

Лабораторная работа №6
.pdfЛабораторная работа №6
Тема: Моделирование экспертной системы поддержки принятия решения в среде СУБД Cache с помощью деревьев решений.
Цель работы: Получить навыки формализации знаний и разработать базу знаний экспертной системы из профессиональной предметной области.
Теоретические сведения
Со временем количество информации, которую необходимо обработать для принятия нужного решения, стремительно увеличивается. Принятие решения —
это процесс рационального или иррационального выбора альтернатив, имеющий целью достижение осознаваемого результата. Рост объемов неструктурированных данных и оперативность в принятии решений выдвигают специальные требования к руководителям и аналитикам. Объемы этих данных настолько велики, что возможностей экспертов уже не хватает. В связи с этим, наблюдается стремительный рост интереса компаний к информационным продуктам,
позволяющим работать с большими объемами информации, накопленными в учетных системах и хранилищах данных, и извлекать из них полезные сведения.
Система поддержки принятия решений (Decision Support Systems — DSS) -
является классом компьютеризированных информационных систем, которые поддерживают деятельность по принятию решений.
DSS-система — это интерактивная компьютерная система, предназначенная для помощи лицу, принимающему решения, в использовании связей, данных,
документов, знаний и моделей для идентификации и решения проблем и формирования решений. Другими словами, СППР - это скоординированный набор данных, систем, инструментов и технологий, программного и аппаратного обеспечения, с помощью которого предприятие собирает и обрабатывает
1

информацию о бизнесе и окружающей среде с целью обоснования
управленческих действий.
СППР, основанные на знаниях
Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности промышленные предприятия, корпорации, ведомственные структуры, органы государственной власти и управления накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения.
В последние годы в мире оформился ряд новых концепций хранения и анализа корпоративных данных:
1.Хранилища данных, или Склады данных (Data Warehouse);
2.Оперативная аналитическая обработка (On-Line Analytical Processing,
OLAP);
3.Интеллектуальный анализ данных - ИАД (Data Mining).
Технологии Data Warehouse тесно связаны с технологиями OLAP и методами интеллектуальной обработки - Data Mining. Поэтому наилучшим вариантом является комплексный подход к их внедрению.
В той или иной степени СППР присутствуют в любой информационной системе. Поэтому, осознанно или нет, к задаче создания системы СППР организации приступают сразу после приобретения вычислительной техники и установки программного обеспечения. По мере развития бизнеса, упорядочения структуры организации и налаживания межкорпоративных связей, проблема разработки и внедрения СППР становится особенно актуальной. Одним из
2

подходов к созданию таких систем стало использование хранилищ данных. Для того чтобы существующие хранилища данных способствовали принятию управленческих решений, информация должна быть представлена аналитику в нужной форме, то есть он должен иметь развитые инструменты доступа к данным хранилища и их обработки. Очень часто информационно-аналитические системы,
создаваемые в расчете на непосредственное использование лицами,
принимающими решения, оказываются чрезвычайно просты в применении, но жестко ограничены в функциональности. Такие статические системы СППР
называются Информационными системами руководителя (ИСР), или Executive Information Systems (EIS). Динамические СППР, напротив, ориентированы на обработку нерегламентированных запросов аналитиков к данным. Работа аналитиков с этими системами заключается в интерактивной последовательности формирования запросов и изучения их результатов.
Поддержка принятия управленческих решений на основе накопленных данных может выполняться в трех базовых сферах:
1.Сфера детализированных данных. Это область действия большинства систем, нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами.
Информационно-поисковые системы, обеспечивающие интерфейс конечного пользователя в задачах поиска детализированной информации,
могут использоваться в качестве надстроек, как над отдельными базами данных транзакционных систем, так и над общим хранилищем данных.
2.Сфера агрегированных показателей. Комплексный взгляд на собранную в хранилище данных информацию, ее обобщение и агрегация,
гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP).
3.Сфера закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining), главными
3

задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Хранилища данных
При решении практических задач, в частности, задачи прогнозирования,
приходится сталкиваться с проблемой подготовки данных. Если рассуждать на уровне обычной логики. В августе, сентябре, октябре было продано 10000 единиц какого-либо товара. О чѐм говорят эти данные? Это хороший или плохой результат? Однозначно на этот вопрос ответить невозможно. Во-первых, нужно учитывать сезонность, во-вторых, состояние рынка, в-третьих, действия конкурентов и так можно продолжать еще долго: цена, реклама, изменение законодательства... Если человек не может дать ответ на, казалось бы, достаточно простой вопрос, что стоит ждать от компьютера. Эксперт всегда имеет много,
пусть и не формализованной, дополнительной информации. Это называется
опытом работы. В случае применения какого-либо математического метода у нас этих данных нет. Не нужно забывать ещѐ о различного рода аномальных выбросах и провалах. Эксперт, зная, что происходило в это время, будет или не будет принимать эти сведения в расчет при прогнозировании объемов продаж.
Фундаментальная проблема заключается в том, что информации об истории продаж – то, на основе чего чаще всего предлагается прогнозировать, совершенно недостаточно для сколько-нибудь качественного прогноза. Конечно, можно прогнозировать и имея только эти данные, но это больше напоминает гадание на кофейной гуще. Сведения об объемах продаж, конечно, нужны, но они дают максимум 30% от необходимой информации. Фактически они описывают только то, что произошло внутри организации, и то не в полном объеме. А то, что произошло в это время на рынке, практически игнорируется. В то время как влияние внешних факторов очень велико, в некоторых случаях и решающее.
4

Для того чтобы получить качественный прогноз, нужно собрать максимум информации об исследуемом процессе, описывающей его с разных сторон. Рис. 1.
Проблема заключается в том, что обычно в системах оперативного учета большей части этой информации просто нет, а та, что есть, искаженная и/или неполная. Лучшим вариантом в этом случае будет создание хранилища данных,
куда бы с определенной заданной периодичностью поступала вся необходимая информация, предварительно систематизированная и отфильтрованная.
Хранилище данных - это предметно-ориентированное, привязанное ко времени и неизменяемое собрание данных для поддержки процесса принятия управляющих решений.
Рис. 1. Информация об исследуемом процессе в хранилище данных.
OLAP
Предположим теперь, что в общем случае имеется корпоративное ХД. Каким образом следует организовать доступ к информации для анализа? Термин OLAP
неразрывно связан с термином "хранилище данных" (Data Warehouse). В основе концепции OLAP лежит принцип многомерного представления данных. OLAP
предоставляет удобные быстродействующие средства доступа, просмотра и анализа деловой информации. Пользователь получает естественную, интуитивно понятную модель данных, организуя их в виде многомерных кубов (Cubes).
5

Осями многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для продаж это могут быть товар,
регион, тип покупателя. В качестве одного из измерений используется время. На пересечениях осей - измерений (Dimensions) - находятся данные, количественно характеризующие процесс - меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т. п.
Пользователь, анализирующий информацию, может "разрезать" куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные
(по неделям) сведения и осуществлять прочие манипуляции, которые ему придут в голову в процессе анализа.
Рис. 2. Пример куба.
Для визуализации данных, хранящихся в кубе, применяются, как правило,
привычные двумерные, т. е. табличные, представления, имеющие сложные иерархические заголовки строк и столбцов. Двумерное представление куба можно получить, "разрезав" его поперек одной или нескольких осей (измерений): мы фиксируем значения всех измерений, кроме двух, - и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов)
представлено одно измерение, в вертикальной (заголовки строк) - другое, а в ячейках таблицы - значения мер. При этом набор мер фактически рассматривается как одно из измерений - мы либо выбираем для показа одну меру (и тогда можем разместить в заголовках строк и столбцов два измерения), либо показываем несколько мер (и тогда одну из осей таблицы займут названия мер, а другую -
6

значения единственного "неразрезанного" измерения). Схема работы. Общую схему работы OLAP системы можно представить следующим образом:
Рис. 3. Общуая схема работы настольной OLAP системы.
Алгоритм работы следующий:
1.Получение данных в виде плоской таблицы или результата выполнения
SQL запроса.
2.Кэширование данных и преобразование их к многомерному кубу.
3.Отображение построенного куба при помощи кросс - таблицы или диаграммы и т.п. В общем случае, к одному кубу может быть подключено произвольное количество отображений.
Интеллектуальный анализ данных
Интеллектуальный анализ данных (ИАД) определяют как метод поддержки принятия решений, основанный на анализе зависимостей между данными. В
рамках такой общей формулировки обычный анализ отчетов, построенных по базе данных, также может рассматриваться как разновидность ИАД. В системах ИАД применяется чрезвычайно широкий спектр математических, логических и статистических методов: от анализа деревьев решений до нейронных сетей.
Оперативная аналитическая обработка и интеллектуальный анализ данных - две составные части процесса поддержки принятия решений. Но сегодня большинство систем OLAP заостряет внимание только на обеспечении доступа к
7

многомерным данным, а большинство средств ИАД, работающих в сфере закономерностей, имеют дело с одномерными перспективами данных. Эти два вида анализа должны быть тесно объединены, то есть системы OLAP должны фокусироваться не только на доступе, но и на поиске закономерностей. В общем случае процесс ИАД состоит из трѐх стадий:
1.Выявление закономерностей (свободный поиск);
2.Использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование);
3.Анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
Иногда в явном виде выделяют промежуточную стадию проверки достоверности найденных закономерностей между их нахождением и использованием (стадия валидации).
Все методы ИАД подразделяются на две большие группы по принципу работы
сисходными обучающими данными.
1.В первом случае исходные данные могут храниться в явном детализированном виде и непосредственно использоваться для прогностического моделирования и/или анализа исключений; это так называемые методы рассуждений на основе анализа прецедентов. Главной проблемой этой группы методов является затрудненность их использования на больших объемах данных, хотя именно при анализе больших хранилищ данных методы ИАД приносят наибольшую пользу.
2.Во втором случае информация вначале извлекается из первичных данных и преобразуется в некоторые формальные конструкции (их вид зависит от конкретного метода). Согласно предыдущей классификации, этот этап выполняется на стадии свободного поиска, которая у методов первой группы в принципе отсутствует. Таким образом, для прогностического
8

моделирования и анализа исключений используются результаты этой стадии, которые гораздо более компактны, чем сами массивы исходных данных. При этом полученные конструкции могут быть либо
"прозрачными" (интерпретируемыми), либо "черными ящиками" (нетрактуемыми).
Деревья решений как метод автоматического анализа данных
Стремительное развитие информационных технологий, в частности, прогресс в методах сбора, хранения и обработки данных позволил многим организациям собирать огромные массивы данных, которые необходимо анализировать.
Объемы этих данных настолько велики, что возможностей экспертов уже не хватает, что породило спрос на методы автоматического исследования (анализа)
данных, который с каждым годом постоянно увеличивается. Деревья решений –
один из методов автоматического анализа данных. Первые идеи создания деревьев решений восходят к работам Ховленда (Hoveland) и Ханта (Hunt) конца
50-х годов XX века. Однако, основополагающей работой, давшей импульс для развития этого направления, явилась книга Ханта (Hunt, E.B.), Мэрина (Marin J.) и
Стоуна (Stone, P.J) "Experiments in Induction", вышедшая в 1966г.
Дерево решений, Decision Trees, дерево классификаций, Classification Tree – это классификатор, полученный из обучающего множества, содержащего объекты и их характеристики, на основе обучения. Дерево состоит из листьев, указывающих на класс, и узлов. Оно может использоваться для классификации объектов, не вошедших в обучающее множество. Поиск начинается с корня, пока не будет обнаружен класс, соответствующий объекту. Рис. 4.
9
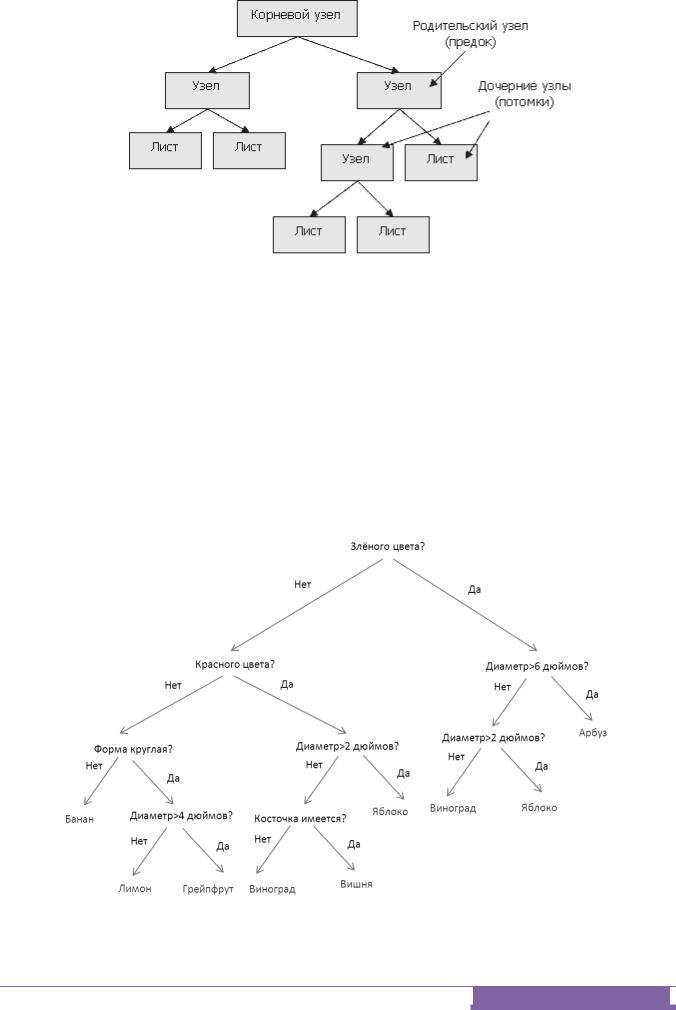
Рис. 4. Схема дерева решения.
Деревья решений – это способ представления правил в иерархической,
последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. Под правилом понимается логическая конструкция,
представленная в виде "если ... то ...". Узел - внутренний узел дерева, узел проверки. Лист - конечный узел дерева, узел решения. Листья деревьев соответствуют значениям зависимой переменной, т.е. классам.
Рис. 5. Дерево решений для классификации фруктов.
10