11.4. Архитектура Transformer 423
сравнивается.с.самой.собой,.чтобы.обогатить.каждый.токен.контекстом.из.всей. последовательности.
Это.объясняет,.почему.потребовалось.передать.inputs.слою.MultiHeadAttention . в.трех.параметрах..Но.почему.внимание.многоголовое.(multi-head)?
11.4.2. Многоголовое внимание
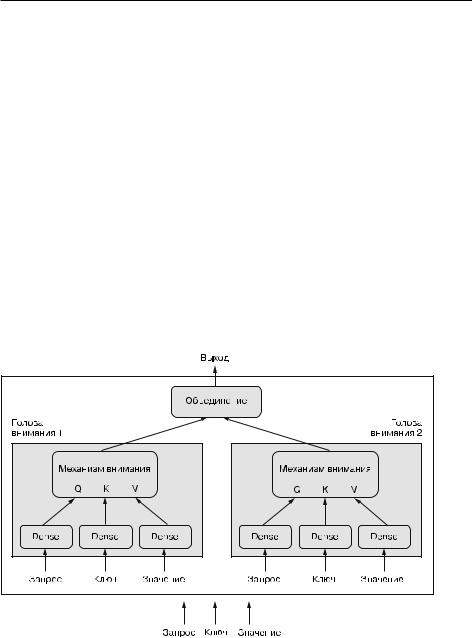
Многоголовое.внимание.(multi-head.attention).—.это.дополнительная.настрой- ка.механизма.внутреннего.внимания,.представленного.в.статье.Attention.is.all. you.need..Под.многоголовостью.подразумевается.разделение.выходного.пространства.слоя.внутреннего.внимания.на.набор.независимых.подпространств,. обучаемых.отдельно:.исходный.запрос,.ключ.и.значение.передаются.через.три. независимых.набора.плотных.проекций,.в.результате.чего.получается.три.отдельных.вектора..Каждый.вектор.обрабатывается.с.привлечением.механизма. нейронного.внимания,.после.чего.три.выхода.снова.объединяются.в.единую. выходную.последовательность..Каждое.такое.подпространство.называется. головой..Полная.картина.процесса.показана.на.рис..11.8.
Рис. 11.8. Слой MultiHeadAttention |
Наличие.обучаемых.плотных.проекций.позволяет.слою.действительно.чему-то. учиться.—.в.отличие.от.преобразования.без.сохранения.состояния,.для.которого.
424 Глава 11. Глубокое обучение для текста
требуются.дополнительные.слои,.расположенные.до.или.после.него,.чтобы. преобразование.приносило.пользу..Кроме.того,.наличие.независимых.голов. помогает.слою.изучать.разные.группы.признаков.для.каждого.токена,.где.признаки.в.одной.группе.коррелируют.друг.с.другом,.но.практически.не.зависят.от. признаков.в.другой.группе.
В.принципе,.это.похоже.на.то,.как.работают.свертки.с.разделением.по.глубине:. в.такой.свертке.выходное.пространство.разбивается.на.множество.подпространств.(по.одному.для.каждого.входного.канала),.изучаемых.независимо.. Статья.Attention.is.all.you.need.была.написана.в.ту.пору,.когда.на.практике.было. показано,.что.идея.деления.пространств.признаков.на.независимые.подпро- странства.дает.существенные.преимущества.моделям.компьютерного.зрения.—. как.в.случае.сверток.с.разделением.по.глубине,.так.и.в.случае.близких.к.ним. сгруппированных сверток..Многоголовое.внимание.—.это.просто.применение. той.же.идеи.к.внутреннему.вниманию.
11.4.3. Кодировщик Transformer
Если.добавление.дополнительных.плотных. проекций.так.полезно,.то.почему.бы.не.применить.еще.пару.к.выходу.механизма.внимания?. На.самом.деле.это.отличная.идея.—.давайте. так.и.поступим..Теперь.модель.стала.довольно. глубокой,.поэтому.можно.добавить.остаточные.связи,.чтобы.не.уничтожить.ценную.ин- формацию.в.процессе.обработки,.—.как.вы.уз- нали.в.главе.9,.остаточные.связи.необходимы. в.любой.глубокой.архитектуре..Кроме.этого,. из.главы.9.вы.должны.помнить.следующее:. . предполагается,.что.слои.нормализации.способствуют.передаче.градиентов.во.время.обратного.распространения..Добавим.и.их.
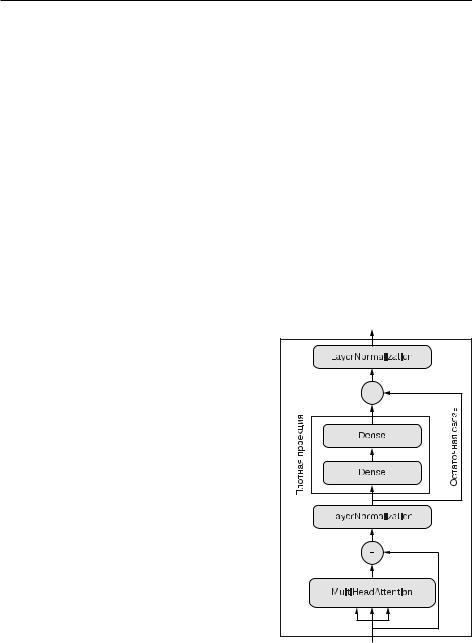
Примерно.такой.мыслительный.процесс,.как. мне.представляется,.развернулся.в.свое.время. в.умах.изобретателей.архитектуры.Transformer.. Разделение.выходных.данных.по.нескольким. независимым.пространствам,.добавление.оста- точных.связей.и.слоев.нормализации.—.все.это. стандартные.архитектурные.шаблоны,.которые.разумно.использовать.в.любой.сложной. модели..Все.вместе.они.образуют.кодировщик Transformer.—.одну.из.двух.важнейших.частей. архитектуры.Transformer. .(рис..11.9).
Рис. 11.9. TransformerEncoder |
объединяет слой |
MultiHeadAttention с плотной |
проекцией, а также добавляет |
нормализацию и остаточные связи |

11.4. Архитектура Transformer 425
Оригинальная .архитектура .Transformer .состоит .из .двух .частей: .кодиров щика Transformer,.обрабатывающего.входную.последовательность,.и.декодера Transformer, .использующего .входную .последовательность .для .создания. преобразованной .версии. .С .устройством .декодера .вы .познакомитесь .чуть. ниже.
Важно.отметить,.что.кодировщик.можно.использовать.для.классификации. текста.—.это.универсальный.модуль,.который.принимает.последовательность. и.учится.преобразовывать.ее.в.более.полезное.представление..Давайте.реализуем.кодировщик.Transformer.и.опробуем.его.на.задаче.классификации.обзоров. фильмов.
Листинг 11.21. Кодировщик Transformer реализован как подкласс класса Layer
import tensorflow as tf from tensorflow import keras
from tensorflow.keras import layers
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs) |
|
|
|
|
|
self.embed_dim = embed_dim |
|
|
|
|
Размер входного вектора токенов |
|
|
|
self.dense_dim = dense_dim |
|
|
|
|
Размер внутреннего полносвязного слоя |
|
|
|
|
self.num_heads = num_heads |
|
|
|
Количество голов внимания |
|
|
self.attention = layers.MultiHeadAttention( |
|
num_heads=num_heads, key_dim=embed_dim) |
|
self.dense_proj = keras.Sequential( |
|
|
|
|
|
[layers.Dense(dense_dim, activation="relu"), |
layers.Dense(embed_dim),] |
|
|
|
|
|
) |
|
|
|
|
|
|
|
|
|
self.layernorm_1 = layers.LayerNormalization() |
self.layernorm_2 = layers.LayerNormalization() |
def call(self, inputs, mask=None): |
|
|
|
|
Вычисления выполняются в методе call() |
|
|
|
|
|
|
|
|
|
Маска, слой Embedding сгенерирует |
|
|
|
|
|
|
|
|
|
if mask is not None: |
|
|
|
|
|
|
|
|
двумерную маску, но слой внимания |
mask = mask[:, tf.newaxis, :] |
|
|
|
|
|
|
|
|
должен быть трехили четырехмерным, |
attention_output = self.attention( |
|
|
|
|
|
|
|
|
поэтому мы увеличиваем ранг |
inputs, inputs, attention_mask=mask) |
|
|
proj_input = self.layernorm_1(inputs + attention_output) |
proj_output = self.dense_proj(proj_input) |
|
return self.layernorm_2(proj_input + proj_output) |
def get_config(self): config = super().get_config() config.update({
"embed_dim": self.embed_dim, "num_heads": self.num_heads, "dense_dim": self.dense_dim,
})
return config
Реализует сериализацию, чтобы дать возможность сохранить модель
426 Глава 11. Глубокое обучение для текста
СОХРАНЕНИЕ НЕСТАНДАРТНЫХ СЛОЕВ
При создании своих слоев обязательно реализуйте метод get_config: это позволяет восстановить слой из его конфигурационного словаря, что пригодится при сохранении и загрузке модели. Метод должен возвращать словарь Python со значениями аргументов конструктора, использовавшихся для создания слоя.
Все слои Keras можно сериализовать и десериализовать, как показано ниже:
config = layer.get_config()
new_layer = layer.__class__.from_config(config) 
Конфигурация не содержит значений весов, поэтому все веса в слое инициализируются с нуля
Например:
layer = PositionalEmbedding(sequence_length, input_dim, output_dim) config = layer.get_config()
new_layer = PositionalEmbedding.from_config(config)
При сохранении модели с нестандартными слоями файл будет содержать эти конфигурационные словари. При загрузке модели из файла вы должны передать нестандартные классы слоев методу загрузки, чтобы он мог правильно воссоздать объекты, упомянутые в конфигурации:
model = keras.models.load_model(
filename, custom_objects={"PositionalEmbedding": PositionalEmbedding})
Обратите.внимание,.что.здесь.для.нормализации.применяются.слои,.отличные. от.BatchNormalization,.которые.мы.использовали.в.моделях.обработки.изображений..Причина.в.том,.что.BatchNormalization.плохо.работает.с.последовательностями..Поэтому.в.данном.случае.берется.слой.LayerNormalization,.который. нормализует.каждую.последовательность.независимо.от.других.последователь- ностей.в.пакете,.как.показано.в.NumPy-подобном.псевдокоде:
Входные данные имеют форму (размер_пакета, длина_последовательности, размерность_векторного_представления)
def layer_normalization(batch_of_sequences):
mean = np.mean(batch_of_sequences, keepdims=True, axis=-1) variance = np.var(batch_of_sequences, keepdims=True, axis=-1 return (batch_of_sequences - mean) / variance
Для вычисления среднего и дисперсии мы объединяем данные только по последней оси (–1)
Поскольку TransformerEncoder возвращает полные последовательности, мы должны сократить каждую последовательность до одного
вектора, который можно передать в глобальный слой объединения для классификации
Данные объединяются по оси пакетов (0), что обусловливает взаимовлияние образцов в пакете
11.4. Архитектура Transformer 427
Сравните.с.тем,.как.действует.слой.BatchNormalization .(на.этапе.обучения):
Входные данные имеют форму (размер_пакета, высота, ширина, каналы)
def batch_normalization(batch_of_images):
mean = np.mean(batch_of_images, keepdims=True, axis=(0, 1, 2)) variance = np.var(batch_of_images, keepdims=True, axis=(0, 1, 2)) return (batch_of_images - mean) / variance
В.отличие.от.слоя.BatchNormalization,.который.собирает.информацию.по.множеству.образцов,.чтобы.получить.точные.значения.среднего.и.дисперсии.признаков,.слой.LayerNormalization .объединяет.данные.по.последовательностям. и.лучше.подходит.для.их.обработки.
Теперь,.реализовав.TransformerEncoder,.используем.его.для.сборки.модели.классификации.текста,.похожей.на.модель.на.основе.GRU,.которую.вы.видели.ранее.
Листинг 11.22. Использование кодировщика Transformer для классификации текста
vocab_size = 20000 embed_dim = 256 num_heads = 2 dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64") x = layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x) x = layers.GlobalMaxPooling1D()(x) 
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs, outputs) model.compile(optimizer="rmsprop",
loss="binary_crossentropy", metrics=["accuracy"])
model.summary()
Обучим.получившуюся.модель..Она.достигла.точности.87,5.%.—.чуть.хуже. модели.GRU.
Листинг 11.23. Обучение и оценка модели на основе кодировщика Transformer
callbacks = [ keras.callbacks.ModelCheckpoint("transformer_encoder.keras", save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20,
callbacks=callbacks) |
Передать нестандартный класс |
|
|
model = keras.models.load_model( |
|
TransformerEncoder методу загрузки модели |
|
"transformer_encoder.keras", |
|
|
|
|
custom_objects={"TransformerEncoder": TransformerEncoder}) |
|
|
|
|
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}") |
428 Глава 11. Глубокое обучение для текста
Сейчас.у.вас.должно.появиться.чувство.тревоги:.что-то.явно.пошло.не.так.. Сможете.ли.вы.определить,.что.именно?
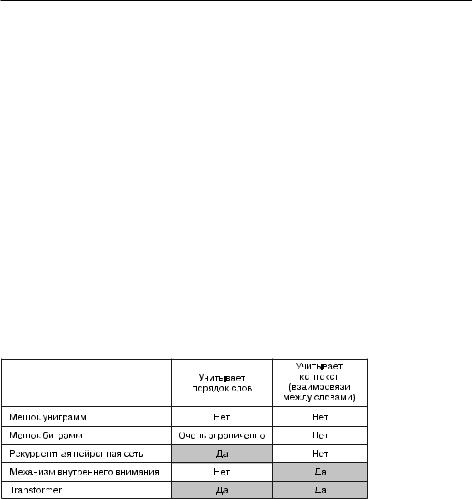
Данный.раздел.посвящен.моделям.последовательностей..В.самом.начале.я.под- черкнул.важность.порядка.слов.и.заявил,.что.Transformer.—.это.архитектура. обработки.последовательностей,.изначально.разработанная.для.машинного. перевода..И.вместе.с.тем....кодировщик.Transformer,.который.вы.только.что.видели.в.действии,.вообще.не.является.моделью.последовательностей..Заметили. это?.Он.состоит.из.полносвязных.слоев,.обрабатывающих.последовательности. токенов.независимо.друг.от.друга,.и.слоя.внимания,.который.рассматривает. токены.как множество..Изменив.порядок.токенов.в.последовательности,.вы.получите.точно.такие.же.попарные.оценки.внимания.и.точно.такие.же.контекстно. зависимые.представления..Даже.если.перемешать.все.слова.в.каждом.обзоре. фильма,.модель.этого.не.распознает.и.вы.все.равно.получите.ту.же.самую.точ- ность..Внутреннее.внимание.—.это.механизм.обработки.множеств,.сосредоточен- ный.на.отношениях.между.парами.элементов.последовательности.(рис..11.10).. Он.никак.не.учитывает.места,.где.встречаются.эти.элементы:.в.начале,.в.конце. или.в.середине.последовательности..Так.почему.же.мы.называем.архитектуру. Transformer.моделью.последовательности?.И.как.она.может.использоваться.для. машинного.перевода,.если.не.учитывает.порядок.слов?
Рис. 11.10. Свойства разных типов моделей обработки естественного языка
Выше.я.мимоходом.подсказывал.решение,.упомянув,.что.Transformer.—.это. гибридный.подход,.который.технически.не.учитывает.порядка.элементов.последовательностей,.но.позволяет.вручную.ввести.информацию.о.порядке.в.обрабатываемые.представления..Данный.недостающий.ингредиент.называется. позиционным кодированием..Давайте.рассмотрим.его.
Использование позиционного кодирования для внедрения информации о порядке
Идея.позиционного.кодирования.проста:.чтобы.модель.могла.получить.информацию.о.порядке.слов,.мы.добавим.в.каждое.векторное.представление.каждого. слова.его.позицию.в.предложении..Наши.входные.векторные.представления.слов.
Объединим два вектора представлений
А другой — для обработки
позиций токенов
Подготовим один слой Embedding для обработки индексов токенов
11.4. Архитектура Transformer 429
будут.состоять.из.двух.компонентов:.обычного.вектора,.представляющего.слово. независимо.от.конкретного.контекста,.и.вектора,.представляющего.положение. слова.в.текущем.предложении..Будем.надеяться,.что.модель.поймет,.как.лучше. использовать.это.дополнение.
Самая.простая.схема,.которую.можно.придумать,.—.соединить.позицию.слова. с.его.векторным.представлением,.добавив.в.вектор.ось.«положения».и.заполнив. ее.нулями.для.первого.слова,.единицами.—.для.второго.и.т..д.
Однако.это.не.наилучшее.решение,.поскольку.позиции.могут.быть.очень.большими.целыми.числами,.выходящими.за.границы.диапазона.значений.в.векторе. представления..Как.вы.уже.знаете,.нейронные.сети.не.любят.огромных.входных. значений.или.дискретных.распределений.
В.статье.Attention is all you need.для.кодирования.позиций.слов.предлагался. интересный.прием:.к.векторным.представлениям.слов.добавлялся.вектор.со. значениями.в.диапазоне.[-1, 1],.которые.циклически.менялись.в.зависимости. от.позиции.(для.этого.использовалась.функция.косинуса)..Данный.трюк.позволяет.однозначно.охарактеризовать.любое.целое.число.в.большом.диапазоне. с.помощью.вектора.малых.значений..Любопытное.решение,.но.в.нашем.случае. мы.к.нему.не.прибегнем..Мы.поступим.проще.и.эффективнее:.будем.конструировать.векторы.представления.позиций.точно.так.же,.как.конструируем.индексы. векторных.представлений.слов..После.этого.мы.добавим.представления.позиций. к.соответствующим.представлениям.слов,.чтобы.получить.векторные.представления.слов.с.учетом.их.положения..Данный.метод.называется.векторным. представлением.позиций..Давайте.реализуем.это.решение.
Листинг 11.24. Реализация векторного представления позиций в подклассе слоя
Недостаток подхода с использованием векторных представлений позиций — в необходимости заранее знать длину последовательности
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):  super().__init__(**kwargs)
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding( input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding( input_dim=sequence_length, output_dim=output_dim) 
self.sequence_length = sequence_length self.input_dim = input_dim self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1) embedded_tokens = self.token_embeddings(inputs) embedded_positions = self.position_embeddings(positions) return embedded_tokens + embedded_positions 
430 Глава 11. Глубокое обучение для текста
|
|
def |
compute_mask(self, inputs, mask=None): |
|
Так же как слой Embedding, этот слой |
|
|
|
|
return tf.math.not_equal(inputs, 0) |
|
должен уметь генерировать маску, |
|
|
|
|
|
|
|
|
|
|
чтобы дать возможность игнорировать |
|
|
def |
get_config(self): |
|
дополнение входных данных нулями. |
|
|
|
config = super().get_config() |
|
Фреймворк автоматически вызовет |
|
|
|
|
метод calculate_mask, и полученная |
|
Реализует |
config.update({ |
|
|
|
маска будет передана следующему слою |
|
|
"output_dim": self.output_dim, |
|
|
сериализацию, |
|
|
|
чтобы дать |
|
"sequence_length": self.sequence_length, |
|
возможность |
|
"input_dim": self.input_dim, |
|
|
|
сохранить |
}) |
|
|
|
|
модель |
return config |
|
|
|
|
|
Cлой.PositionEmbedding.можно.использовать.так.же,.как.обычный.слой.Embedding.. Посмотрим.на.него.в.действии!
Классификация с использованием кодировщика Transformer
Чтобы.начать.учитывать.порядок.слов,.нужно.заменить.старый.слой.Embedding . нашей.версией,.отслеживающей.их.положение.
Листинг 11.25. Объединение кодировщика Transformer с векторным представлением позиций
vocab_size = 20000 sequence_length = 600 embed_dim = 256 num_heads = 2 dense_dim = 32
Смотрите сюда!
inputs = keras.Input(shape=(None,), dtype="int64")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs) x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x) x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs, outputs) model.compile(optimizer="rmsprop",
loss="binary_crossentropy", metrics=["accuracy"])
model.summary()
callbacks = [ keras.callbacks.ModelCheckpoint("full_transformer_encoder.keras", save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20, callbacks=callbacks)
model = keras.models.load_model( "full_transformer_encoder.keras", custom_objects={"TransformerEncoder": TransformerEncoder,
"PositionalEmbedding": PositionalEmbedding}) print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")