

Коды Шеннона - Фано.
При передаче сообщений, закодированных двоичным равномерным кодом, не учитывают статическую структуру передаваемых сообщений. Все кодовые комбинации при этом имеют одинаковую длину.
Из теоремы Шеннона о кодировании сообщений в каналах без шумов следует, что если передача дискретных сообщений ведется при отсутствии помех, то всегда можно найти такой метод кодирования, при котором среднее число двоичных символов на одно сообщение будет сколь угодно близким к энтропии источника этих сообщений, но никогда не может быть меньше ее.
Учет статистики сообщений на основании теоремы Шеннона позволяет строить код, в котором часто встречающимся сообщением присваиваются более короткие кодовые комбинации, а редко встречающимся – более длинные.
Методы построения таких кодов впервые предложили одновременно в 1948-49 годах Р. Фано и К. Шеннон, поэтому код назвали кодом Шеннона-Фано.
Код строится по рассмотренным ранее правилам аналогично двоичному коду. При этом сообщения вписываются в таблицу в порядке убывания вероятности их появления. Деление на группы производится так, чтобы суммы вероятности в каждой из групп были бы по возможности одинаковыми.
Основной принцип, положенный в основу кодирования по методу Шеннона-Фано заключается в том, что при выборе каждой цифры кодового слова стремятся, чтобы содержащееся в ней количество информации было наибольшее. Данный код является не равномерным.
Пример:![]()

Записываем в таблице
сообщение в порядке убывания. 1-ой группе
присваиваем значение «0», а 2-ой – «1».
Среднее количество символов на одно
сообщение для рассматриваемого набора
сообщений составляет:![]()
Энтропия данного
кода:![]()
Если использовать простой двоичный код, то необходимое число символов n=3.
Кодирование Хаффмана
Кодирование Хаффмана является простым алгоритмом для построения кодов переменной длины, имеющих минимальную среднюю длину. Этот весьма популярный алгоритм служит основой многих компьютерных программ сжатия текстовой и графической информации.
Алгоритм начинается составлением списка символов алфавита в порядке убывания их вероятностей. Затем от корня строится дерево, листьями которого служат эти символы. Это делается по шагам, причем на каждом шаге выбираются два символа с наименьшими вероятностями, добавляются наверх частичного дерева, удаляются из списка и заменяются вспомогательным символом, представляющим эти два символа. Вспомогательному символу приписывается вероятность, равная сумме вероятностей, выбранных на этом шаге символов. Когда список сокращается до одного вспомогательного символа, представляющего весь алфавит, дерево объявляется построенным. Завершается алгоритм спуском по дереву и построением кодов всех символов.
Лучше всего проиллюстрировать этот алгоритм на простом примере. Имеется пять символов с вероятностями, заданными на рис. 1.3а.
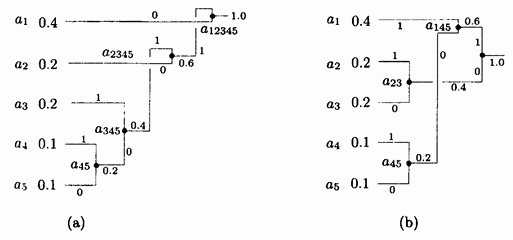
Рис. 1.3. Коды Хаффмана.
Символы объединяются в пары в следующем порядке:
1.![]() объединяется
с
объединяется
с ![]() ,
и оба заменяются комбинированным
символом
,
и оба заменяются комбинированным
символом ![]() с
вероятностью 0.2;
с
вероятностью 0.2;
2. Осталось четыре
символа, ![]() с
вероятностью 0.4, а также
с
вероятностью 0.4, а также ![]() и
и ![]() с
вероятностями по 0.2. Произвольно
выбираем
с
вероятностями по 0.2. Произвольно
выбираем ![]() и
и ![]() ,
объединяем их и заменяем вспомогательным
символом
,
объединяем их и заменяем вспомогательным
символом ![]() с
вероятностью 0.4;
с
вероятностью 0.4;
3. Теперь имеется
три символа ![]() и
и ![]() с
вероятностями 0.4, 0.2 и 0.4, соответственно.
Выбираем и объединяем символы
с
вероятностями 0.4, 0.2 и 0.4, соответственно.
Выбираем и объединяем символы ![]() и
и ![]() во
вспомогательный символ
во
вспомогательный символ ![]() с
вероятностью 0.6;
с
вероятностью 0.6;
4. Наконец, объединяем
два оставшихся символа ![]() и
и ![]() и
заменяем на
и
заменяем на ![]() с
вероятностью 1.
с
вероятностью 1.
Дерево построено. Оно изображено на рис. 1.3а, «лежа на боку», с корнем справа и пятью листьями слева. Для назначения кодов мы произвольно приписываем бит 1 верхней ветке и бит 0 нижней ветке дерева для каждой пары. В результате получаем следующие коды: 0, 10, 111, 1101 и 1100. Распределение битов по краям - произвольное.
Средняя длина этого
кода равна ![]() бит/символ.
Очень важно то, что кодов Хаффмана бывает
много. Некоторые шаги алгоритма выбирались
произвольным образом, поскольку было
больше символов с минимальной вероятностью.
На рис. 1.3b показано, как можно объединить
символы по-другому и получить иной код
Хаффмана (11, 01, 00, 101 и 100). Средняя длина
равна
бит/символ.
Очень важно то, что кодов Хаффмана бывает
много. Некоторые шаги алгоритма выбирались
произвольным образом, поскольку было
больше символов с минимальной вероятностью.
На рис. 1.3b показано, как можно объединить
символы по-другому и получить иной код
Хаффмана (11, 01, 00, 101 и 100). Средняя длина
равна ![]() бит/символ
как и у предыдущего кода.
бит/символ
как и у предыдущего кода.
Пример: Дано 8 символов А, В, С, D, Е, F, G и H с вероятностями 1/30, 1/30, 1/30, 2/30, 3/30, 5/30, 5/30 и 12/30. На рис. 1.4а,b,с изображены три дерева кодов Хаффмана высоты 5 и 6 для этого алфавита.
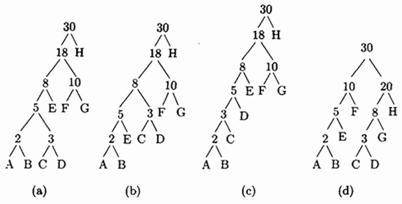
Рис. 1.4. Три дерева Хаффмана для восьми символов.
Средняя длина этих кодов (в битах на символ) равна
![]() ,
,
![]() ,
,
![]() .
.