

Алгоритм на псевдокоде
Кодирование кодом «Стопка книг»
Обозначим
code – массив кодовых слов для позиции «стопки»
s_in – строка для кодирования
s_out – результат кодирования
S – строка, содержащая исходный алфавит
l:=<длина s_in>
DO (i=1,…l)
T:=<номер символа s_in[i] в строке S>
s_out:=s_out+code[t]
stmp:=S[t]
delete(S,t,1) (преобразование
insert(stmp,S,1) строки S)
OD
Интервальный код
Интервальный код был предложен П. Элиасом в 1987 году. В нем используется окно длины W, т.е. при кодировании символа xi исходной последовательности учитываются W предыдущих символов:
![]()
При кодировании символа xi определяется расстояние (интервал) до его предыдущей встречи в окне длины W. Обозначим это расстояние (xi). Если символ есть xi в окне, то значение (xi) равно номеру позиции символа в окне. Позиции в окне нумеруются справа налево. Если символа xi нет в окне, то (xi) присваивается значение W+1, а xi кодируется словом, состоящим из (xi) и самого символа xi. После кодирования очередного символа окно сдвигается вправо на один символ.
Пример.
Рассмотрим
описание кода для исходного алфавита
A={a1,a2,a3,a4},
пусть длина окна W=3.
Возьмем некоторый префиксный код
![]() для записи числа(Xi):
для записи числа(Xi):
|
(хi) |
1 |
2 |
3 |
4 |
|
σi |
0 |
10 |
110 |
111 |
Пусть кодируется последовательность а1а1а2а3а2а2… (см. рис. 12)
Сначала символа а1 нет в окне, поэтому на выход кодера передается 111 и восьмибитовый ASCII-код символа а1 Затем окно сдвигается на одну позицию вправо.
При кодировании следующего символа а1 на выход кодера передается 0, так как теперь символ а1 находится в первой позиции окна. Далее окно снова сдвигается на одну позицию вправо.
Следующий символ а2 кодируется комбинацией 111 и восьмибитовым ASCII-кодом символа а2, так как символа а2 нет в окне. Окно снова сдвигается на одну позицию вправо.
Следующий символ а3 кодируется комбинацией 111 и восьмибитовым ASCII-кодом символа а3 , так как символа а3 нет в окне. Окно снова сдвигается на одну позицию вправо.
Следующий кодируемый символ а2 находим во второй позиции окна и поэтому кодируем комбинацией 10. Окно снова сдвигается на одну позицию вправо.
И последний символ а2 находим во первой позиции окна и поэтому кодируем комбинацией 0. Таким образом, закодированное сообщение имеет следующий вид:
111
а1
0 111 а2
111 а3
10 0
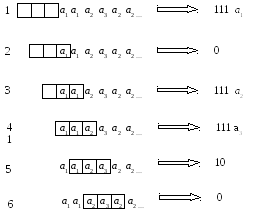
Рисунок 12 Кодирование интервальным кодом
П ри
декодировании используется такое же
окно, как и при кодировании. По принятому
кодовому слову можно определить, в какой
позиции окна находится данный символ.
Если поступает код 111, то декодер считывает
следующий за ним символ. Каждая
декодированная буква полностью включается
в окно.
ри
декодировании используется такое же
окно, как и при кодировании. По принятому
кодовому слову можно определить, в какой
позиции окна находится данный символ.
Если поступает код 111, то декодер считывает
следующий за ним символ. Каждая
декодированная буква полностью включается
в окно.
Сжатие данных интервальным кодом достигается за счет малых расстояний между встречами более вероятных букв, что позволяет получить более короткие кодовые слова.