

VII. Засоби Data Mining в Microsoft sql Server 2000
З можливостей, SQL Server 2000, що надаються, перш за все виділимонаступні:
· побудова і обробка моделей Data Mining;
· витягання даних як з реляційних, так і з багатовимірних джерел;
· два алгоритми здобування даних - Microsoft Decision Trees і Microsoft Clustering;
· розширення мови запитів до багатовимірних даних (MDX);
· робота із зовнішніми додатками через об'єктну модель DSO (Decision Support Objects).
Моделі
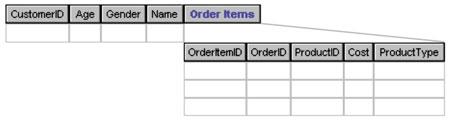
Моделі Data Mining - це основа витягання даних в SQL Server 2000. По суті модель є сукупність метаданих, що відображають деякі правила і закономірності в початкових даних. При цьому структура моделі визначає набір ключових атрибутів аналізу, тоді як її зміст несе безпосередньо статистичну інформацію - тут простежується схожість з ідеологією звичайних таблиць. Проте варто мати на увазі, що на основі одного і того ж набору початкових даних можна побудувати декілька різних моделей. У цьому сенсі побудова правильної моделі гарантує нам отримання саме тих “прихованих” даних, які ми прагнемо виявити. На рис. 12показана структура моделі, що містить дані про покупців магазина в розрізі товарів, щоїх придбають.
|
|
|
Рисунок 12. Структура моделі Data Mining
|
Процес побудови моделі реалізований в Analysis Services у вигляді майстра, що дозволяє крок за кроком задати параметри моделі і виконати її обробку, що, на думку розробників, спрощує проведення аналізу.
Вибір джерела даних
Перший крок в побудові моделі - вибір джерела даних для аналізу. Підтримуються два типи джерел даних: багатовимірні, використовувані в рамках технології OLAP (правда, поки як OLAP-джерело можна використовувати тільки сам модуль Analysis Services), і звичайні- реляційні. Наявність першого варіанту дає набагато більшу свободу вибору для аналізу, адже далеко не кожне підприємство має власне багатовимірне сховище даних.
Після вибору джерела можна приступати безпосередньо до формування структури моделі. Для цього потрібно визначити таблицю (або вимір, у разі багатовимірного джерела), що містить аналізовані дані, а також вибрати одне з полів таблиці (або показник багатовимірного куба), яке знаходитиметься у фокусі дослідження. Наприклад, якщо вам потрібно оцінити ризик кредиту для певних клієнтів банку, то величину цього ризику можна вибрати як предмет дослідження. Початковими даними для дослідження у такому разі можуть виступати дані про клієнта - вік, річний дохід, наявність автомобіля, місце проживання і т.п. Взагалі кажучи, вибір початкових даних і предмету аналізу - процес творчий, так що якщо не вдалося отримати необхідні оцінки відразу, то спробуйте змінити структуру моделі, ввівши в неї додаткові атрибути. Можливо, це дозволить оцінити ситуацію з іншої точки зору.
Вибір алгоритму аналізу
Наступний важливий крок - вибір одного з двох алгоритмів аналізу даних. Як вже зазначалось , Analysis Services підтримує два алгоритми - Microsoft Decision Trees і Microsoft Clustering. Оскільки області застосування і результати роботи кожного з них можуть сильно розрізнятися, на цьому кроці має сенс зупинитися докладніше. Алгоритм Microsoft Decision Trees заснований на відомому методі побудови дерев рішень. У його рамках значення кожного з досліджуваних атрибутів класифікується на основі значень решти атрибутів, з використанням правил вигляду “якщо -- то”. Результат роботи такого алгоритму - деревовидна структура, кожен вузол якої є якесьзапитання. Щоб вирішити, до якого класу віднести деякий об'єкт або ситуацію, потрібно відповісти на питання, що стоять у вузлах цього дерева, починаючи з його кореня (найбільш близький аналог такої структури - дерево видів в біології). Головна перевага цього алгоритму - наочність і простота використання. Проте область застосування "деревовидного" методу обмежена в основному завданнями класифікації Другий алгоритм, Microsoft Clustering, використовує інший, не менш відомий метод пошуку логічних закономірностей - метод “найближчого сусіда”. В процесі роботи алгоритму початкові дані об'єднуються в групи (кластери) на основі аналогічних або схожих значень атрибутів. Отримані набори даних аналізуються, що дозволяє виявити приховані закономірності або побудувати імовірносний прогноз. Даний алгоритм дозволяє провести глибший аналіз даних, чим дерево рішень, але і він має свої обмеження. Його переважно застосовуютьдля наборів данихіз схожими атрибутами, значення яких належать певному інтервалу (наприклад, вік, річний дохід і т. п.). Проте у разі нетипових значень атрибутів алгоритм може давати невірну оцінку. Вибір правильного алгоритму залежить від класу завдання, яке потрібно вирішити, а також від складу початкових даних. Задачі класифікації неоднорідних даних краще вирішувати за допомогою алгоритму дерев рішень, а завдання прогнозування або виявлення неявних закономірностей - за допомогою методу кластеризації. Який би алгоритм ви не вибрали, на цьому побудова моделі закінчена, і можна переходити до наступного процесу -тренування моделі.
Тренування побудованої моделі - це не що інше, як процес обробки початкових даних згідно вибраногоалгоритму. Цей процес може зайняти тривалий час, особливо при великих об'ємах даних. Після закінчення тренування початкові дані більше вам не знадобляться. В результаті тренування модель буде заповнена статистичними даними, які можуть бути представлені як в графічному, так і в цифровому вигляді.
Відображення результатів
Для відображення результатів аналізу використовуються вбудовані засоби Analysis Services. При цьому варіанти відображення різні для кожного з алгоритмів. Як приклад нижче приведені результати роботи алгоритму Microsoft Decision Trees.
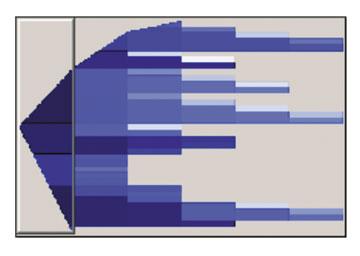
Рисунок 13. Дерево рішень.
Схема на рис.13показує всі гілки побудованого дерева рішень. Темнішим кольором виділені гілки, відповідні найбільшій вірогідності (числу попадань), а світлішим - найменшою. У даному прикладі гілок у дерева небагато, проте в деяких випадках їх число може досягати декількох сотень. Виділена частина дерева відображається в режимі детального перегляду (рис.14).
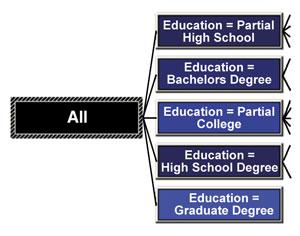
Рисунок 14. Вибрана частина дерева рішень
Будь-яку частину дерева рішень можна виділити для детального перегляду, але при цьому не можна проглядати більше двох рівнів одночасно. На збільшеній частині дерева можна бачити значення, привласнені кожному з вузлів в процесі роботи алгоритму. Як і в режимі проглядання всього дерева цілком, колір вузла тут сигналізує про кількість попадань початкових даних в цю гілку. Вибір певного вузла дерева дозволяє проглянути статистичну інформацію про даний вузол в числовому вигляді. Ця інформація включає значення вузла дерева, кількість значень початкових даних, що потрапили в дану гілку, і вірогідність попадання (рис.15).
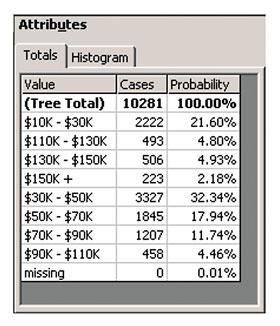
Рисунок 15. Інформація в числовій формі.
Отже, ми бачимо, що засоби витягання даних в SQL Server 2000 Analysis Services надають достатньо багатий набір функціональних можливостей для аналітиків і менеджерів підприємств. До того ж даний інструментарій відрізняється простотою у використанні і невисокою ціною, і, думається, він зможе знайти своїх користувачів в середовищі багатьохкомпаній.
VIII. Сфера застосування технологій інтелектуальних обчислень