

gusev1[1]
.pdf§ 1. Область применения факторного анализа
Необходимость применения ФА в психологии как одного из методов многомерного количественного описания (измерения, анализа) наблюдаемых переменных в первую очередь следует из многомерности объектов, изучаемых нашей наукой. Сразу же определим, что под многомерным представлением объекта мы будем понимать результат его оценивания по нескольким различ- ным и существенным для его описания характеристи- кам-измерениям, т.е. присвоение ему сразу нескольких числовых значений. Из этого вполне естественно следуют два очень важных вопроса: насколько существенны и различны эти используемые характеристики. Первый вопрос связан с всесторонностью и полнотой описания объекта психологического измерения, а второй (в большей степени) — с выбором некоторого минимально разумного количества этих характеристик. Поясним сказанное выше на примере. Чем отличается хороший, профессионально сделанный психологический опросник от многочисленных “полупродуктов-полушу- ток”, во множестве публикуемых в периодической пе- чати для широкой публики или в книгах непрофессио- налов-дилетантов? Прежде всего тем, что в первом слу- чае объект психологического измерения (конструкт) описывается разносторонне и полно, и, кроме того, в нем не содержится лишних, не относящихся к делу (т.е. “не работающих” на ту или иную шкалу) вопросов. Таким образом, при использовании методов многомерных измерений психологических характеристик наиболее важны две проблемы — описать объект измерения всесторонне и, в тоже время, компактно. С известной долей обобщения можно сказать, что это одни из основных задач, решаемых ФА.
Понятно, что информативность многомерного описания объекта нашего изучения возрастает с увеличением количества используемых признаков или измерительных шкал. Однако очень трудно выбрать сразу и существенные, и независимые друг от друга характеристики. Этот
212
выбор порой непрост и долог. Как правило, исследователь начинает с заведомо избыточного количества признаков, и в процессе работы (например, по созданию нового опросника или анализу экспериментальных данных) сталкивается с необходимостью адекватной интерпретации большого объема полученных данных и их компактной визуализации. Анализируя полученные данные, исследователь замечает тот факт, что оценки изучаемого объекта, полученные по некоторым шкалам, сходны между собой, а если оценить это сходство количественно и подсчитать коэффициент корреляции, то он может оказаться достаточно высоким. Другими словами, возникает вопрос о том, что многие характеристики (т.е. переменные, по которым производилось измерение нашего объекта), вероятно, в некоторой степени дублируют друг друга, а вся полученная информация в целом избыточна. Внимательный исследователь, даже незнакомый с основами ФА, сразу же может сообразить, что за связанными друг с другом (коррелирующими) переменными, повидимому, стоит влияние некоторой скрытой, латентной переменной, с помощью которой можно объяснить наблюдаемое сходство полученных оценок. Очень часто эту гипотетическую латентную переменную называют фактором. Приблизительно такая логика заставила Чарлза Спирмена, психолога Оксфордского университета, в ходе анализа результатов тестирования способностей учеников английских школ предположить существование единого, генерального фактора интеллектуального развития
человека, влияющего на многочисленные показатели разнообразных интеллектуальных тестов. Таким образом, давно известный метод научного познания — обобщение, — приводит нас к возможности и необходимости выделения факторов как переменных более общего, более высокого порядка. Очень часто обобщение позволяет поновому взглянуть на полученные данные, заметить те связи между исходными характеристиками (переменными), которые ранее были не очевидны, а после этого выйти на более высокий уровень понимания сущности измеряемого объекта.
213
Такого рода обобщение (т.е. сокращение размерности полученных данных) дает возможность использовать очень мощное средство научного анализа — графическое представление полученных данных. Понятно, что сокращение размерности результатов многомерного измерения како- го-либо объекта до двух-трех позволит исследователю в очень наглядной и компактной форме представить весь объем полученных данных, выйдя за рамки логического анализа массы цифр, собранных в огромную таблицу. Имея в виду важное значение наглядно-образного мышления, трудно переоценить преимущества пространственного (графического) осмысления анализируемых данных. Таким образом, ФА может рассматриваться и как средство компактной визуализации данных.
Выделение в ходе анализа данных общего (для ряда переменных) фактора позволяет решать исследователю еще одну непростую задачу — оценивать некоторую скрытую от непосредственного наблюдения переменную (фактор) опосредованно, косвенно — через ее проявление (влияние) в ряде других, прямо измеряемых переменных. Подобным образом в психодиагностике личности были обнаружены, экстрагированы и измерены многие личностные конструкты, например: классический конструкт Айзенка импульсивность, оцениваемый в тесте EPI по ответам испытуемых на ряд вопросов, с разных сторон отражающих этот конструкт. Более того, ФА позволяет измерять не только прямо ненаблюдаемые (скрытые) переменные, но и оценивать определенные качества, которые могут намеренно скрываться и искажаться испытуемым при прямом их тестировании, однако проявляться (т.е. быть измеренными) косвенно через различные связанные с ними качества, оцениваемые прямо.
В ходе научного исследования ФА может выступать в двух ипостасях: как разведочный (эксплораторный) и как проверочный (конфирматорный) метод анализа данных. В первом случае ФА используется ex post factum, т.е. для анализа уже измеренных в эмпирическом исследовании переменных и, фактически, помогает исследователю их
214
структурировать; на этом этапе совсем не обязательно делать априорные предположения о количестве факторов и их связях с наблюдавшимися переменными. Здесь главное значение ФА — структурировать связи между переменными, помочь сформулировать рабочие гипотезы (пусть иногда и очень умозрительные) о причинах обнаруженных связей. Как правило, такое использование ФА характерно для начальной, ориентировочной стадии работы, когда многое неявное кажется явным, непростое — простым, и наоборот. В отличие от разведочного, конфирматорный ФА используется на более поздних стадиях исследования, когда в рамках какой-либо теории или модели сформулированы четкие гипотезы, связи между переменными и факторами достаточно определены, и исследователь их может прямо указать. Тогда конфирматорный ФА выступает как средство проверки соответствия сформулированной гипотезы полученным эмпирическим данным.
Обобщая вышесказанное, выделим основные цели использования ФА:
1.Понижение размерности числа используемых переменных за счет их объяснения меньшим числом факторов. Обобщение полученных данных.
2.Группировка, структурирование и компактная визуализация полученных данных.
3.Опосредованное, косвенное оценивание изучаемых переменных в случае невозможности или неудобства их прямого измерения.
4.Генерирование новых идей на этапе разведочного анализа. Оценка соответствия эмпирических данных используемой теории на этапе ее подтверждения.
§2. Исходные принципы и предположения
Основные общенаучные идеи, лежащие в основе ФА, достаточно просты и могут быть, по мнению П. Благуша (1989), сформулированы так:
а) “сущность вещей заключена в их простых и вместе с тем многообразных проявлениях, которые могут быть
215

объяснены с помощью комбинации нескольких основных факторов”, т.е. за наблюдаемой вариацией достаточно большого количества переменных стоит ограниченное число факторов;
б) “общую сущность наблюдаемых вещей мы постигаем, совершая бесконечные приближения к ней”, т.е. поиск факторов — это длительный процесс познания посредством перехода к факторам все более высокого порядка.
Первым основным формально-математическим принципом, лежащим в основе классической модели ФА1, является постулат о линейной зависимости между психологическими характеристиками (наблюдаемыми переменными), с помощью которых оценивается какой-либо объект. Количественно степень этой зависимости (связи) может быть оценена с помощью коэффициента корреляции. Второе основное предположение состоит в том, что эти наблюдаемые переменные (предполагается, что их заведомо избыточное количе- ство) могут быть представлены как линейная комбинация некоторых латентных переменных или факторов. Полагается, что ряд этих факторов являются общими для нескольких переменных, а другие, характерные факторы, специфическим образом связаны только с одной переменной. Поскольку последние ортогональны друг к другу, то, в отличие от общих факторов, они не вносят вклад в корреляцию (ковариацию)2 между переменными. Таким образом, математи- ческая модель ФА сходна с обычным уравнением множественной регрессии:
1 В данном параграфе мы излагаем наиболее традиционные принципы, лежащие в основе ФА, и принцип линейной зависимости, конечно же, — один из главных. Однако, следует отметить, что в последние годы разрабатываются модели ФА, основанные на более общем предположении — о нелинейной зависимости между наблюдаемыми переменными (Благуш, 1989).
2 Поскольку ФА работает как с ковариационными, так и с корреляционными матрицами переменных, то мы без особой необходимости не будем подчеркивать различия между ними.
216
Vi = Ai,1F1 + Ai,2F2 + ... + Ai,kFk + U, |
(1) |
ãäå Vi — значение i-й переменной, которое выражено в виде линейной комбинации k общих факторов, Ai,k — регрессионные коэффициенты, показывающие вклад каждого из k факторов в данную переменную; F1...k — факторы, общие для всех переменных; U — фактор, характерный только для переменной Vi .
Уравнение (1) выражает весьма простой смысл: каждая переменная может быть представлена в виде суммы вкладов каждого из общих факторов. С другой стороны, аналогичным образом, каждый из k факторов выражается в виде линейной комбинации наблюдаемых переменных:
Fj = Wj,1*V1 + Wj,2*V2 + ... +Wj,p*Vp, |
(2) |
ãäå Wj,i — нагрузки j-го фактора на i-ю переменную или факторные нагрузки; p — количество переменных.
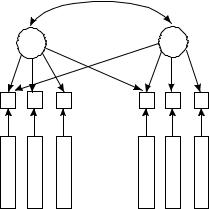
На рис. 1 факторные нагрузки (w1,1 ... w2,6) обозначены различными стрелками, показывающими влияние фактора на конкретную переменную. Переменные v1, v2 и v3 преимущественно связаны с фактором F1, и только фактор F2 имеет небольшую нагрузку на первую переменную; для других трех переменных (v4, v5, v6) общим фактором является F2, и лишь на четвертую переменную F1 имеет незначительную нагрузку. Эмпирические оценки наблюдаемых переменных v1 ... v6 представлены в столбцах a, b, c, d, e, f, соответственно. Дугообразная стрелка, соединяющая факторы и коэффициент корреляции над ней, подчеркивают факт ортогональности (некоррелированности, линейной независимости) этих факторов, хотя в общем случае (об этом ниже) это предположение критично лишь на этапе выделения первоначальных факторов, а в дальнейшем, на этапе интерпретации факторного решения, при вращении факторной структуры допускается возможность корреляции между факторами. (Это один из многих парадоксов ФА, связанный с многознач- ностью получаемого факторного решения, которое не имеет строго однозначного математического обоснования.)
Пользуясь схемой (рис. 1), еще раз обозначим основную задачу ФА: основываясь на эмпирических оценках
217
|
|
|
r(f1, f2) = 0 |
|
|
|
F1 |
w1,4 |
w2,1 |
F2 |
|
|
|
|
|
|
|
w1,1 |
w |
|
w2,4 |
w2,5 |
w2,6 |
|
w1,3 |
|
|
|
|
|
1,2 |
|
|
|
|
v1 |
v2 |
v3 |
v4 |
v5 |
v6 |
a1 |
b1 |
c1 |
d1 |
e1 |
f1 |
a2 |
b2 |
c2 |
d2 |
e2 |
f2 |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
. |
an |
bn |
cn |
dn |
en |
fn |
Рис.1. Гипотетическая модель с двумя общими факторами (F1 и F2) и шестью переменными (v1 ... v6)
(a, b, c, d,e, f) исследуемого объекта по каждой из шести переменных-харктеристик (v1 ... v6), исследователь пытается объяснить взаимосвязь наблюдаемых переменных влиянием 2-х общих факторов, в которых находят свое отражение эти переменные.
§3. Основные этапы факторного анализа
Âходе исследования с использованием разведочного ФА можно выделить три различных этапа: 1) сбор эмпирических данных и подготовка корреляционной (ковариационной) матрицы; 2) выделение первоначальных (ортогональных) факторов; 3) вращение факторной структуры и содержательная интерпретация результатов ФА. Остановимся на них подробнее.
1. Сбор эмпирических данных в психологическом исследовании разведочного плана всегда опосредован использованием какой-либо измерительной процедуры, в ходе которой испытуемый оценивает измеряемый объект (стимул) по ряду предложенных исследователем характерис-
218
тик. На этом этапе очень важно, чтобы исследователем был предложен достаточно большой набор характеристик, всесторонне описывающих измеряемый объект. Подбор важных и разнообразных характеристик и одновременно исключение лишних и несущественных — это достаточно трудное дело, требующее от исследователя опыта, знания литературы и, в известной степени, интуиции. Именно продуманный и удачный подбор оцениваемых характеристик определяет в конечном счете успех в выделении существенных и значимых факторов, стоящих за ними — это основное, о чем нельзя забывать на данном этапе. Иначе говоря, из случайного набора характеристик объекта невозможно выделить такие факторы, которые будут закономерно и содержательно определять его оценку испытуемыми. Понятно, что с первого раза, априорно бывает трудно подобрать нужные характеристики. Поэтому еще раз напомним, что разведочное исследование с помощью ФА — это длительный и интеративный процесс, когда результаты предыдущего анализа позволяют оценить допущенные ошибки и скорректировать процедуру последующего исследования.
Второе существенное замечание возникает в связи с постулатом линейности. В случае, когда связь между психологическими характеристиками оказывается существенно нелинейной, базисная размерность искомого факторного пространства возрастает, и это приводит к ложному решению. Преодоление этой трудности может идти двумя путями. Во-первых, можно использовать коэффициент криволинейной корреляции (по Пирсону, например), а во-вторых, следует избегать тех психологических переменных, которые имеют между собой явно нелинейные связи.
На данном этапе нельзя не коснуться вопроса о необходимом уровне измерения, поскольку он в первую оче- редь связан с использованием конкретного метода измерения. Вычислительные алгоритмы ФА требуют, чтобы измерения наблюдаемых переменных были проведены не ниже, чем по шкале интервалов. Это требование, к сожалению, выполняется далеко не всегда, что, впрочем, свя-
219
зано не столько с неосведомленностью исследователя, сколько с ограниченностью выбора измерительного метода и/или его адекватностью конкретной задаче или даже процедуре исследования. Реалии практики использования ФА в психологии таковы, что в подавляющем большинстве работ применяется один из вариантов метода балльной оценки, который, как известно, дает шкалу порядка. Налицо явное ограничение в использовании ФА. При решении данной проблемы следует иметь в виду следующее. Во-первых, стоит уделить максимальное внимание проработке процедурных моментов в использовании метода балльной оценки, чтобы выйти за установление только порядковых отношений и максимально “приблизиться” к шкале интервалов. Во-вторых, следует помнить, что математическая процедура ФА оказывается достаточно устой- чивой к разного рода измерительным некорректностям при оценке коэффициентов корреляции между переменными. И наконец, в самой математической статистике существуют различные подходы к решению данной проблемы (Дж. Ким, Ч. Мьюллер,1989), и для более качественной (не строго метрической) трактовки результатов ФА указанное ограничение приобретает не слишком принципиальное значение.
Достаточно важен вопрос о количестве используемых переменных или, более операционально, о том, сколько переменных должно приходиться на один гипотетический фактор. Вслед за Терстоуном многие авторы считают, что в разведочном ФА на один фактор должно приходиться не менее трех переменных. Для конфирматорного ФА эта пропорция меньше и, как правило, исследователи ограничиваются двумя переменными. Если исследователя интересует оценка надежности получаемых факторных нагрузок, существуют и более строгие оценки количества необходимых переменных (Дж. Ким, Ч. Мьюллер, 1989).
Формальный итог первого этапа — получение матрицы смешения и на ее основе — корреляционной матрицы.
Матрица смешения — это таблица, куда заносятся результаты измерения наблюдаемых переменных: в столбцах матрицы (по числу переменных) представлены оцен-
220
ки испытуемых (или одного испытуемого) каждой из переменной; строки матрицы — это различные наблюдения каждой переменной. Если задача исследователя — построить факторное пространство для одного испытуемого, то нужно обеспечить множественность таких наблюдений (например, повторить их несколько раз). В том случае, когда строится групповое факторное пространство, достаточно получить по одной оценке от каждого испытуемого. Для последующего расчета по этим данным корреляционной матрицы с достаточно достоверными коэффициентами корреляции следует обеспечить необходимое число наблюдений, т.е. количество строк в матрице смешения. Обычно не следует планировать менее 11—12 наблюдений.
Корреляционная матрица (матрица попарных корреляций между переменными) рассчитывается, как правило, с использованием коэффициента линейной корреляции Пирсона. Часто возникает вопрос о возможности и правомерности использовать другие меры сходства (сопряженнности) между переменными, основанные на ранговой (порядковой) статистике. Понятно, что данный вопрос возникает всегда, когда исследователь работает с номинальными или порядковыми данными. В строгом смысле ответ будет отрицательным. Однако следует принять во внимание два соображения. Во-первых, показано, что при достаточном числе наблюдений коэффициент линейной корреляции Пирсона достаточно устойчив к использованию при расчетах результатов порядковых измерений. Вовторых, как было отмечено выше, если перед исследователем стоит задача не столько количественного, сколько качественного анализа данных, то такое эвристическое использование ФА считается вполне оправданным.
Еще один тонкий вопрос, связанный с построением матрицы попарных корреляций связан с тем, какую матрицу использовать в ФА — корреляционную или ковариационную? Для начала напомним соответствующие формулы.
Коэффициент ковариации
221