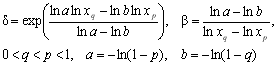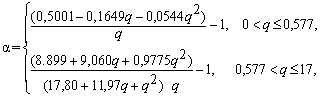5. Аппроксимация закона распределения экспериментальных данных
5.1. Задачи аппроксимации
Конкретное содержание обработки одномерных ЭД зависит от поставленных целей исследования. В простейшем случае достаточно определить первый момент распределения, например, среднее время обработки запросов к распределенной базе данных. В других случаях требуется установить вероятностно-временные характеристики распределения, например, оценить вероятность своевременной обработки запросов или вероятность безотказной работы системы в течение заданного периода времени. Для нахождения таких значений требуется знание закона распределения как наиболее полной характеристики соответствующей случайной величины.
В классической математической статистике предполагается известным вид закона распределения и производится оценка значений его параметров по результатам наблюдений. Но обычно заранее вид закона распределения неизвестен, а теоретические предположения не позволяют его однозначно установить. Обработка ЭД также не позволит точно вычислить истинный закон распределения показателя. В таком случае следует говорить только об аппроксимации (приближенном описании) реального закона некоторым другим, который не противоречит ЭД и в каком-то смысле похож на этот неизвестный истинный закон.
В соответствии с этими положениями постановка задачи аппроксимации закона распределения ЭД формулируется следующим образом.
Имеется выборка наблюдений (x1, x2, …, xn) за случайной величиной Х. Объем выборки п фиксирован.
Необходимо подобрать закон распределения (вид и параметры), который бы в статистическом смысле соответствовал имеющимся наблюдениям.
Ограничения: выборка представительная, ее объем достаточен для оценки параметров и проверки согласованности выбранного закона распределения и ЭД; плотность распределения унимодальная.
Наличие в функции плотности распределения нескольких мод может быть следствием различных причин, например существованием различных по длине маршрутов прохождения запросов в системе обработки. Выборку с несколькими модами разделяют на составные части так, чтобы каждая из них имела одну моду. В последнем случае функция распределения исходной выборки представляет собой взвешенную сумму соответствующих функций отдельных выборок:
![]() ,
,
где s – количество выборок, выбранное исходя из требований унимодальности распределения; pi – вероятность принадлежности элемента выборки к выборке i; Fi(x) – функция распределения выборки i.
Решение поставленной задачи аппроксимации осуществляется на основе применения "типовых" распределений, специальных рядов или семейств универсальных распределений.
5.2. Аппроксимация на основе типовых распределений
Задача аппроксимации на основе типовых распределений решается итерационно и включает выполнение трех основных шагов:
предварительного выбора вида закона распределения;
определения оценок параметров закона распределения;
оценки согласованности закона распределения и ЭД.
Если заданный уровень согласованности достигнут, то задача считается решенной, а если нет, то шаги повторяются снова, начиная с первого шага, на котором выбирается другой вид закона, или начиная со второго – путем некоторого уточнения параметров распределения.
Выбор вида закона распределения осуществляется посредством анализа гистограммы распределения, оценок коэффициентов асимметрии и эксцесса. По степени "похожести" гистограммы и графиков плотностей распределения типовых законов или по "близости" значений оценок коэффициентов и диапазонов их теоретических значений выбираются распределения – кандидаты для последующей оценки параметров. На рис. 4.1 – 4.4 представлены графики типовых функций плотностей распределения, часто применяемых в задачах аппроксимации ЭД, а в табл. 4.1 приведены функции плотности и теоретические параметры этих распределений.
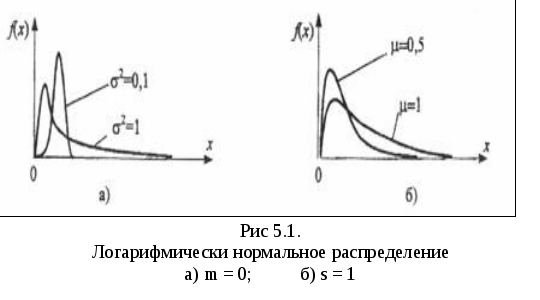
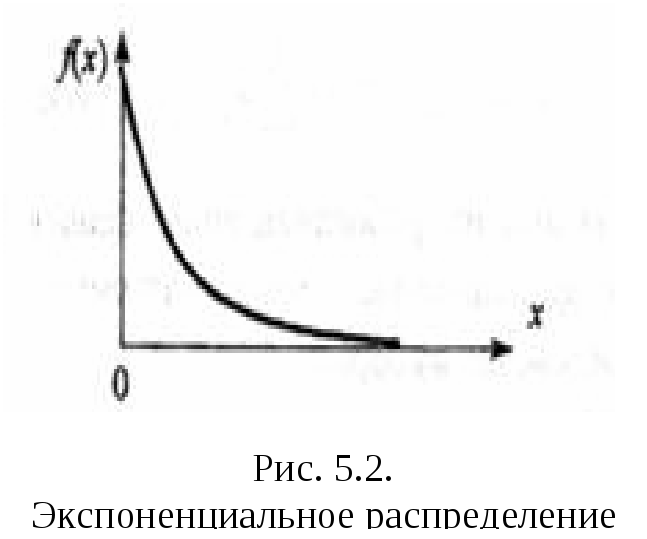
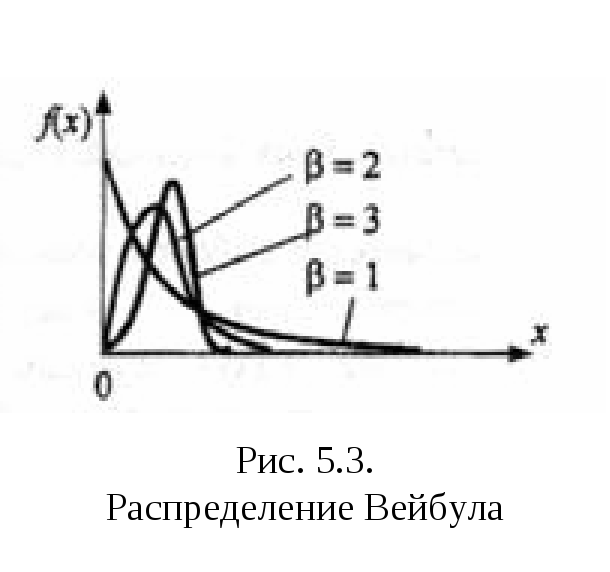
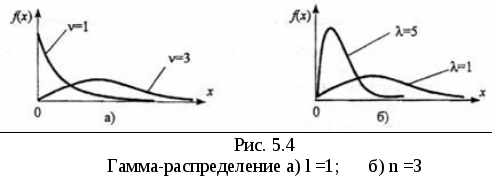
Следует отметить, что гамма-распределение соответствует распределению Эрланга, если l – целое, и экспоненциальному распределению при n = 1.
После выбора подходящего вида распределения производится оценка его параметров, используя методы максимального правдоподобия, моментов или квантилей. В целях упрощения решения задачи в табл. 4.2 приведены расчетные формулы для вычисления оценок параметров типовых распределений.
Применительно к выбранному закону распределения производится проверка гипотезы о том, что имеющаяся выборка может принадлежать этому закону. Если гипотеза не отвергается, то можно считать, что задача аппроксимации решена. Если гипотеза отвергается, то возможны следующие действия: изменения значений оценок параметров распределения; выбор другого вида закона распределения; продолжение наблюдений и пополнение выборки. Конечно, такой подход не гарантирует нахождение "истинного" или даже подбора подходящего закона распределения
Преимущество применения типовых законов распределения состоит в их хорошей изученности и возможности получения состоятельных, несмещенных и относительно высоко эффективных оценок параметров. Однако рассмотренные выше типовые законы распределения не обладают необходимым разнообразием форм, поэтому их применение не дает необходимой общности представления случайных величин, которые встречаются при исследовании систем.
Таблица 5.1
|
Тип функции плотности распределения |
Математическое ожидание m1, дисперсия 2, эксцесс |
|
Нормальное
|
mx=m 2=2 |
|
Логарифмическое нормальное
|
|
|
Экспоненциальное
|
|
|
Вейбулла
d>0, b>0 |
|
|
Гамма
n>0, >0 |
|
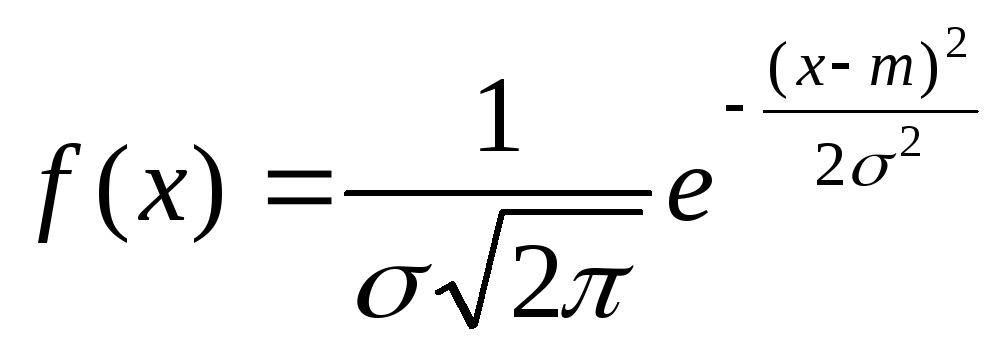
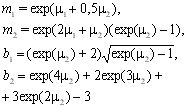
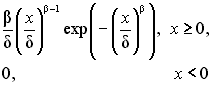
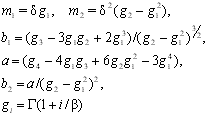
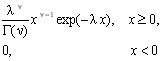
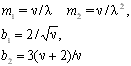
Таблица 5.2
|
Тип распределения |
Оценка параметров распределения по выборочным данным |
|
нормальное |
|
|
Логарифмическое нормальное |
|
|
Экспоненциальное |
|
|
Вейбулла |
|
|
Гамма |
где q=ln(m1/)
|