

2. Операции над событиями
При разработке аппарата и методики исследования случайных событий в теории вероятностей очень важным является понятие суммы и произведения событий.
Суммой, или объединением, нескольких событий называется событие, состоящее в наступлении хотя бы одного из этих событий.
Сумма
![]() событий
событий
![]() обозначается так:
обозначается так:
![]()
Например, если событие А есть попадание
в цель при первом выстреле, событие В—
при втором, то событие
![]() есть попадание в цель вообще, безразлично,
при каком выстреле — первом, втором или
при обоих вместе.
есть попадание в цель вообще, безразлично,
при каком выстреле — первом, втором или
при обоих вместе.
Произведением, или пересечением, нескольких событий называется событие, состоящее в совместном появлении всех этих событий.
Произведение
![]() событий
событий
![]() обозначается
обозначается
![]()
.
Например, если событие А есть попадание
в цель при первом выстреле, событие В —
при втором, то событие
![]() состоит в том, что в цель попали при
обоих выстрелах.
состоит в том, что в цель попали при
обоих выстрелах.
Понятия суммы и произведения событий
имеют наглядную геометрическую
интерпретацию. Пусть событие А состоит
в попадании точки в область А , событие
В— в попадании в область В, тогда событие
![]() состоит в попадании точки в область,
заштрихованную на рис. 1, и событие
состоит в попадании точки в область,
заштрихованную на рис. 1, и событие
![]() — в попадании точки в область,
заштрихованную на рис. 2.
— в попадании точки в область,
заштрихованную на рис. 2.

Статистическое определение вероятности
Формулу (1.1) используют для непосредственного вычисления вероятностей событий только тогда, когда опыт сводится к схеме случаев. На практике часто классическое определение вероятности неприменимо по двум причинам: во-первых, классическое определение вероятности предполагает, что общее число случаев должно быть конечно. На самом же деле оно зачастую не ограничено. Во-вторых, часто невозможно представить исходы опыта в виде равновозможных и несовместных событий.[/indent]
Частота появления событий при многократно повторяющихся Опытах имеет тенденцию стабилизироваться около какой-то постоянной величины. Таким образом, с рассматриваемым событием можно связать некоторую постоянную величину, около которой группируются частоты и которая является характеристикой объективной связи между комплексом условий, при которых проводятся опыты, и событием.
Вероятностью случайного события называется число, около которого группируются частоты этого события по мере увеличения числа испытаний.
Это определение вероятности называется статистическим.
Преимущество статистического способа определения вероятности состоит в том, что он опирается на реальный эксперимент. Однако его существенный недостаток заключается в том, что для определения вероятности необходимо выполнить большое число опытов, которые очень часто связаны с материальными затратами. Статистическое определение вероятности события хотя и достаточно полно раскрывает содержание этого понятия, но не дает возможности фактического вычисления вероятности.
Решение задачи:
При испытании партии приборов относительная частота годных приборов оказалась равной 0,9. Найти число годных приборов, если всего было проверено 200 приборов.
Дано: W(A)= 0,9; n = 200, m – ?
Используемые формулы:
![]() ,
,
m = W(A) n
Решение: m = 0,9 x 200 = 180
Ответ: 180 годных приборов
Решение задачи № 5 аналогичным способом
В пакете 25 разных конфет. Какова вероятность того, что выбранные на удачу три конфеты будут именно те, которые Вы хотели?
Решение.
Используемые формулы
 ,
,
m - число исходов испытания , благоприятствующих наступлению события А,
n - общее число всех равновозможных несовместных исходов
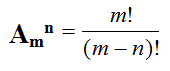
n – число элементов, входящих в каждую комбинацию;
m – число всех имеющихся элементов

n – число элементов, входящих в каждую перестановку,
(n - натуральное число)
1. Найдем n - общее число всех равновозможных несовместных исходов при вытягивании трех конфет. Их будет столько, сколько можно составить различных размещений из 25 элементов по три:
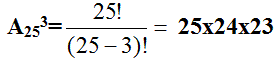
2. Найдем m. Число случаев, благоприятствующих тому, что будут выбраны нужные три конфеты, столько, сколько можно составить перестановок из трех элементов
Р3= 3!= 1 х 2 х 3 = 6.
3. Искомая вероятность равна
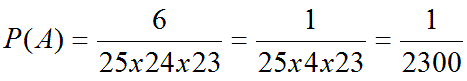
Ответ: вероятность 1/2300
Аксиоматическое определение вероятности
Пусть Ω - множество всех возможных исходов некоторого опыта (эксперимента). Согласно аксиоматическому определению вероятности, каждому события А (А подмножество множества Ω) ставится в соответствии некоторое числу р(А), называемое вероятностью события А, причем так, что выполняются следующие три условия (аксиомы вероятностей):
р(А)≥0
p(Ω)=1
аксиома сложения
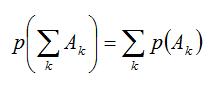
где Аi·Aj=Ω (i≠j), т.е. вероятность суммы попарно-несовместных событий равна сумме вероятностей этих событий.
Из этих трех аксиом, вытекают свойства вероятности:
р(Ø)=0, т.е. вероятность невозможного события равна нулю.
р(А)+р(Ā)=1
0≤р(А)≤1 для любого события А
р(А)≤р(В), если А подмножество В
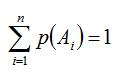 , если
, если
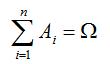
и Аi·Aj=Ø, i≠j
Если множество Ω состоит из n равновозможных элементарных событий, то вероятность события А определяется по формуле классического определения вероятности:
p(A)=m/n
где m - число случаев (элементов), принадлежащих множеству В (число блогаприятствующих событию А исходов), n - число элементов множества Ω (число всех исходов опыта).
Таким образом, мы дали определение вероятности: классическое определение вероятности, геометрическое определение вероятности и аксиоматическое определение вероятности
Пример: На отрезке [0, 1] наугад (случайно) поставлена точка. Измеряется расстояние точки от левого конца отрезка. В этом опыте пространство элементарных событий W = [0, 1] - множество действительных чисел на единичном отрезке.
В более точных, формальных терминах элементарные события и пространство элементарных событий описывают следующим образом.
Пространством элементарных событий называют произвольное множество W, W ={w}. Элементы w этого множества W называют элементарными событиями.
Понятия элементарное событие, событие, пространство элементарных событий, являются первоначальными понятиями теории вероятностей. Невозможно привести более конкретное описание пространства элементарных событий. Для описания каждой реальной модели выбирается соответствующее пространство W.
Событие W называется достоверным событием.
Достоверное событие не может не произойти в результате эксперимента, оно происходит всегда.
Пример 4. Бросаем один раз игральную кость. Достоверное событие состоит в том, что выпало число очков, не меньше единицы и не больше шести, т.е. W = {w 1, w 2, w 3, w 4, w 5, w 6}, где w i- выпадение i очков, - достоверное событие.
Невозможным событием называется пустое множество .
Невозможное событие не может произойти в результате эксперимента, оно не происходит никогда.
Случайное событие может произойти или не произойти в результате эксперимента, оно происходит иногда.
Формула полной вероятности. Формулы Байеса
Пусть A - произвольное событие, а события
B1, B2, …, Bn - попарно несовместны и образуют
полную группу событий, т.е.
![]() . Тогда имеет место следующая формула
для вероятности события A - формула
полной вероятности -
. Тогда имеет место следующая формула
для вероятности события A - формула
полной вероятности -
![]() ,
где P(Bk)>0,
k=1, 2, …, n, A
B1+ B2 + …+
Bn.
,
где P(Bk)>0,
k=1, 2, …, n, A
B1+ B2 + …+
Bn.
Если событие A произошло, то вероятность того, что имело место событие Bk
вычисляется по формуле Байеса: .
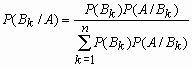
Теорема -формула Байеса. Пусть
![]() —
полная группа событий, и
—
полная группа событий, и
![]() —
некоторое событие, вероятность которого
положительна. Тогда условная вероятность
того, что имело место событие ,
—
некоторое событие, вероятность которого
положительна. Тогда условная вероятность
того, что имело место событие ,
![]() если в результате эксперимента наблюдалось
событие , А может быть вычислена по
формуле:
если в результате эксперимента наблюдалось
событие , А может быть вычислена по
формуле:
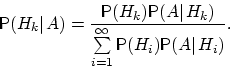
Доказательство. По определению условной вероятности,
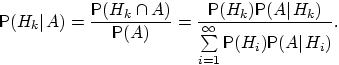
Вернёмся к примеру 21. Изделие выбирается
наудачу из всей произведённой продукции.
Рассмотрим три гипотезы:
![]() ,
,
![]() .
Вероятности этих событий даны:
.
Вероятности этих событий даны:
![]() ,
,
![]() ,
,
![]() .
.
Пусть
![]() .
Даны также условные вероятности
.
Даны также условные вероятности![]() ,
,
![]() ,
,
![]()
Убедились, что полученные нами в примере 21 вероятности совпадают с вероятностями, вычисленными по формуле полной вероятности и формуле Байеса.
Два стрелка подбрасывают монетку и
выбирают, кто из них стреляет по мишени
(одной пулей). Первый стрелок попадает
по мишени с вероятностью 1, второй стрелок
— с вероятностью 0,00001. Можно сделать
два предположения об эксперименте:
![]() и
и
![]() .
Априорные (a'priori — «до опыта») вероятности
этих гипотез одинаковы:
.
Априорные (a'priori — «до опыта») вероятности
этих гипотез одинаковы:
![]() .
.
Рассмотрим событие
![]() . Известно, что
. Известно, что
![]()
Поэтому вероятность пуле попасть в мишень
![]()
\Предположим, что событие А произошло.
Какова теперь апостериорная (a'posteriori —
«после опыта») вероятность каждой из
гипотез
![]() ?
Очевидно, что первая из этих гипотез
много вероятнее второй (а именно, в
?
Очевидно, что первая из этих гипотез
много вероятнее второй (а именно, в
![]() раз). Действительно,
раз). Действительно,
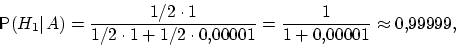

Последовательность испытаний (схема Бернулли)
Схема Бернулли состоит в следующем:
производится последовательность
испытаний, в каждом из которых вероятность
наступления определенного события А
одна и та же и равна р. Испытания
предполагаются независимыми (т.е.
считается, что вероятность появления
события А в каждом из испытаний не
зависит от того, появилось или не
появилось это событие в других испытаниях).
Наступление события А обычно называют
успехом, а ненаступление - неудачей.
Обозначим вероятность неудачи
q=1-P(A)=(1-p). Вероятность того, что в n
независимых испытаниях успех наступит
ровно m раз, выражается формулой Бернулли:
![]()
Вероятность Рn(m) при данном n сначала увеличивается при увеличении m от 0 до некоторого значения m0, а затем уменьшается при изменении m от m0 до n.
Поэтому m0, называют наивероятнейшим числом наступлений успеха в опытах. Это число m0, заключено между числами np-q и np+p (или, что то же самое, между числами n(p+1)-1 и n(p+1)) .Если число np-q - целое число, то наивероятнейших чисел два: np-q и np+p.
Важное замечание. Если np-q< 0, то наивероятнейшее число выигрышей равно нулю.
Пример. Игральная кость бросается 4 раза. При каждом броске нас интересует событие А={выпала шестерка}.
Решение: Здесь четыре испытания, и т.к. кубик симметричен, то
p=P(A)=1/6, q=1-p=5/6.
Вероятность того, что в 4 независимых испытаниях успех наступит ровно m раз (m < 4), выражается формулой Бернулли:
![]()
Посчитаем эти значения и запишем их в таблицу.

Самое вероятное число успехов в нашем случае m0=0.
Пример. Вероятность появления успеха равна 3/5. Найти наивероятнейшее число наступлений успеха, если число испытаний равно 19, 20.
Решение: при n =19 находим
![]()
Таким образом, максимальная вероятность
достигается для двух значений m0, равных
11 и 12. Эта вероятность равна
P19(11)=P19(12)=0,1797. При n=20 максимальная
вероятность достигается только для
одного значения m0, т.к.
![]() не является целым числом. Наивероятнейшее
число наступлений успеха m0 равно 12.
Вероятность его появления равна
P20(12)=0,1797. Совпадение чисел P20(12) и P19(12)
вызвано лишь сочетанием значений n и p
и не имеет общего характера.
не является целым числом. Наивероятнейшее
число наступлений успеха m0 равно 12.
Вероятность его появления равна
P20(12)=0,1797. Совпадение чисел P20(12) и P19(12)
вызвано лишь сочетанием значений n и p
и не имеет общего характера.
На практике в случае, когда n велико, а p мало (обычно p < 0,1; npq < 10) вместо формулы Бернулли применяют приближенную формулу Пуассона
![]()
Пример: Радиоаппаратура состоит из 1000 элементов. Вероятность отказа одного элемента в течение года равна 0,002. Какова вероятность отказа двух элементов за год? Какова вероятность отказа не менее двух элементов за год?
Решение: будем рассматривать работу каждого элемента как отдельное испытание. Обозначим А={отказ элемента за год}.
P(A)=p=0,002, l=np=1000*0,002=2<br>
По формуле Пуассона
![]()
Обозначим через P1000( > 2) вероятность отказа не менее двух элементов за год.
Переходя к противоположному событию, вычислим P1000( > 2) как:
![]()
Теорема Муавра — Лапласа - одна из предельных теорем теории вероятностей, установлена Лапласом в 1812. Если при каждом из n независимых испытаний вероятность появления некоторого случайного события Е равна р (0<р<1) и m - число испытаний, в которых Е фактически наступает, то вероятность неравенства близка (при больших n) к значению интеграла Лапласа.
При рассмотрении количества m появлений события A в n испытаниях Бернулли чаще всего нужно найти вероятность того, что m заключено между некоторыми значениями a и b. Так как при достаточно больших n промежуток [a,b] содержит большое число единиц, то непосредственное использование биномиального распределения
![]()
ребует громоздких вычислений, так как нужно суммировать большое число определённых по этой формуле вероятностей.
Поэтому используют асимптотическое
выражение для биномиального распределения
при условии, что p фиксированно, а
![]() .
Теорема Муавра-Лапласа утверждает, что
таким асимптотическим выражением для
биномиального распределения является
нормальная функция.
.
Теорема Муавра-Лапласа утверждает, что
таким асимптотическим выражением для
биномиального распределения является
нормальная функция.
\Если в схеме Бернулли n стремится к
бесконечности, p (0 < p < 1) постоянно,
величина
![]() ограничена равномерно по m и n
ограничена равномерно по m и n
![]() ,
то
,
то
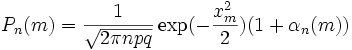 где
где
![]() ,
c > 0, c - постоянная.
,
c > 0, c - постоянная.
Приближённую формулу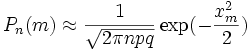
рекомендуется применять при n > 100 и npq > 20.
Для доказательства Теоремы будем
использовать формулу Стирлинга из
математического анализа:
![]()
где 0 < θs < 1 / 12s. При больших s величина
θ очень мала, и приближённая формула
Стирлинга, записанная в простом виде,
![]()
даёт малую относительную ошибку, быстро стремящуюся к нулю, когда
![]()
Нас будут интересовать значения m, не
очень отличающиеся от наивероятнейшего.
Тогда при фиксированном p условие
![]() будет так же означать, что
будет так же означать, что
![]() ,
,
![]()
Поэтому использование приближённой формулы Стирлинга для замены факториалов в биномиальном распределении допустимо, и мы получаем
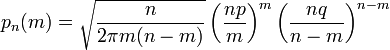
Также понадобится использование
отклонения относительной частоты от
наивероятнейшего значения
![]()
Переписываем полученное ранее биномиальное распределение с факториалами, заменёнными по приближённой формуле Стирлинга:
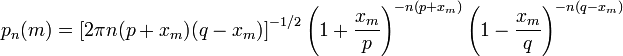
Предположим, что
xm < pq (7)
Взяв логарифм второго и третьего
множителей равенства (6), применим
разложение в ряд Тейлора:
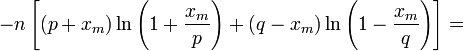
![]()
Располагаем члены этого разложения по степеням xm:
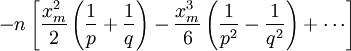
Предположим, что при
![]() ,
,
![]()
Это условие, как уже было указанно выше, означает, что рассматриваются значения m, не очень далёкие от наивероятнейшего. Очевидно, что (10) обеспечивает выполнение (7) и (3).
Теперь, пренебрегая вторым и последующими членами в разложении (6), получаем, что логарифм произведения второго и третьего членов
произведения в правой части (8) равен
![]()
Отбрасывая малые слагаемые в скобках
первого множителя (6), получаем:
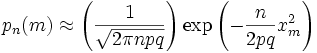
Отбрасывая малые слагаемые в скобках первого множителя (6), получаем:
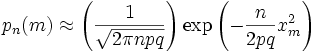
Обозначив
![]() ,
Переписываем (12) в виде:
,
Переписываем (12) в виде:
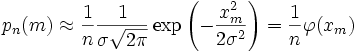
Где
![]() —
нормальная функция.
—
нормальная функция.
Поскольку в интервале [m,m + 1) имеется
только одно целое число m, то можно
сказать, что pn(m) есть вероятность
попадания m в интервал [m,m + 1). Из (5) следует,
что изменению m на 1 соответствует
изменение xm на
![]()
Поэтому вероятность попадания m в
интервал [m,m + 1) равна вероятности
попадания xm в промежуток [xm,xm + Δx)
![]()
Когда
![]() ,
,
![]() и равенство (16) показывает, что нормальная
функция
и равенство (16) показывает, что нормальная
функция
![]() является плотностью случайной переменной
xm
является плотностью случайной переменной
xm
Таким образом, если то для отклонения относительной частоты от наивероятнейшего значения справедлива ассимптотическая формула (16), в
которой
![]() — нормальная функция с xm = 0 и
— нормальная функция с xm = 0 и
![]() .
.
Таким образом теорема доказана.
Интегральная теорема Муавра—Лапласа
Пусть 0<p<1, тогда для схемы Бернулли
при n® Ґ для любых a и b справедлива
формула
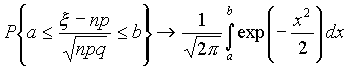
Это означает, что для вычисления вероятности того, что число успехов в n испытаниях Бернулли заключено между k1 и k2, можно использовать формулу
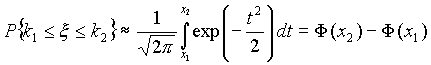 где
где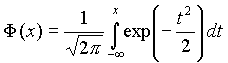 функция Лапласа, Точность этой приближенной
формулы растет с ростом n.,
функция Лапласа, Точность этой приближенной
формулы растет с ростом n.,
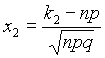 ,
,
ПУАССОНА ТЕОРЕМА
- 1) П. т.- предельная теорема теории
вероятностей, являющаяся частным случаем
больших чисел закона. П. т. обобщает
Бернулли теорему на случай независимых
испытаний, вероятность появления в
к-рых нек-рого события зависит от номера
испытаний (т. н. схема Пуассона).
Формулировка П. т. такова: если в
последовательности независимых испытаний
событие Анаступает с вероятностями pk,
зависящими от номера испытания k, k=1,2,
. . ., mn/n - частота Ав первых писпытаниях,
то при любом e>0 вероятность неравенства
![]() будет
стремиться к 1 при
будет
стремиться к 1 при
![]() . Теорема Бернулли следует из П. т. при
p1=. . .=р п. П. т. была установлена С.
Пуассоном [1]. Доказательство П. т. было
получено С. Пуассоном из варианта
Лапласа теоремы. Простое доказательство
П. т. было дано П. Л. Чебышевым (1846), к-рому
также принадлежит первая общая форма
закона больших чисел, включающая П. т.
в качестве частного случая.
. Теорема Бернулли следует из П. т. при
p1=. . .=р п. П. т. была установлена С.
Пуассоном [1]. Доказательство П. т. было
получено С. Пуассоном из варианта
Лапласа теоремы. Простое доказательство
П. т. было дано П. Л. Чебышевым (1846), к-рому
также принадлежит первая общая форма
закона больших чисел, включающая П. т.
в качестве частного случая.
2) П. т.- предельная теорема теории
вероятностей о сходимости биномиального
распределения к Пуассона распределению:если
Р п(m) - вероятность того, что в писпытаниях
Бернулли нек-рое событие Анаступает
ровно траз, причем и вероятность Ав
каждом испытании равна р, то при больших
значениях n и 1/р вероятность Р п
(т).близка к
![]() Величина l=np равна среднему значению
числа наступлений А в п испытаниях, а
последовательность значений
Величина l=np равна среднему значению
числа наступлений А в п испытаниях, а
последовательность значений
![]() образует распределение Пуассона. П. т.
была установлена С. Пуассоном [1] для
схемы испытаний, более общей, чем схема
Бернулли, когда вероятности наступления
события А могут меняться от испытания
к испытанию так, что
образует распределение Пуассона. П. т.
была установлена С. Пуассоном [1] для
схемы испытаний, более общей, чем схема
Бернулли, когда вероятности наступления
события А могут меняться от испытания
к испытанию так, что
![]() при
при![]() . Строгое доказательство П. т. в этом
случае основано на рассмотрении схемы
серий случайных величин такой, что в
n-й серии случайные величины независимы
и принимают значения 1 и 0 с вероятностями
и р n1- р п соответственно. Более удобна
форма П. т. в виде неравенства: если
. Строгое доказательство П. т. в этом
случае основано на рассмотрении схемы
серий случайных величин такой, что в
n-й серии случайные величины независимы
и принимают значения 1 и 0 с вероятностями
и р n1- р п соответственно. Более удобна
форма П. т. в виде неравенства: если
![]() ,
то при
,
то при
![]()
Это неравенство указывает ошибку при
замене Р n (т).величиной![]() . Если p1= . . . = р п=l/п, то d =l2/n. П. т. и теорема
Лапласа дают исчерпывающее представление
об асимптотич. поведении биномиального
распределения.
. Если p1= . . . = р п=l/п, то d =l2/n. П. т. и теорема
Лапласа дают исчерпывающее представление
об асимптотич. поведении биномиального
распределения.
Последующие обобщения П. т. создавались в двух основных направлениях. С одной стороны, появились уточнения П. т., основанные на асимптотич. разложениях, с другой - были установлены общие условия сходимости сумм независимых случайных величин к распределению Пуассона.
Случайные величины
Определения, примеры
Часто в результате испытания происходят события, заключающиеся в том, что некоторая величина принимает одно из своих возможных значений.
В таких случаях удобно вместо множества событий рассматривать одну переменную величину (называемую случайной величиной). Случайная величина обозначается через X, Y, Z, … и т.д.
Случайной называется величина, которая в результате испытания может принять то или иное возможное значение, неизвестное заранее, но обязательно одно.
Пример. В студенческой группе 25 человек. Пусть величина Х – число студентов, находящихся в аудитории перед началом занятий. Ее возможными значениями будут числа 0, 1, 2,…,25.
При каждом испытании (начало занятий) величина Х обязательно примет одно из своих возможных значений, т.е. наступит одно из событий Х = 0, Х = 1, …, Х = 25.
Пример. Измерение курса акции некоторого предприятия. Возможные события заключаются в том, что стоимость акции Y примет некоторое значение в пределах от 0 до ∞.
Пример. Однократное бросание игральной кости. Возможные события заключаются в том, что на верхней грани выпадает Z: 1, 2, 3, 4, 5, 6.
Пример. Подбрасывается монета n раз. Возможные результаты: герб выпал 0, 1, 2, …, n раз.
Различают дискретные и непрерывные случайные величины.
Если множество возможных значений случайной величины конечно или образуют бесконечную числовую последовательность, то такая случайная величина называется дискретной (примеры 3.1, 3.3, 3.4).
Случайная величина, множество значений которой заполняет сплошь некоторый числовой промежуток, называется непрерывной (пример 3.2). Заметим, что дискретные и непрерывные величины не исчерпывают все типы случайных величин.
Если случайная величина не относится ни к дискретным, ни к непрерывным случайным величинам, то ее называют смешанной.
Очевидно, что для полной характеристики дискретной случайной величины мало знать ее значения. Необходимо им поставить в соответствие вероятности.
Соответствие между всеми возможными значениями дискретной случайной величины и их вероятностями называется законом распределения данной случайной величины.
Простейшая формой задания закона распределения дискретной случайной величины является таблица, в которой перечислены возможные значения случайной величины (обычно в порядке возрастания) и соответствующие им вероятности:
|
Х |
х1 |
х2 |
… |
хn |
… |
|
|
Р |
р1 |
р2 |
… |
рn |
… |
|
акая таблица называется рядом распределения. Допустим, что число возможных значений случайной величины конечно: х1, х2, …, хn. При одном испытании случайная величина принимает одно и только одно постоянное значение. Поэтому события Х = хi (i = 1, 2, … , n) образуют полную группу попарно независимых событий. Следовательно, р1 + р2 + … + рn = 1.
Можно закон распределения изобразить и графически, откладывая на оси абсцисс возможные значения случайной величины, а на оси ординат – соответствующие вероятности. Для большей выразительности полученные точки соединяются прямолинейными отрезками. Получающая при этом фигура называется многоугольником (полигоном) распределения.
Функция распределения вероятностей
Непрерывную случайную величину нельзя охарактеризовать перечнем всех возможных ее значений и их вероятностей. Естественно, встает вопрос о том, нельзя ли охарактеризовать случайную величину иным способом, одинаково годным как для дискретных, так и для непрерывных случайных величин.
Функцией распределения случайной величины Х называют функцию F(x), определяющую для каждого значения х, вероятность того, что случайная величина Х примет значение меньше х, т.е.
F(x) = P (X <x).
Иногда функцию F(x) называют интегральной функцией распределения.
Функция распределения обладает следующими свойствами:
1. Значение функции распределения принадлежит отрезку [0,1]: 0 ≤ F(x) ≤ 1.
2. Функции распределения есть неубывающая функция.
3. Вероятность того, что случайная величина Х примет значение, заключенное в интервале (а, b), равна приращению функции распределения на этом интервале:
Р(а < X < b) = F(b) – F(а). (2.1)
4. Если все возможные значения случайной величины Х принадлежат интервалу (а, b), то
F(x) = 0 при х ≤ а; F(x) = 1 при х ≥ b.
5. Справедливы следующие предельные
отношения:
![]()
.
Для дискретной случайной величины
Х, которая может принимать значения х1,
х2, …,хn, функция распределения имеет
вид
![]()
где неравенство под знаком суммы означает, что суммирование касается всех тех значений хi, величина которых меньше х.
Поясним эту формулу исходя из
определения функции F(x). Предположим,
что аргумент х принял какое-то определенное,
но такое, что выполняется неравенство
xi<x≤xi+1. Тогда левее числа х на числовой
оси окажутся только те значения случайной
величины, которые имеют индекс 1, 2, 3, …,
i. Поэтому неравенство Х<x выполняется,
если величина Х примет значения хк, где
k = 1, 2, …, i. Таким образом, событие Х<x
наступит, если наступит любое, неважно
какое, из событий Х = х1, Х=х2, Х=х3, …, Х=хi.
Так как эти события несовместны, то по
теореме сложения вероятностей имеем![]()
Предположим теперь, что для непрерывной случайной величины Х ее функция распределения F(x) имеет непрерывную производную
F'(x)= φ(x).
Функцию φ(x) называют плотностью вероятности (для данного распределения) или дифференциальной функцией.
Так как плотность вероятности φ(x) является производной неубывающей функции F(x), то она неотрицательна: φ(x)≥0. В отличие от функции распределения, плотность вероятности может принимать сколь угодно большие значения.
Так как F(x) является первообразной
для φ(x), то на основании формулы
Ньютона-Лейбница имеем
![]() .
Отсюда в силу P(a ≤ X ≤ b) = (3.1)
.
Отсюда в силу P(a ≤ X ≤ b) = (3.1)
P(a ≤ X ≤ b) = .
![]() (2.3)
(2.3)
Полагая а=–∞ и b=+∞, получаем достоверное
событие Х принадлежащее (–∞, +∞),
вероятность которого равна единице.
Следовательно,
![]()
В частности, если все возможные значения случайной величины принадлежат интервалу (а, b), то . Полагая в формуле а = –∞, b = х и обозначая для ясности переменную интегрирования t, получим функцию распределения
F(x) = P(– ∞ < X < x) =
![]() .
.
Задача 2.1. Найти интегральную функцию распределения случайной величины Х, заданной рядом распределения:
|
Х |
1 |
2 |
3 |
|
Р |
0,3 |
0,2 |
0,5 |
остроить ее график.
Решение. Пусть х ≤ 1, тогда F(x) = 0, так как событие Х < х будет невозможным. Если 1 < х ≤ 2, то на основании равенства (3.2) имеем F(x) = p1 = 0,3. Если 2 < х ≤ 3, то F(x) = p1 + p2 = 0,5.
Если х > 3, то F(x) = p1 + p2 + p3 = 1. Окончательно получаем
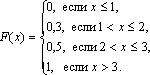
График функции F(х) изображен на рис.
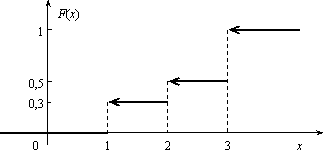
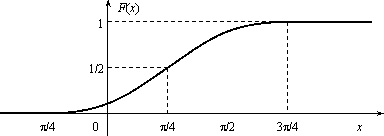
Задача. Функция распределения случайной величины Х задана выражением

Найти коэффициент α; вероятность попадания значения случайной величины Х в результате опыта в интервал (π/4; 3π/4); построить график функции.
Решение . При х=3 π/4 функция F(x ) равна 1, т.е. α∙ sin (3π/4–π/4)+1/2=1, или α∙si n(π/2) + 1/2 = 1. Откуда α = 1/2.
Подставляя а = π/4 и b = 3π/4 в равенство (3.1), получаем
π (π/4 <X<3π/4) = F(3π/4) - F(π/4) = 1/2 × sin(π/2)+1/2–1/2 × sin 0 – 1/2 = 1/2.
График функции у =1/2∙sin(х-π/4 )+1/2 отличается от графика функции у = sinх тем, что он «сжат» по оси Оу в два раза, сдвинут вправо на π/4, поднят вверх на 1/2. Воспользовавшись этим замечанием, отразим график F(x)
Числовые характеристики случайной величины
Функция распределения содержит полную информацию о случайной величине. На практике функцию распределения не всегда можно установить; иногда такого исчерпывающего знания и не требуется. Частичную информацию о случайной величине дают числовые характеристики, которые в зависимости от рода информации делятся на следующие группы.
1. Характеристики положения случайной величины на числовой оси (мода Мo, медиана Мe, математическое ожидание М(Х)).
2. Характеристики разброса случайной величины около среднего значения (дисперсия D(X), среднее квадратическое отклонение σ(х)).
3. Характеристики формы кривой y = φ(x) (асимметрия As, эксцесс Ех).
Рассмотрим подробнее каждую из
указанных характеристик. Математическое
ожидание случайной величины Х указывает
некоторое среднее значение, около
которого группируются все возможные
значения Х. Для дискретной случайной
величины, которая может принимать лишь
конечное число возможных значений,
математическим ожиданием называют
сумму произведений всех возможных
значений случайной величины на вероятность
этих значений:
![]() .
.
Математическое ожидание случайной
величины Х указывает некоторое среднее
значение, около которого группируются
все возможные значения Х. Для дискретной
случайной величины, которая может
принимать лишь конечное число возможных
значений, математическим ожиданием
называют сумму произведений всех
возможных значений случайной величины
на вероятность этих значений:
![]()
Для непрерывной случайной величины Х,
имеющей заданную плотность распределения
φ(x) математическим ожиданием называется
следующий интеграл:
![]()
Здесь предполагается, что несобственный
интеграл
![]() сходится абсолютно, т.е. существует.
сходится абсолютно, т.е. существует.
Свойства математического ожидания:
1. М(С) = C, где С = const;
2. M(C∙Х) = С∙М(Х);
3. М(Х ± Y) = М(Х) ± М(Y), где X и Y – любые случайные величины;
4. М(Х∙Y)=М(Х)∙М(Y), где X и Y – независимые случайные величины.
Две случайные величины называются независимыми, если закон распределения одной из них не зависит от того, какие возможные значения приняла другая величина.
Модой дискретной случайной величины, обозначаемой Мо, называется ее наиболее вероятное значение (рис. 2.3), а модой непрерывной случайной величины – значение, при котором плотность вероятности максимальна (рис. 2.4).
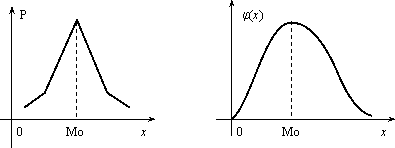
Рис. 2.3 Рис. 2.4
Медианой непрерывной случайной величины Х называется такое ее значение Ме, для которого одинаково вероятно, окажется ли случайная величина меньше или больше Ме, т.е.
Р(Х < Ме) = Р(X > Ме)
Из определения медианы следует, что Р(Х<Ме) = 0,5, т.е. F (Ме) = 0,5. Геометрически медиану можно истолковывать как абсциссу, в которой ордината φ(x) делит пополам площадь, ограниченную кривой распределения (рис. 2.5). В случае симметричного распределения медиана совпадает с модой и математическим ожиданием (рис. 2.6).
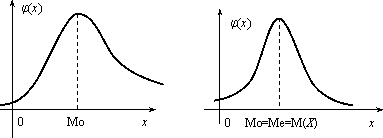
Рис. 2.5 Рис. 2.6
Дисперсией случайной величины называется математическое ожидание квадрата ее отклонения от математического ожидания
D(X) = M(X –М(Х))2.
Дисперсию случайной величины Х удобно вычислять по формуле:
а) для дискретной величины
; (2.6)
![]()
б) для непрерывной случайной величины
j(х)dx – [M(X)]2 .
![]() (2.7)
(2.7)
Дисперсия обладает следующими свойствами:
1. D(C) = 0, где С = const;
2. D(C×X) = C2∙D(X);
3. D(X±Y) = D(X) + D(Y), если X и Y независимые случайные величины.
Средним квадратическим отклонением случайной величины Х называется арифметический корень из дисперсии, т.е.
σ(X) =![]() .
.
Заметим, что размерность σ(х) совпадает с размерностью самой случайной величины Х, поэтому среднее квадратическое отклонение более удобно для характеристики рассеяния.
Обобщением основных числовых характеристик случайных величин является понятие моментов случайной величины.
Центральным моментом k-го порядка μk случайной величины Х называется математическое ожидание величины (Х–М(Х))k, т.е. μk = М(Х–М(Х))k.
Центральный момент второго порядка – это дисперсия случайной величины.
Для дискретной случайной величины
начальный момент выражается суммой αk
=![]() , а центральный – суммой μk =
, а центральный – суммой μk =![]() где рi = p(X = xi). Для начального и центрального
моментов непрерывной случайной величины
можно получить следующие равенства:
где рi = p(X = xi). Для начального и центрального
моментов непрерывной случайной величины
можно получить следующие равенства:
αk =
![]() ,
μk =
,
μk =
![]() ,
,
где φ(x) – плотность распределения случайной величины Х.
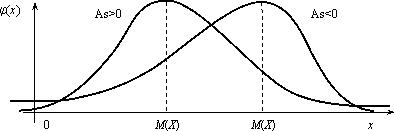
Величина As = μ3 / σ3 называется коэффициентом асимметрии.
Если коэффициент асимметрии отрицательный, то это говорит о большом влиянии на величину m3 отрицательных отклонений. В этом случае кривая распределения (рис.2.7) более полога слева от М(Х). Если коэффициент As положительный, а значит, преобладает влияние положительных отклонений, то кривая распределения (рис.2.7) более полога справа. Практически определяют знак асимметрии по расположению кривой распределения относительно моды (точки максимума дифференциальной функции).
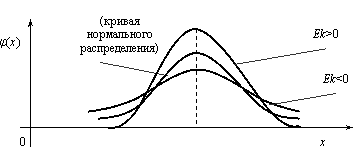
Эксцессом Еk называется величина
Еk = μ4 / σ4 – 3.
Можно показать, что для наиболее распространенного в природе нормального закона распределения, который будет рассматриваться в следующем параграфе, отношение μ4 / σ4 = 3. Поэтому эксцесс служит для сравнения данного распределения с нормальным, у которого эксцесс равен нулю. Можно было бы доказать, что распределения более островершинные, чем нормальное, имеют эксцесс Еk > 0, а более плосковершинные – имеют эксцесс Еk < 0 (рис.3.8).
Задача. Дискретная случайная величина Х, имеющая смысл числа курьеров, задействованных для доставки корреспонденции в коммерческой организации, задана законом распределения:
|
Х |
0 |
1 |
2 |
3 |
|
Р |
0,4 |
0,1 |
0,3 |
0,2 |
Найти математическое ожидание, дисперсию, среднее квадратическое отклонение.
Решение. Так как случайная величина является дискретной, то для вычисления М(Х) воспользуемся формулой (3.4). Имеем
М( х) = х1 × р1 + х2 × р2 + х3 × р3 + х4 × р4 = 0 × 0,4 + 1 ×0,1 + 2 × 0,3 + 3 × 0,2 = 1,3.
Найдем дисперсию D(x). Предварительно найдем математическое ожидание от х2:
М(х2) = х12 × р1 + х22 × р2+ х32 × р3+ х42 × р4 = 02 × 0,4 + 12 × 0,1 + 22 × 0,3 + 32 × 0,2 = 3,1.
Далее по формуле (3.6) получаем
D(X) = 3,1 – 1,32 = 3,1 – 1,69 = 1,41.
Найдем среднее квадратическое отклонение. Имеем
σ(х) =![]() .
.
Таким образом, среднее число курьеров равно 1,3 со средним разбросом 1,22.
Задача. Непрерывная случайная величина
Х задана функцией распределения:
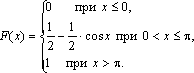
Найти математическое ожидание и
дисперсию этой случайной величины.
Решение . По определению дифференциальной
функции φ(х) = F ¢ ( x ). Отсюда
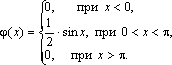
В точках х = 0 и х = π функция φ(х) не дифференцируема. По формуле (3.5) получаем
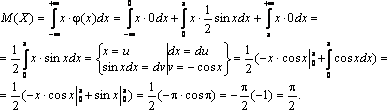
Находим сначала М(Х2). Имеем
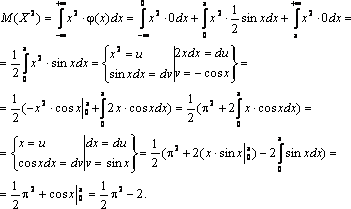
Далее по формуле (3.7) получаем
![]() .
.
Биномиальное распределение
Пусть в каждом из n независимых испытаний событие А может произойти с одной и той же вероятностью р (следовательно, вероятность непоявления q =1 – p). Дискретная случайная величина Х – число наступлений события А – имеет распределение, которое называется биномиальным.
Очевидно, событие А в n испытаниях может либо не появиться, либо появиться 1 раз, либо 2 раза, …, либо n раз. Таким образом, возможные значения Х таковы: х1 = 0, х2 = 1, х3 = 2,…, хn+1 = n. Вероятность возможного значения Х = k (числа k появления события) вычисляют по формуле Бернулли:
Pn(k) = Cnk·pk·qn–k,
где k = 0, 1, 2, …, n.
Ряд распределения случайной величины Х, подчиненной биномиальному закону, можно представить в виде следующей таблицы:
|
Х |
0 |
1 |
… |
k |
… |
n |
|
Р |
Cn0· p0·qn |
Cn1 ·p1·qn–1 |
… |
Cnk·pk·qn–k |
… |
Cnn·pn·q0 |
Название закона связано с тем, что вероятности Pn(k) при k = 0, 1, 2, …, n являются членами разложения бинома Ньютона
(p + q)n = qn + Cn1·p1·qn–1 + … + Cnk·pk·qn–k + … +pn.
Отсюда сразу видно, что сумма всех вероятностей второй строки таблицы равна 1, так как p +q =1.
Задача. В цехе работают четыре станка. Вероятность остановки в течение часа каждого из них равна 0,8. 1) Найти закон распределения случайной величины Х – числа станков, остановившихся в течение часа. 2) Найти вероятность остановки в течение часа: а) более двух станков; б) от одного до трех станков.
Решение. 1) Возможные значения Х следующие: 0, 1, 2, 3, 4. Вероятность этих значений можно найти по формуле Бернулли, потому что Х имеет биномиальное распределение (станки останавливаются независимо друг от друга с постоянной вероятностью р=0,8). Получаем р4(0)=q4=0,0016, р4(1)=C41p1q3=0,0256, р4(2)= C42 p2q2 = 0,154, р4(3)=C43 · p3· q1=0,41, р4(4)= p 4 = 0,41. Ряд распределения имеет вид
|
Х |
0 |
1 |
2 |
3 |
4 |
|
Р |
0,0016 |
0,0256 |
0,154 |
0,41 |
0,41 |
2) а) Р(X>2)= P(X =3)+P(X=4)=0,41+0,41=0,82.
б) P1≤X≤3)=P(X=1)+P(X=2)+ P(X=3)=0,0256+0,154+0,41=0,59.
Распределение Пуассона
Это распределение представляет собой предельный случай биномиального, когда вероятность р очень мала, а число испытаний n велико.
Таким образом, им можно пользоваться при описании частот распределения редких событий, таких, например, как случай обширных наводнений на протяжении долгого периода времени наблюдений.
Дискретная случайная величина Х,
которая может принимать только целые
неотрицательные значения с вероятностями
![]() ,
,
где k – число появления событий в n независимых испытаниях, λ = n· p (среднее число появлений события в n испытаниях), называется распределенной по закону Пуассона с параметром λ.
В отличие от биномиального распределения здесь случайная величина может принимать бесконечное множество значений, представляющее собой бесконечную последовательность целых чисел 0, 1, 2, 3, … .
Закон Пуассона описывает число событий k, происходящих за одинаковые промежутки времени. При этом полагается, что события появляются независимо друг от друга с постоянной средней интенсивностью, которая характеризуется параметром λ = n·p . Так как для распределения Пуассона вероятность р появления события в каждом испытании мала, то это распределение называют законом распределения редких явлений.
По распределению Пуассона распределено, например число посетителей магазина или банка за определенный промежуток времени, при этом λ – среднее число посетителей за это время.
Предположим, что в среднем в магазин приходит 2,1 покупатель в минуту. Тогда, используя (3.8), получаем, например, вероятности того, что магазин посетят за минуту 1, 4 и 10 посетителей:
![]() ,
,
![]() ,
,
![]() .
.
Основанием считать статистическое распределение пуассоновским является близость значений статистических характеристик и S2 (которые являются статистическими приближениями математического ожидания и дисперсии), так как для теоретического распределения Пуассона имеет место: М(Х) = D( X) = λ.
Равномерное распределение
Непрерывная случайная величина Х имеет равномерное распределение на отрезке [a, b], если ее плотность имеет следующий вид:
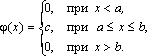
График плотности распределения
показан на рис. 2.9.
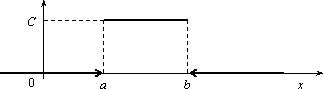
φ(х)
Рис. 2.9
Найдем значение постоянной С. Так
как площадь, ограниченная кривой
распределения и осью Ох, равна 1, то![]() ,
,
откуда С = 1/(b – a).
Пусть [ α, β ] Ì [a, b]. Тогда
![]() ,
т.е.
,
т.е.
![]() (2.9)
(2.9)
где L – длина (линейная мера) всего отрезка [a, b] и – длина частичного отрезка [ α, β].
Значения случайной величины Х, т.е. точки х отрезка [a,b], можно рассматривать как всевозможные элементарные исходы некоторого испытания. Пусть событие А состоит в том, что результат испытания принадлежит отрезку [ α, β] Ì [a, b]. Тогда точки отрезка [ α, β] есть благоприятные элементарные исходы события А.
Согласно формуле (2.9) имеем геометрическое
определение вероятности: под вероятностью
события А понимается отношение меры
множества элементарных исходов,
благоприятствующих событию А, к мере L
множества всех возможных элементарных
исходов в предположении, что они
равновозможны:
![]()
Это определение естественно переносит классическое определение вероятности на случай бесконечного числа элементарных исходов (случаев).
Аналогичное определение можно ввести также тогда, когда элементарные исходы испытания представляют собой точки плоскости или пространства.
Задача. В течение часа 0 ≤ t ≤ 1 (t – время в часах) на остановку прибывает один и только один автобус. Какова вероятность того, что пассажиру, пришедшему на эту остановку в момент времени t = 0, придется ожидать автобус не более 10 минут?
Решение . Здесь множество всех
элементарных исходов образует отрезок
[0,1], временная длина которого L =1, а
множество благоприятных элементарных
исходов составляет отрезок [0,1/6] временной
длины
![]() =1/6.
=1/6.
Поэтому искомая вероятность есть
![]()
Задача. В квадрат К со стороной а с вписанным в него кругом S (рис. 3.10) случайно бросается материальная точка М. Какова вероятность того, что эта точка попадает в круг S?
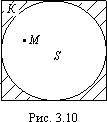
Решение . Здесь площадь квадрата К
=а в2, а площадь круга
![]()
За искомую вероятность естественно
принять отношение![]()
Эта вероятность, а следовательно, и число π, очевидно, могут быть определены экспериментально.
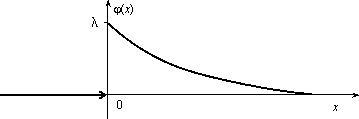
Показательное распределение
Непрерывная случайная величина Х,
функция плотности которой задается
выражением![]()
называется случайной величиной, имеющей показательное, или экспоненциальное, распределение. Здесь параметр λ постоянная положительная величина.
Величина срока службы различных устройств и времени безотказной работы отдельных элементов этих устройств при выполнении определенных условий обычно подчиняется показательному распределению. Также этому распределению подчиняется время ожидания клиента в системе массового обслуживания (магазин, мастерская, банк, парикмахерская и т.д.). Другими словами, величина промежутка времени между появлениями двух последовательных редких событий подчиняется зачастую показательному распределению. График дифференциальной функции показательного распределения показан
Нормальное распределение
Случайная величина Х имеет нормальное распределение (или распределение по закону Гаусса), если ее плотность вероятности имеет вид:
![]() ,
,
где параметры а – любое действительное число и σ >0.
График дифференциальной функции
нормального распределения называют
нормальной кривой (кривой Гаусса).
Нормальная кривая (рис. 2.12) симметрична
относительно прямой х =а, имеет максимальную
ординату
![]() , а в точках х = а ± σ – перегиб.
, а в точках х = а ± σ – перегиб.
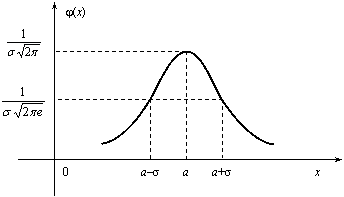
Доказано, что параметр а является математическим ожиданием (также модой и медианой), а σ – средним квадратическим отклонением. Коэффициенты асимметрии и эксцесса для нормального распределения равны нулю: As = Ex = 0.
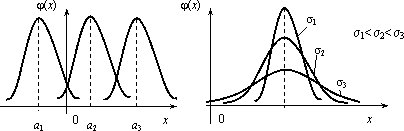
Установим теперь, как влияет изменение параметров а и σ на вид нормальной кривой. При изменении параметра а форма нормальной кривой не изменяется. В этом случае, если математическое ожидание (параметр а) уменьшилось или увеличилось, график нормальной кривой сдвигается влево или вправо (рис. 2.13).
При изменении параметра σ изменяется
форма нормальной кривой. Если этот
параметр увеличивается, то максимальное
значение
![]() функции убывает, и наоборот. Так как
площадь, ограниченная кривой распределения
и осью Ох, должна быть постоянной и
равной 1, то с увеличением параметра σ
кривая приближается к оси Ох и растягивается
вдоль нее, а с уменьшением σ кривая
стягивается к прямой х = а (рис. 2.14).
функции убывает, и наоборот. Так как
площадь, ограниченная кривой распределения
и осью Ох, должна быть постоянной и
равной 1, то с увеличением параметра σ
кривая приближается к оси Ох и растягивается
вдоль нее, а с уменьшением σ кривая
стягивается к прямой х = а (рис. 2.14).
Функция плотности нормального распределения φ(х) с параметрами а = 0, σ = 1 называется плотностью стандартной нормальной случайной величины, а ее график – стандартной кривой Гаусса.
Функция плотности нормальной
стандартной величины определяется
формулой
![]() ,
а ее график изображен
,
а ее график изображен
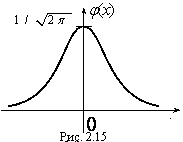 .
.
Из свойств математического ожидания
и дисперсии следует, что для величины
![]() ,
D(U)=1, M(U) = 0. Поэтому стандартную нор
мальную кривую можно рассматривать как
кривую распределения случайной величины
,
D(U)=1, M(U) = 0. Поэтому стандартную нор
мальную кривую можно рассматривать как
кривую распределения случайной величины
![]() ,
где Х – случайная величина, подчиненная
нормальному закону распределения с
параметрами а и σ.
,
где Х – случайная величина, подчиненная
нормальному закону распределения с
параметрами а и σ.
Нормальный закон распределения
случайной величины в интегральной форме
имеет вид
![]()
(2.10)
Полагая в интеграле (3.10)
![]() , получим
, получим
![]()
,
Где
![]() . Первое слагаемое равно 1/2 (половине
площади криволинейной трапеции,
изображенной на рис. 3.15). Второе слагаемое
. Первое слагаемое равно 1/2 (половине
площади криволинейной трапеции,
изображенной на рис. 3.15). Второе слагаемое
![]()
называется функцией Лапласа, а также интегралом вероятности.
Поскольку интеграл в формуле (2.11) не выражается через элементарные функции, для удобства расчетов составлена для z ≥ 0 таблица функции Лапласа. Чтобы вычислить функцию Лапласа для отрицательных значений z, необходимо воспользоваться нечетностью функции Лапласа: Ф(–z) = – Ф(z). Окончательно получаем расчетную формулу
![]()
Отсюда получаем, что для случайной
величины Х, подчиняющейся нормальному
закону, вероятность ее попадания на
отрезок [ α, β] есть
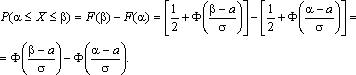
С помощью формулы предыдущей найдем вероятность того, что модуль отклонения нормального распределения величины Х от ее центра распределения а меньше 3σ. Имеем
Р(|x – a| < 3 s) =P(а–3 s< X< а+3 s)= Ф(3) – Ф(–3) = 2Ф(3) »0,9973.
Значение Ф(3) получено по таблице функции Лапласа.
Принято считать событие практически достоверным, если его вероятность близка к единице, и практически невозможным, если его вероятность близка к нулю.
Мы получили так называемое правило трех сигм: для нормального распределения событие (|x–a| < 3σ) практически достоверно.
Правило трех сигм можно сформулировать иначе: хотя нормальная случайная величина распределена на всей оси х, интервал ее практически возможных значений есть (a–3σ, a+3σ).
Нормальное распределение имеет ряд свойств, делающих его одним из самых употребительных в статистике распределений.
Если предоставляется возможность рассматривать некоторую случайную величину как сумму достаточно большого числа других случайных величин, то данная случайная величина обычно подчиняется нормальному закону распределения. Суммируемые случайные величины могут подчиняться каким угодно распределениям, но при этом должно выполняться условие их независимости (или слабой независимости). Также ни одна из суммируемых случайных величин не должна резко отличаться от других, т.е. каждая из них должна играть в общей сумме примерно одинаковую роль и не иметь исключительно большую по сравнению с другими величинами дисперсию.
Этим и объясняется широкая распространенность нормального распределения. Оно возникает во всех явлениях, процессах, где рассеяния случайной изучаемой величины вызывается большим количеством случайных причин, влияние каждой из которых в отдельности на рассеяние ничтожно мало.
Большинство встречающихся на практике случайных величин (таких, например, как количества продаж некоторого товара, ошибка измерения; отклонение снарядов от цели по дальности или по направлению; отклонение действительных размеров деталей, обработанных на станке, от номинальных размеров и т.д.) может быть представлено как сумма большого числа независимых случайных величин, оказывающих равномерно малое влияние на рассеяние суммы. Такие случайные величины принято считать нормально распределенными. Гипотеза о нормальности подобных величин находит свое теоретическое обоснование в центральной предельной теореме и получила многочисленные практические подтверждения.
Представим себе, что некоторый товар реализуется в нескольких торговых точках. Из–за случайного влияния различных факторов количества продаж товара в каждой точке будут несколько различаться, но среднее всех значений будет приближаться к истинному среднему числу продаж.
Отклонения числа продаж в каждой торговой точке от среднего образуют симметричную кривую распределения, близкую к кривой нормального распределения. Любое систематическое влияние какого-либо фактора проявится в асимметрии распределения.
Задача . Случайная величина распределена нормально с параметрами а = 8, σ = 3.Найти вероятность того, что случайная величина в результате опыта примет значение, заключенной в интервале (12,5; 14).
Решение. Воспользуемся формулой (2.12). Имеем
Задача . Число проданного за неделю товара определенного вида Х можно считать распределенной нормально. Математическое ожидание числа продаж тыс. шт. Среднее квадратическое отклонение этой случайной величины σ = 0,8 тыс. шт. Найти вероятность того, что за неделю будет продано от 15 до 17 тыс. шт. товара.
Решение. Случайная величина Х распределена нормально с параметрами а = М(Х) = 15,7; σ = 0,8. Требуется вычислить вероятность неравенства 15 ≤ X ≤ 17. По формуле (2.12) получаем

Элементы математической статистики
Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных - результатов наблюдений.
Статистические данные представляют собой данные, полученные в результате обследования большого числа объектов или явлений; следовательно, математическая статистика имеет дело с массовыми явлениями.
Первая задача математической статистики - указать способы сбора и группировки статистических сведений, полученных в результате наблюдений или в результате специально поставленных экспериментов.
Вторая задача математической статистики - разработать методы анализа статистических данных в зависимости от целей исследования.
Современная математическая статистика разрабатывает способы определения числа необходимых испытаний до начала исследования, в ходе исследования и решает многие другие задачи. Современную математическую статистику определяют как науку о принятии решений в условиях неопределенности
Итак, задача математической статистики состоит в создании методов сбора и обработки статистических данных для получения научных и практических выводов.
Генеральная и выборочная совокупность статистических данных
Пусть требуется изучить совокупность однородных объектов относительно некоторого качественного или количественного признака, характеризующего эти объекты.
Качественными признаками объект обладает либо не обладает. Они не поддаются непосредственному измерению (например, спортивная специализация, квалификация, национальность, территориальная принадлежность и т. п.).
Количественные признаки представляют собой результаты подсчета или измерения. В соответствии с этим они делятся на дискретные и непрерывные.
Иногда проводиться сплошное обследование, т.е. обследуют каждый из объектов совокупности относительно признака, которым интересуются. На практике сплошное обследование применяют сравнительно редко. Например, если совокупность содержит очень большое число объектов, то провести сплошное обследование физически невозможно. В таких случаях случайно отбирают из всей совокупности ограниченное число объектов и подвергают их изучению. Различают генеральную и выборочную совокупности.
Выборочной совокупностью (выборкой) называют совокупность случайно отобранных объектов.
Генеральной (основной) совокупностью называют совокупность, объектов из которых производится выборка.
Объемом совокупности (выборочной или генеральной) называют число объектов этой совокупности. Например, если из 1000 деталей отобрано для обследования 100 деталей, то объем генеральной совокупности N = 1000, а объем выборки n =100. Число объектов генеральной совокупности N значительно превосходит объем выборки n .
Способы выборки
При составлении выборки можно поступать двумя способами: после того как объект отобран и над ним произведено наблюдение, он может быть возвращен либо не возвращен в генеральную совокупность. В соответствии со сказанным выборки подразделяют на повторные и бесповторные.
Повторной называют выборку, при которой отобранный объект (перед отбором следующего) возвращается в генеральную совокупность.
Бесповторной называют выборку, при которой отобранный объект в генеральную совокупность не возвращается.
На практике обычно пользуются бесповторным случайным отбором.
Для того чтобы по данным выборки можно было достаточно уверенно судить об интересующем признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли (выборка должна правильно представлять пропорции генеральной совокупности) - выборка должна быть репрезентативной (представительной).
Выборка будет репрезентативной, если:
каждый объект выборки отобран случайно из генеральной совокупности;
все объекты имеют одинаковую вероятность попасть в выборку.
Обычно полученные наблюдаемые данные представляют собой множество расположенных в беспорядке чисел. Просматривая это множество чисел, трудно выявить какую-либо закономерность их варьирования (изменения). Для изучения закономерностей варьирования значений случайной величины опытные данные подвергают обработке.
Пример 1. Проводились наблюдения над числом Х оценок полученных студентами ВУЗа на экзаменах. Наблюдения в течение часа дали следующие результаты: 3; 4; 3; 5; 4; 2; 2; 4; 4; 3; 5; 2; 4; 5; 4; 3; 4; 3; 3; 4; 4; 2; 2; 5; 5; 4; 5; 2; 3; 4; 4; 3; 4; 5; 2; 5; 5; 4; 3; 3; 4; 2; 4; 4; 5; 4; 3; 5; 3; 5; 4; 4; 5; 4; 4; 5; 4; 5; 5; 5. Здесь число Х является дискретной случайной величиной, а полученные о ней сведения представляют собой статистические (наблюдаемые) данные.
Расположив приведенные выше данные в порядке неубывания и сгруппировав их так, что в каждой отдельной группе значения случайной величины будут одинаковы, получают ранжированный ряд данных наблюдения.
В примере 1 имеем четыре группы со следующими значениями случайной величины: 2; 3; 4; 5. Значение случайной величины, соответствующее отдельной группе сгруппированного ряда наблюдаемых данных, называют вариантом, а изменение этого значения варьированием.
Варианты обозначают малыми буквами латинского алфавита с соответствующими порядковому номеру группы индексами - xi. Число, которое показывает, сколько раз встречается соответствующий вариант в ряде наблюдений называют частотой варианта и обозначают соответственно - ni.
Сумма всех частот ряда
![]() - объем выборки. Отношение частоты
варианта к объему выборки ni / n = wi называют
относительной частотой.
- объем выборки. Отношение частоты
варианта к объему выборки ni / n = wi называют
относительной частотой.
Статистическим распределением выборки называют перечень вариантов и соответствующих им частот или относительных частот (табл. 1, табл. 2).
Пример 2. Задано распределение частот выборки объема n = 20:
|
Х1 |
2 |
6 |
12 |
|
N1 |
3 |
10 |
7 |
Написать распределение относительных частот.
Решение. Найдем относительные частоты, для чего разделим частоты на объем выборки:
W1 = 3/20 = 0,15; W2 = 10/20 = 0,50; W3 = 7/20 = 0,35.
Напишем распределение относительных частот:
|
X1 |
2 |
6 |
12 |
|
W1 |
0,15 |
0,50 |
0,39 |
Контроль: 0,15 + 0,50 + 0, 35 = 1.
Статистическое распределение можно задать также в виде последовательности интервалов и соответствующих им частот (в качестве частоты, соответствующей интервалу, принимают сумму частот, попавших в этот интервал).
Дискретным вариационным рядом распределения называют ранжированную совокупность вариантов xi с соответствующими им частотами ni или относительными частотами wi.
Для рассмотренного выше примера 1 дискретный вариационный ряд имеет вид:
|
X1 |
2 |
3 |
4 |
5 |
|
N1 |
8 |
12 |
23 |
17 |
|
W1 |
8/60 |
12/60 |
23/60 |
17/60 |
Контроль: сумма всех частот вариационного ряда (сумма значений второй строки таблицы 3) есть объем выборки (в примере 1 n = 60 ); сумма относительных частот вариационного ряда должна быть равна 1 (сумма значений третьей строки таблицы.
Интервальный вариационный ряд
Если изучаемая случайная величина является непрерывной, то ранжирование и группировка наблюдаемых значений зачастую не позволяют выделить характерные черты варьирования ее значений. Это объясняется тем, что отдельные значения случайной величины могут как угодно мало отличаться друг от друга и поэтому в совокупности наблюдаемых данных одинаковые значения величины могут встречаться редко, а частоты вариантов мало отличаются друг от друга.
Нецелесообразно также построение дискретного ряда для дискретной случайной величины, число возможных значений которой велико. В подобных случаях следует строить интервальный вариационный ряд распределения.
Для построения такого ряда весь интервал варьирования наблюдаемых значений случайной величины разбивают на ряд частичных интервалов и подсчитывают частоту попадания значений величины в каждый частичный интервал.
Интервальным вариационным рядом называют упорядоченную совокупность интервалов варьирования значений случайной величины с соответствующими частотами или относительными частотами попаданий в каждый из них значений величины.
Для построения интервального ряда необходимо:
определить величину частичных интервалов;
определить ширину интервалов;
установить для каждого интервала его верхнюю и нижнюю границы;
сгруппировать результаты наблюдении.
1. Вопрос о выборе числа и ширины интервалов группировки приходится решать в каждом конкретном сkучае исходя из целей исследования, объема выборки и степени варьирования признака в выборке.
Приблизительно число интервалов k можно оценить исходя только из объема выборки n одним из следующих способов:
по формуле Стержеса: k = 1 + 3,32·lg n;
с помощью таблицы 1.
|
Объем выборки, n |
25-40 |
40-60 |
60-100 |
100-200 |
Более 200 |
|
Число интервалов, k
|
5-6 |
6-8 |
7-10 |
8-12 |
10-15 |
2. Обычно предпочтительны интервалы одинаковой ширины. Для определения ширины интервалов h вычисляют:
размах варьирования R - значений выборки: R = xmax - xmin,
где xmax и xmin - максимальная и минимальная варианты выборки;
ширину каждого из интервалов h определяют по следующей формуле: h = R/k.
3. Нижняя граница первого интервала xh1 выбирается так, чтобы минимальная варианта выборки xmin попадала примерно в середину этого интервала: xh1 = xmin - 0,5·h .
Промежуточные интервалы получают прибавляя к концу предыдущего интервала длину частичного интервала h:
xhi = xhi-1 +h .
Построение шкалы интервалов на основе вычисления границ интервалов продолжается до тех пор, пока величина xhi удовлетворяет соотношению:
xhi < xmax + 0,5·h .
4. В соответствии со шкалой интервалов производится группирование значений признака - для каждого частичного интервала вычисляется сумма частот ni вариант, попавших в i-й интервал. При этом в интервал включают значения случайной величины, большие или равные нижней границе и меньшие верхней границы интервала.
Полигон и гистограмма
Для наглядности строят различные графики статистического распределения.
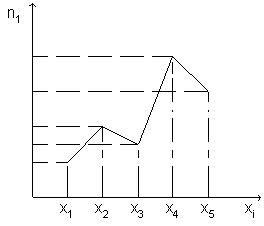
По данным дискретного вариационного ряда строят полигон частот или относительных частот.
Полигоном частот называют ломанную, отрезки которой соединяют точки (x1; n1), (x2; n2), ..., (xk; nk). Для построения полигона частот на оси абсцисс откладывают варианты xi, а на оси ординат - соответствующие им частоты ni. Точки ( xi; ni) соединяют отрезками прямых и получают полигон частот (Рис. 1).
Полигоном относительных частот называют ломанную, отрезки которой соединяют точки (x1; W1), (x2; W2), ..., (xk; Wk). Для построения полигона относительных частот на оси абсцисс откладывают варианты xi, а на оси ординат - соответствующие им относительные частоты Wi. Точки ( xi; Wi) соединяют отрезками прямых и получают полигон относительных частот.
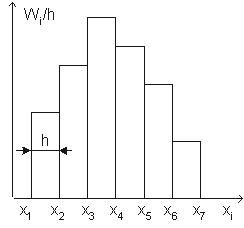
В случае непрерывного признака целесообразно строить гистограмму.
Гистограммой частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиной h, а высоты равны отношению ni / h (плотность частоты).
Для построения гистограммы частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии ni / h.
Площадь i - го частичного прямоугольника равна hni / h = ni - сумме частот вариант i - го интервала; следовательно, площадь гистограммы частот равна сумме всех частот, т.е. объему выборки.
Гистограммой относительных частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиной h, а высоты равны отношению Wi / h (плотность относительной частоты).
Для построения гистограммы относительных частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии Wi / h (Рис. 2).
Площадь i - го частичного прямоугольника равна hWi / h = Wi - относительной частоте вариант попавших в i - й интервал. Следовательно, площадь гистограммы относительных частот равна сумме всех относительных частот, т.е. единице.
Оценка параметров генеральной совокупности
Характеристики положения
Основными параметрами генеральной совокупности являются математическое ожидание (генеральная средняя) М(Х) и среднее квадратическое отклонение s. Это постоянные величины, которые можно оценить по выборочным данным. Оценка генерального параметра, выражаемая одним числом, называется точечной.
Точечной оценкой генеральной средней
является выборочное среднее
![]() .
.
Выборочным средним называется среднее арифметическое значение признака выборочной совокупности.
Если все значения x1, x2,..., xn признака выборки различны (или если данные не сгруппированы), то:
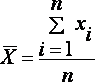
Если же все значения признака x1, x2,...,
xn имеют соответственно частоты n1, n2,...,
nk, причем n1 + n2 +...+ nk = n (или если выборочное
среднее вычисляется по вариационному
ряду), то
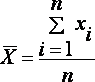
В том случае, когда статистические
данные представлены в виде интервального
вариационного ряда, при вычислении
выборочного среднего
![]() значениями
вариант считают середины интервалов.
значениями
вариант считают середины интервалов.
Выборочное среднее является основной характеристикой положения, показывает центр распределения совокупности, позволяет охарактеризовать исследуемую совокупность одним числом, проследить тенденцию развития, сравнить различные совокупности (выборочное среднее является той точкой, сумма отклонений наблюдений от которой равна 0).
Для оценки степени разброса (отклонения) какого-то показателя от его среднего значения, наряду с максимальным и минимальным значениями, используются понятия дисперсии и стандартного отклонения.
Дисперсия выборки или выборочная дисперсия (от английского variance) – это мера изменчивости переменной. Термин впервые введен Фишером в 1918 году.
Выборочной дисперсией Dв называют
среднее арифметическое квадратов
отклонения наблюдаемых значений признака
от их среднего значения
![]() .
.
Если все значения x1, x2,..., xn признака выборки объема n различны, то:
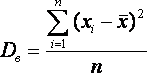
Если же все значения признака x1, x2,..., xn имеют соответственно частоты n1, n2,..., nk, причем n1 + n2 +...+ nk = n, то
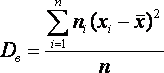
Дисперсия меняется от нуля до бесконечности. Крайнее значение 0 означает отсутствие изменчивости, когда значения переменной постоянны.
Среднее квадратическое отклонение
(стандартное отклонение), (от английского
standard deviation) вычисляется как корень
квадратный из дисперсии.
![]()
Чем выше дисперсия или стандартное отклонение, тем сильнее разбросаны значения переменной относительно среднего.
Непараметрическими характеристиками положения являются мода и медиана.
Модой Mo называется варианта, имеющая наибольшую частоту или относительную частоту.
Медианой Me называется варианта, которая делит вариационный ряд на две части, равные по числу вариант.
При нечетном числе вариант (n=2k+1)
Me = xk+1,
а при четном числе вариант (n=2k)
Me = (xk + xk+1)/2.
Методика проверки статистических гипотез
Пусть задана случайная выборка
![]() — последовательность
— последовательность
![]() объектов из множества Х . Предполагается,
что на множестве Х существует некоторая
неизвестная вероятностная мера Р .
объектов из множества Х . Предполагается,
что на множестве Х существует некоторая
неизвестная вероятностная мера Р .
Методика состоит в следующем.
Формулируется нулевая гипотеза
![]() о распределении вероятностей на множестве
Х. Гипотеза формулируется исходя из
требований прикладной задачи. Чаще
всего рассматриваются две гипотезы —
основная или нулевая
о распределении вероятностей на множестве
Х. Гипотеза формулируется исходя из
требований прикладной задачи. Чаще
всего рассматриваются две гипотезы —
основная или нулевая
![]() и
альтернативная
и
альтернативная
![]() . Иногда альтернатива не формулируется
в явном виде; тогда предполагается, что
. Иногда альтернатива не формулируется
в явном виде; тогда предполагается, что
![]() означает «не »
означает «не »
![]() .
Иногда рассматривается сразу несколько
альтернатив. В математической статистике
хорошо изучено несколько десятков
«наиболее часто встречающихся» типов
гипотез, и известны ещё сотни специальных
вариантов и разновидностей. Примеры
приводятся ниже.
.
Иногда рассматривается сразу несколько
альтернатив. В математической статистике
хорошо изучено несколько десятков
«наиболее часто встречающихся» типов
гипотез, и известны ещё сотни специальных
вариантов и разновидностей. Примеры
приводятся ниже.
Задаётся некоторая статистика (функция
выборки)
![]() ,
для которой в условиях справедливости
гипотезы
,
для которой в условиях справедливости
гипотезы![]() выводится функция распределения
выводится функция распределения
![]() и/или
плотность распределения
и/или
плотность распределения
![]() .
Вопрос о том, какую статистику надо
взять для проверки той или иной гипотезы,
часто не имеет однозначного ответа.
Есть целый ряд требований, которым
должна удовлетворять «хорошая» статистика
Т . Вывод функции распределения
.
Вопрос о том, какую статистику надо
взять для проверки той или иной гипотезы,
часто не имеет однозначного ответа.
Есть целый ряд требований, которым
должна удовлетворять «хорошая» статистика
Т . Вывод функции распределения
![]() при
заданных
при
заданных
![]() и Т является строгой математической
задачей, которая решается методами
теории вероятностей; в справочниках
приводятся готовые формулы для
и Т является строгой математической
задачей, которая решается методами
теории вероятностей; в справочниках
приводятся готовые формулы для![]() ; в статистических пакетах имеются
готовые вычислительные процедуры.
; в статистических пакетах имеются
готовые вычислительные процедуры.
Фиксируется уровень значимости —
допустимая для данной задачи вероятность
ошибки первого рода, то есть того, что
гипотеза на самом деле верна, но будет
отвергнута процедурой проверки. Это
должно быть достаточно малое число![]() . На практике часто полагают
. На практике часто полагают
![]() .
.
На множестве допустимых значений Т
статистики выделяется критическое
множество
![]() наименее вероятных значений статистики
Т, такое, что
наименее вероятных значений статистики
Т, такое, что
![]() . Вычисление границ критического
множества как функции от уровня значимости
. Вычисление границ критического
множества как функции от уровня значимости
![]() является строгой математической задачей,
которая в большинстве практических
случаев имеет готовое простое решение.
является строгой математической задачей,
которая в большинстве практических
случаев имеет готовое простое решение.
Собственно статистический тест (статистический критерий) заключается в проверке условия:
если
![]() ,
то делается вывод «данные противоречат
нулевой гипотезе при уровне значимости
,
то делается вывод «данные противоречат
нулевой гипотезе при уровне значимости
![]() ». Гипотеза отвергается.
». Гипотеза отвергается.
если
![]() ,
то делается вывод «данные не противоречат
нулевой гипотезе при уровне значимости
,
то делается вывод «данные не противоречат
нулевой гипотезе при уровне значимости
![]() ».
Гипотеза принимается.
».
Гипотеза принимается.
Итак, статистический критерий определяется
статистикой Т и критическим множеством
![]() ,
которое зависит от уровня значимости
,
которое зависит от уровня значимости
![]() .
.
Замечание. Если данные не противоречат нулевой гипотезе, это ещё не значит, что гипотеза верна. Тому есть две причины.
По мере увеличения длины выборки нулевая гипотеза может сначала приниматься, но потом выявятся более тонкие несоответствия данных гипотезе, и она будет отвергнута. То есть многое зависит от объёма данных; если данных не хватает, можно принять даже самую неправдоподобную гипотезу.
Выбранная статистика Т может отражать
не всю информацию, содержащуюся в
гипотезе
![]() .
В таком случае увеличивается вероятность
ошибки второго рода — нулевая гипотеза
может быть принята, хотя на самом деле
она не верна. Допустим, например, что
.
В таком случае увеличивается вероятность
ошибки второго рода — нулевая гипотеза
может быть принята, хотя на самом деле
она не верна. Допустим, например, что
![]() = «распределение нормально»; =
= «распределение нормально»; =
![]() «коэффициент асимметрии»; тогда выборка
с любым симметричным распределением
будет признана нормальной. Чтобы избегать
таких ошибок, следует пользоваться
более мощными критериями.
«коэффициент асимметрии»; тогда выборка
с любым симметричным распределением
будет признана нормальной. Чтобы избегать
таких ошибок, следует пользоваться
более мощными критериями.
Альтернативная методика на основе достигаемого уровня значимости
Широкое распространение методики фиксированного уровня значимости было вызвано сложностью вычисления многих статистических критериев в до компьютерную эпоху.