

Формирование пуассоновской случайной величины
Для каждого абонента необходимо создать величину , означающая количество пакетов объёма 1 кбайт, поступающих в буфер БС для -ого АБ. В листинге 3 представлен программный код разработанного алгоритма, а на рисунке 4 – результат выполнения.
Листинг 3. Функция генерации входного потока заявок
def generate_P(lambda_, subs) -> pd.DataFrame: packs = pd.DataFrame( columns=subs.columns, data=[ np.random.poisson(lambda_, len(subs.columns)) for _ in range(len(subs.index)) ] ) return packs
generate_P(0.5, subs) |

Рисунок 4 – Входной поток заявок
Из рисунка 4 видна структура датафрейма, которая состоит из:
* Строки – номер абонента
* Столбцы – номер слота
* Ячейка – количество информационных пакетов
Расчет значений приоритета пользователей
Существует 3 подхода к распределению ресурсов, основанных на алгоритмах, рассмотренных в предыдущей работе. Но перед тем, как начинать рассматривать данные методы, необходимо ввести некоторые определения:
*
 – средняя скорость загрузки данных
-ым
АБ к
-ому
слоту;
– средняя скорость загрузки данных
-ым
АБ к
-ому
слоту;
*
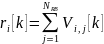 - объем данных переданных
-ому
абоненту, если все ресурсы уйдут к
-ому;
- объем данных переданных
-ому
абоненту, если все ресурсы уйдут к
-ому;
*
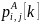 - приоритет
-ого
абонента на
-ый
ресурсный блок в
-ом
слоте.
- приоритет
-ого
абонента на
-ый
ресурсный блок в
-ом
слоте.
Equal Blind
Данный алгоритм приравнивает среднюю скорость загрузки. Приоритет пользователя определяется следующим образом:
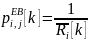
Как и во всех
последующих алгоритмах, ресурсный блок
отдаётся тому пользователю, у которого
наибольший приоритет:
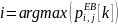 .
Далее, в листинге 4, следует реализация
данного метода в виде функции:
.
Далее, в листинге 4, следует реализация
данного метода в виде функции:
Листинг 4. Метод распределения Equal Blind
def priority_EB(subs_R_mean: list) -> NDArray[intp]: # Расчет приоритетов и возвращение максимального subs_priority = [1 / R_i if R_i > 0 else 1 for R_i in subs_R_mean]
# Получаем список отсортированных индексов АБ по приоритету subs_priority_ids = np.argsort(subs_priority)
return subs_priority_ids |
Maximum Throughput
Алгоритм "отдаёт" ресурсный блок тому пользователю, у которого максимальна пропускная способность канала связи:

Далее, в листинге 5, следует реализация данного метода в виде функции:
Листинг 5. Метод распределения Maximum Throughput
def priority_MT(subs_chanel_capacity: list)-> NDArray[intp]: # Получаем список отсортированных индексов АБ по приоритету subs_priority_ids = np.argsort(subs_chanel_capacity)
return subs_priority_ids |
Proportional Fair
Алгоритм выравнивания ресурсов, отдаваемых пользователям. Приоритет -ого пользователя на ресурсный блок определяется как:
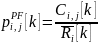
Далее, в листинге 6, следует реализация данного метода в виде функции:
Листинг 6. Метод распределения Proportional Fair
def priority_PF(subs_chanel_capacity: list, subs_R_mean: list)-> NDArray[intp]: # Расчет приоритетов и возвращение максимального subs_priority = [C_i / (R_i if R_i > 0 else 1) for C_i, R_i in zip(subs_chanel_capacity, subs_R_mean)]
# Получаем список отсортированных индексов АБ по приоритету subs_priority_ids = np.argsort(subs_priority)
return subs_priority_ids |