз, цепочку бит меньшей длины. И, напротив, встречающимся редко - цепочку большей длины. Длина кода для символа пропорциональна двоичному логарифму его частоты, взятому с обратным знаком. Для сбора статистики требует двух проходов по
44
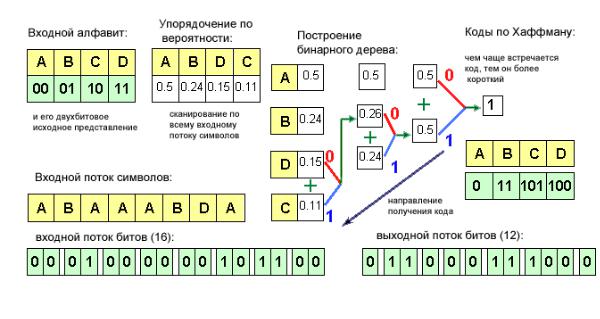
изображению. Классический алгоритм Хаффмана требует записи в файл таблицы соответствия кодируемых символов и кодирующих цепочек.
Для последовательности из 100 символов (см. рис.), в которой символ A встретится 50 раз, символ B - 24 раза, символ D - 15 раз, а символ C - 11 раз, данный код позволит получить последовательность из 176 бит, т.е. в среднем мы потратим 1.76 бита на символ потока. На практике используются различные разновидности алгоритма Хаффмана. Так, в некоторых случаях используется либо постоянная таблица, либо строится "адаптивно", т.е. в процессе архивации/разархивации. Эти приемы избавляют от двух проходов по изображению и от необходимости хранения таблицы вместе с файлом. Коэффициенты компрессии: лучший 8, средний 1,5, худший 1. Единственный алгоритм, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом). Класс изображений: Практически не применяется к изображениям в чистом виде. Обычно используется как один из этапов компрессии в более сложных схемах. Симметричность: 2 (за счет того, что требует двух проходов по массиву сжимаемых данных).
Режимы сжатия JPEG
Первоначальный стандарт JPEG определял четыре режима сжатия: иерархический, прогрессивный, последовательный и без потерь
Последовательный режим
Последовательный режим является простейшим режимом JPEG. Последовательный режим сжатия обеспечивает кодирование изображения сверху вниз. Последовательный режим поддерживает дискретизацию данных с точностью 8 и 12 битов.
В последовательном JPEG каждый цветовой компонент полностью кодируется в один скан - блок сжатых данных, который содержит результаты одного прохода по изображению для одного или нескольких компонентов. В
45
большинстве форматов все сжатые данные пикселов хранятся в одной непрерывной области файла. В формате JPEG каждый проход по изображению сохраняется в отдельном блоке данных, называемом сканом.
В рамках метода последовательного сжатия стандарт JPEG определяет два альтернативных процесса кодирования. Один использует кодирование Хаффмана (Huffman), а в другом применяется арифметическое кодирование.
Прогрессивный режим
В JPEG-изображениях с прогрессивным сжатием компоненты кодируются во множестве сканов. Сжатые данные для каждого компонента помещаются не менее чем в 2, и не более чем в 896 сканов, хотя факти ческое их число почти всегда находится на нижней границе этого диапазона. Начальные сканы создают грубую версию изображения, тогда как последующие сканы улучшают его качество. Изображения с прогрессивным сжатием предназначены для просмотра во время их декодирования. Они удобны, когда изображение загружается по сети или просматривается в Web-браузере, поскольку позволяют пользователю получить представление о содержании изображения после передачи как минимально возможного количества данных.
Основные недостатки прогрессивного режима заключаются в том, что его труднее реализовать, чем последовательный режим, а также в том, что если изображение просматривается по мере его загрузки, требуется значительно больший объем обработки. Прогрессивный JPEG наиболее выгоден тогда, когда относительная вычислительная мощность превышает относительную скорость передачи изображения. В целом, размеры файлов изображений, сжатые в прогрессивном и последовательном режимах, примерно одинаковы, прогрессивный режим встречается редко.
Иерархический режим
Иерархический JPEG представляет собой суперпрогрессивный режим, в котором изображение разделяется на множество фрагментов, называемых кадрами. Кадр представляет собой группу из одного или нескольких сканов. В иерархическом режиме первый кадр создает версию изображения с низким разрешением. Остальные кадры улучшают качество изображения путем повышения разрешения.
Сторонники этого метода утверждают, что при низкой скорости передачи данных иерархический режим лучше, чем прогрессивный режим. Если нужно получить только изображение с низким разрешением, для достижения желаемого результата достаточно использовать только часть из всех существующих кадров.
Очевидным недостатком иерархического режима является его сложность. а использование множества кадров увеличивает количество данных, которые должны передаваться.
Режим сжатия без потерь
Первоначальный стандарт JPEG определял режим сжатия без потерь, который всегда сохраняет точное исходное изображение. Режим без потерь никогда не может достичь такого же сжатия, как режим сжатия с потерями. Более того, в большинстве случаев применения он не обеспечивал такого же сжатия, как форматы, существовавшие на тот момент, поэтому не было побудительных
46
причин для его использования. В настоящее время разработан новый метод сжатия без потерь, известный как JPEG-LS, что сделало первоначальный формат сжатия без потерь морально устаревшим для всех практических сфер применения.
Режимы арифметического кодирования защищены патентами, и чтобы их использовать, необходимо платить за лицензию владельцам патентов. Кодирование Хаффмана и арифметическое кодирование используются разными процессами для выполнения идентичных функций. Если два метода делают одно и то же, но применение одного из них требует лицензионных выплат, а применение второго - нет, который из них вы бы выбрали? Помимо вопросов оплаты лицензии, патенты делают невозможным создание общедоступных (бесплатных) реализаций некоторых функций JPEG.
Это составляет важнейшую причину того, почему большинство режимов кодирования JPEG редко используются на практике. Для того чтобы формат графического файла получил всеобщее признание, кто-то должен разработать программное обеспечение для работы с этим форматом и сделать его доступным для других пользователей. Формат изображений, который нельзя использовать для обмена данными между множеством различных программ, малополезен. Проблема реализации усложняется тем, что стандарт JPEG бесплатно не доступен. Стандарты всех других основных форматов графических файлов обращаются свободно, но с JPEG это не так. Вы должны приобрести копию стандарта у своего национального представителя международной организации по стандартизации (ISO), а это недешево. Если формат слишком сложен, обладает ограниченным значением или требуется плата за лицензию, маловероятно, что кто-либо возьмет на себя хлопоты по написанию для него программного кода и сделает этот код общедоступным.
Это алгоритм сжатия с потерями придуманный Объединенной группой экспертов по фотографии (Joint Photographic Experts Group). Хорошо подходит для фото-изображений, имеет коэффициент сжатия до 20. В нем изображение проходит через несколько стадий сжатия:
1.Сначала изображение прореживается по цвету. Человеческий глаз более чувствителен к изменениям яркости, чем и изменению цвета. Сначала изображение переводится в систему YUV (Y-яркость, U,V- цветовые составляющие). Затем цветовые составляющие прореживаются, так, что из каждого квадратика пикселей 2х2 исходного изображения получается один пиксель (фактически изображение приводится к вдвое меньшему разрешению). За счет этого происходит сжатие в
(4+4+4)/(4+1+1)=2раза.
2.Изображение разбивается на квадратики 8х8 пикселей и к каждому такому квадратику применяется дискретное косинусное преобразование (по каждой составляющей). Его цель – перейти к спектру значений яркости и цветности в квадратике. Так как глаз более чувствителен к низкочастотным составляющим спектра, а высокочастотные воспринимаются как шум – можно отбросить несколько высокочастотных коэффициентов, и за счет этого получить сжатие. Чем больше коэффициентов будет отброшено, тем больше коэффициент сжатия и искажения изображения.
3.Наконец, эти коэффициенты кодируются с помощью RLE и Хаффмана.
47
Алгоритм сжатия данных LZW
Алгоритм основан на поиске и замене в исходном файле одинаковых последовательностей данных для их исключения и уменьшения размера файла, алгоритм сводит избыточность к минимуму. Кодируются часто встречающиеся последовательности символов, а не один символ. Программа алгоритма просматривает файл с байтами графической информации и выполняет статистический анализ для построения кодовой таблицы. Данный тип сжатия не вносит искажений в исходный графический файл и подходит для обработки растровых данных любого типа: чернобелых, монохромных, полноцветных. Лучшие результаты получаются при компрессии изображений с большими областями одного цвета или с повторяющимися структурами.
Алгоритм S3TC.
Это алгоритм сжатия текстур (S3 Texture Compression). Это достаточно простой метод, изображение разбивается на квадратики 4х4, каждый квадратик приводится к палитре в 4 цвета. Это сжатие с потерями. При этом распаковка происходит очень быстро, что важно для текстур.
Алгоритм MPEG.
Это алгоритм сжатия видео, здесь используется предположение, что соседние кадры мало отличаются друг от друга. Поэтому достаточно описать лишь разницу между ними. В этом алгоритме изображение, как и в JPEG, прореживается по цвету, а затем разбивается на блоки 16x16. Первый кадр кодируется как обычное изображение, а для последующего для каждого блока ищется наиболее похожий блок в предыдущем кадре. Причем он может быть смещен на некоторый вектор. Если блоки совпадают полностью – можно просто сохранить этот вектор, если отличаются – то можно сохранить разницу между ними, она должна занять меньше места, чем сам блок. Кроме того, можно посчитать среднее между блоком с предыдущего кадра и блоком со следующего, которое может лучше соответствовать данному.
48