

В 60-х годах XX века в американском национальном институте стандартизации (ANSI)была разработана таблица кодирования символов, которая впоследствии была использована во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange – американский стандартный код для обмена информацией). Чуть позже появилась расширенная версия ASCII.
В соответствие с таблицей кодирования ASCII для представления одного символа выделяется 1 байт (8 бит). Набор из 8 ячеек может принять 28 = 256 различных значений. Первые 128 значений (от 0 до 127) постоянны и формируют так называемую основную часть таблицы, куда входят десятичные цифры, буквы латинского алфавита (заглавные и строчные), знаки препинания (точка, запятая, скобки и др.), а также пробел и различные служебные символы (табуляция, перевод строки и др.). Значения от 128 до 255 формируют дополнительную часть таблицы, где принято кодировать символы национальных алфавитов.
Поскольку национальных алфавитов огромное множество, то расширенные ASCII-таблицы существуют во множестве вариантов. Даже для русского языка существуют несколько таблиц кодирования (распространены Windows-1251 и Koi8-r). Все это создает дополнительные трудности. Например, мы отправляем письмо, написанное в одной кодировке, а получатель пытается прочитать ее в другой. В результате видит кракозябры. Поэтому читающему требуется применить для текста другую таблицу кодирования.
Есть и другая проблема. В алфавитах некоторых языков слишком много символов и они не помещаются в отведенные им позиции с 128 до 255 однобайтовой кодировки.
Третья проблема - что делать, если в тексте используется несколько языков (например, русский, английский и французский)? Нельзя же использовать две таблицы сразу …
Чтобы решить эти проблемы одним разом была разработана кодировка Unicode.
Стандарт кодирования символов Unicode
Для решения вышеизложенных проблем в начале 90-х был разработан стандарт кодирования символов, получивший название Unicode. Данный стандарт позволяет использовать в тексте почти любые языки и символы.
В Unicode первые 128 кодов совпадают с таблицей ASCII.
|
|
.0 |
.1 |
.2 |
.3 |
.4 |
.5 |
.6 |
.7 |
.8 |
.9 |
.A |
.B |
.C |
.D |
.E |
.F |
|
0. |
NUL |
SOH |
STX |
ETX |
EOT |
ENQ |
ACK |
BEL |
BS |
TAB |
LF |
VT |
FF |
CR |
SO |
SI |
|
1. |
DLE |
DC1 |
DC2 |
DC3 |
DC4 |
NAK |
SYN |
ETB |
CAN |
EM |
SUB |
ESC |
FS |
GS |
RS |
US |
|
2. |
|
! |
" |
# |
$ |
% |
& |
' |
( |
) |
* |
+ |
, |
— |
. |
/ |
|
3. |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
< |
= |
> |
? |
|
4. |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
|
5. |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\ |
] |
^ |
_ |
|
6. |
` |
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
|
7. |
p |
q |
r |
s |
t |
u |
v |
w |
x |
y |
z |
{ |
| |
} |
~ |
DEL |
В Unicode для кодирования символов предоставляется 31 бит (4 байта за вычетом одного бита). Количество возможных комбинаций дает запредельное число: 231 = 2 147 483 684 (т.е. более двух миллиардов). Поэтому Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и иные специальные символы. Однако информационная емкость 31-битового Unicode все равно остается слишком большой. Поэтому чаще используется сокращенная 16-битовая версия (216 = 65 536 значений), где кодируются все современные алфавиты.
Поскольку ASCII изначально предназначался для обмена информацией (по телетайпу), в нём, кроме информационных символов, используются символы-команды для управления связью. Это обычный набор спецсигналов, применявшийся и в других докомпьютерных средствах обмена сообщениями (азбука Морзе, семафорная азбука), дополненный с учётом специфики устройства.
(После названия каждого символа указан его 16-ричный код)
-
NUL, 00 — Null, пустой. Всегда игнорировался. На перфолентах 1 представлялась дырочкой, 0 — отсутствием дырочки. Поэтому пустые части перфоленты до начала и после конца сообщения состояли из таких символов. Сейчас используется во многих языках программирования как конец строки. (Строка понимается как последовательность символов.) В некоторых операционных системах NUL — последний символ любого текстового файла.
-
SOH, 01 — Start Of Heading, начало заголовка.
-
STX, 02 — Start of Text, начало текста. Текстом называлась часть сообщения, предназначенная для печати. Адрес, контрольная сумма и т. д. входили или в заголовок, или в часть сообщения после текста.
-
ETX, 03 — End of Text, конец текста. Здесь телетайп прекращал печатать. Использование символа Ctrl-C, имеющего код 03, для прекращения работы чего-то (обычно программы), восходит ещё к тем временам.
-
EOT, 04 — End of Transmission, конец передачи. В системе UNIX Ctrl-D, имеющий тот же код, означает конец файла при вводе с клавиатуры.
-
ENQ, 05 — Enquire. Прошу подтверждения.
-
ACK, 06 — Acknowledgement. Подтверждаю.
-
BEL, 07 — Bell, звонок, звуковой сигнал. Сейчас тоже используется. В языках программирования C и C++ обозначается \a.
-
BS, 08 — Backspace, возврат на один символ. Сейчас стирает предыдущий символ.
-
TAB, 09 — Tabulation. Обозначался также HT — Horizontal Tabulation, горизонтальная табуляция. Во многих языках программирования обозначается \t .
-
LF, 0A — Line Feed, перевод строки. Сейчас в конце каждой строчки текстового файла ставится либо этот символ, либо CR, либо и тот и другой (CR, затем LF), в зависимости от операционной системы. Во многих языках программирования обозначается \n и при выводе текста приводит к переводу строки.
-
VT, 0B — Vertical Tab, вертикальная табуляция.
-
FF, 0C — Form Feed, новая страница.
-
CR, 0D — Carriage Return, возврат каретки. Во многих языках программирования этот символ, обозначаемый \r, можно использовать для возврата в начало строчки без перевода строки. В некоторых операционных системах этот же символ, обозначаемый Ctrl-M, ставится в конце каждой строчки текстового файла перед LF.
-
SO, 0E — Shift Out, измени цвет ленты (использовался для двуцветных лент; цвет менялся обычно на красный). В дальнейшем обозначал начало использования национальной кодировки.
-
SI, 0F — Shift In, обратно к Shift Out.
-
DLE, 10 — Data Link Escape, следующие символы имеют специальный смысл.
-
DC1, 11 — Device Control 1, 1-й символ управления устройством — включить устройство чтения перфоленты.
-
DC2, 12 — Device Control 2, 2-й символ управления устройством — включить перфоратор.
-
DC3, 13 — Device Control 3, 3-й символ управления устройством — выключить устройство чтения перфоленты.
-
DC4, 14 — Device Control 4, 4-й символ управления устройством — выключить перфоратор.
-
NAK, 15 — Negative Acknowledgment, не подтверждаю. Обратно к Acknowledgment.
-
SYN, 16 — Synchronization. Этот символ передавался, когда для синхронизации было необходимо что-нибудь передать.
-
ETB, 17 — End of Text Block, конец текстового блока. Иногда текст по техническим причинам разбивался на блоки.
-
CAN, 18 — Cancel, отмена (того, что было передано ранее).
-
EM, 19 — End of Medium, кончилась перфолента и т. д.
-
SUB, 1A — Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче. Сейчас Ctrl-Z используется как конец файла при вводе с клавиатуры в системах DOS и Windows. У этой функции нет никакой очевидной связи с символом SUB.
-
ESC, 1B — Escape. Следующие символы — что-то специальное.
-
FS, 1C — File Separator, разделитель файлов.
-
GS, 1D — Group Separator, разделитель групп.
-
RS, 1E — Record Separator, разделитель записей.
-
US, 1F — Unit Separator, разделитель юнитов. То есть поддерживалось 4 уровня структуризации данных: сообщение могло состоять из файлов, файлы из групп, группы из записей, записи из юнитов.
-
DEL, 7F — Delete, стереть последний символ. Символом DEL, состоящим в двоичном коде из всех единиц, можно было забить любой символ. Устройства и программы игнорировали DEL так же, как NUL. Код этого символа происходит из первых текстовых процессоров с памятью на перфоленте: в них удаление символа происходило забиванием его кода дырочками (обозначавшими логические единицы).
Сигнал (в теории информации и связи) — материальный носитель информации, используемый для передачи сообщений в системе связи.
Классификация сигналов
По физической природе носителя информации:
-
электрические;
-
электромагнитные;
-
оптические;
-
акустические
и др.;
По способу задания сигнала:
-
регулярные (детерминированные), заданные аналитической функцией;
-
нерегулярные (случайные), принимающие произвольные значения в любой момент времени. Для описания таких сигналов используется аппарат теории вероятностей.
В зависимости от функции, описывающей параметры сигнала, выделяют аналоговые, дискретные, квантованные и цифровые сигналы:
-
непрерывные (аналоговые), описываемые непрерывной функцией;
-
дискретные, описываемые функцией отсчётов, взятых в определённые моменты времени;
-
квантованные по уровню;
-
дискретные сигналы, квантованные по уровню (цифровые).
Дискретный сигнал
Дискретизация аналогового сигнала состоит в том, что сигнал представляется в виде последовательности значений, взятых в дискретные моменты времени. Эти значения называются отсчётами. Δt называется интервалом дискретизации.
Дискретизация — преобразование непрерывной функции в дискретную.
Используется в гибридных вычислительных системах и цифровых устройствах при импульсно-кодовой модуляции сигналов в системах передачи данных. При передаче изображения используют для преобразования непрерывного аналогового сигнала в дискретный или дискретно-непрерывный сигнал.
Обратный процесс называется восстановлением. При дискретизации только по времени, непрерывный аналоговый сигнал заменяется последовательностью отсчётов, величина которых может быть равна значению сигнала в данный момент времени. Возможность точного воспроизведения такого представления зависит от интервала времени между отсчётами Δt.
Согласно теореме Котельникова:
![]() где
где ![]() —
наибольшая частота спектра сигнала.
—
наибольшая частота спектра сигнала.
Теоре́ма
Коте́льникова (в
англоязычной литературе — теорема
Найквиста — Шеннона или
теорема отсчётов) гласит, что,
если аналоговый
сигнал ![]() имеет
ограниченный спектр,
то он может быть восстановлен однозначно
и без потерь по своим дискретным отсчётам,
взятым с частотой строго
большей удвоенной
верхней частоты
имеет
ограниченный спектр,
то он может быть восстановлен однозначно
и без потерь по своим дискретным отсчётам,
взятым с частотой строго
большей удвоенной
верхней частоты![]()
Если максимальная частота в сигнале превышает половину частоты дискретизации, то способа восстановить сигнал из дискретного в аналоговый без искажений не существует.
Квантованный сигнал
При квантовании вся область значений сигнала разбивается на уровни, количество которых должно быть представлено в числах заданной разрядности. Расстояния между этими уровнями называется шагом квантования Δ. Число этих уровней равно N (от 0 до N-1). Каждому уровню присваивается некоторое число. Отсчёты сигнала сравниваются с уровнями квантования и в качестве сигнала выбирается число, соответствующее некоторому уровню квантования. Каждый уровень квантования кодируется двоичным числом с n разрядами. Число уровней квантования N и число разрядов n двоичных чисел, кодирующих эти уровни, связаны соотношением n ≥ log2(N).
Квантование (англ. quantization) — в информатике разбиение диапазона значений непрерывной или дискретной величины на конечное число интервалов.
Цифровой сигнал
Для того, чтобы представить аналоговый сигнал последовательностью чисел конечной разрядности, его следует сначала превратить в дискретный сигнал, а затем подвергнуть квантованию. Квантование является частным случаем дискретизации, когда дискретизация происходит по одинаковой величине называемой квантом. В результате сигнал будет представлен таким образом, что на каждом заданном промежутке времени известно приближённое (квантованное) значение сигнала, которое можно записать целым числом. Если записать эти целые числа в двоичной системе, получится последовательность нулей и единиц, которая и будет являться цифровым сигналом.
Звуковая карта (звуковая плата, аудиокарта; англ. sound card) — дополнительное оборудование персонального компьютера, позволяющее обрабатывать звук (выводить на акустические системы и/или записывать). На момент появления звуковые платы представляли собой отдельные карты расширения, устанавливаемые в соответствующий слот. В современных компьютерах чаще представлены в виде интегрированного в материнскую плату аппаратного кодека (согласно спецификации Intel AC'97 или Intel HD Audio).
В первую очередь, аудиокарта осуществляет преобразование цифрового сигнала в аналоговый (при воспроизведении), и наоборот (при записи). Звуковые карты характеризуются отношением сигнал/шум, поддержкой цифровых стандартов обработки звука, количеством и типами входов/выходов.
Фон Нейман
Принцип работы:
-
С помощью внешнего устройства в память компьютера вводится программа.
-
Устройство управления считывает содержимое ячейки памяти, где находится первая инструкция (команда) программы и организует ее выполнение. Команда может задавать:
-
выполнение логических или арифметических операций;
-
чтение из памяти данных для выполнения арифметических или логических операций;
-
запись результатов в память;
-
ввод данных из внешнего устройства в память;
-
вывод данных из памяти на внешнее устройство.
-
-
Устройство управления начинает выполнение команды из ячейки памяти, которая находится непосредственно за только что выполненной командой. Однако этот порядок может быть изменен с помощью команд передачи управления (перехода). Эти команды указывают устройству управления, что ему необходимо продолжить выполнение программы, начиная с команды, содержащейся в иной ячейки памяти.
-
Результаты выполнения программы выводятся на внешнее устройство компьютера.
-
Компьютер переходит в режим ожидания сигнала от внешнего устройства.
Один из принципов "Архитектуры фон Неймана" гласит: в компьютере не придется изменять подключения проводов, если все инструкции будут храниться в его памяти . И как только эту идею в рамках “архитектуры фон Неймана» воплотили на практике, родился современный компьютер.
Фон Нейман нашел путь подключения рабочей программы не проводами или другими соединениями, а интегрированием ее в память машины в закодированном виде. К устройствам ввода/вывода относятся клавиатура, мышь, монитор, дисковод, CD ROM, принтер, сканер, микрофон, звуковые колонки, плоттер и т.д.
Компьютер должен иметь:
-
арифметическо-логическое устройство, выполняющее арифметические и логические операции. В наше время это устройство называется центральный процессор. Центральный процессор(central processing unit) – микропроцессор компьютера, представляющий собой микросхему, которая управляет всеми процессами, происходящими в компьютере;
-
устройство управления, которое организует процесс выполнения программ. В современных компьютерах арифметическо-логическое устройство и устройство управления объединены в центральный процессор;
-
запоминающее устройство (память) для хранения программ и данных;
-
внешние устройства для ввода-вывода информации.
Сплошные
стрелки — это управляющие связи (по ним
идут сигналы управления), а пунктирные
стрелки — это информационные связи (по
ним идут данные, информация).
Многопроцессорные системы - универсальные приборы, эквивалентные по значению транзистору, которые создаются на тонких кремниевых пластинках СБИС, в настоящее время так миниатюрны и дешевы, что чрезвычайно большое число процессоров может быть объединено в единую сеть.
Многопроцессорность (Мультипроцессорность, Многопроцессорная обработка, англ. Multiprocessing) — использование пары или большего количества физических процессоров в одной компьютерной системе. Термин также относится к способности системы поддержать больше чем один процессор и/или способность распределить задачи между ними.
Системы с общей и распределенной памятью
Особенность ВС – множество параллельно работающих процессоров. Важная задача – задача организации памяти.
Две проблемы: 1) Различие между быстродействием процессора и памяти (как и в однопроцессорных системах); 2) Одновременный доступ к памяти нескольких процессоров.
В зависимости от организации памяти различают:
-
ВС с общей памятью (shared memory, мультипроцессоры, сильно связанные, closely coupled systems);
-
ВС с распределенной памятью (distributed memory, слабо связанные, loosely coupled systems, мультикомпьютеры).
Различие между общей и распределенной памятью - это разница в структуре виртуальной памяти, то есть в том, как память выгладит со стороны процессора. Физически почти каждая система памяти разделена на автономные компоненты, доступ к которым может производиться независимо. Общую память от распределенной отличает то, каким образом подсистема памяти интерпретирует поступивший от процессора адрес ячейки. Для примера положим, что процессор выполняет команду LoadR0,i, означающую «Загрузить регистр R0 содержимым ячейки i». В случае общей памяти i - это глобальный адрес, и для любого процессора указывает на одну и ту же ячейку. В распределенной системе памяти i - это локальный адрес. Если два процессора выполняют команду LoadR0,i, то каждый из них обращается к i-й ячейке в своей локальной памяти, то есть к разным ячейкам, и в регистры R0 могут быть загружены неодинаковые значения.
Различие между двумя системами памяти должно учитываться программистом, поскольку оно определяет способ взаимодействия частей распараллеленной программы.
Мультипроцессоры сложно строить, но легко программировать. Мультикомпьютеры легко строить, но сложно программировать.
Поэтому стали предприниматься попытки создания гибридных систем, которые относительно легко конструировать и относительно легко программировать. Это привело к осознанию того, что совместную память можно реализовывать по-разному, и в каждом случае будут какие-то преимущества и недостатки.
Практически все исследования в области архитектур с параллельной обработкой направлены на создание гибридных форм, которые сочетают в себе преимущества обеих архитектур. Здесь важно получить такую систему, которая расширяема, то есть которая будет продолжать исправно работать при добавлении все новых и новых процессоров.
Операцио́нная систе́ма, сокр. ОС (англ. operating system, OS) — комплекс управляющих и обрабатывающих программ, которые, с одной стороны, выступают как интерфейс между устройствамивычислительной системы и прикладными программами, а с другой стороны — предназначены для управления устройствами, управления вычислительными процессами, эффективного распределения вычислительных ресурсов между вычислительными процессами и организации надёжных вычислений. Это определение применимо к большинству современных операционных систем общего назначения.
Основные функции:
-
Выполнение по запросу программ (ввод и вывод данных, запуск и остановка других программ, выделение и освобождение дополнительной памяти и др.).
-
Загрузка программ в оперативную память и их выполнение.
-
Стандартизованный доступ к периферийным устройствам (устройства ввода-вывода).
-
Управление оперативной памятью (распределение между процессами, организация виртуальной памяти).
-
Управление доступом к данным на энергонезависимых носителях (таких как жёсткий диск, оптические диски и др.), организованным в той или иной файловой системе.
-
Обеспечение пользовательского интерфейса.
-
Сохранение информации об ошибках системы.
Дополнительные функции:
-
Параллельное или псевдопараллельное выполнение задач (многозадачность).
-
Эффективное распределение ресурсов вычислительной системы между процессами.
-
Разграничение доступа различных процессов к ресурсам.
-
Организация надёжных вычислений (невозможности одного вычислительного процесса намеренно или по ошибке повлиять на вычисления в другом процессе), основана на разграничении доступа к ресурсам.
-
Взаимодействие между процессами: обмен данными, взаимная синхронизация.
-
Защита самой системы, а также пользовательских данных и программ от действий пользователей (злонамеренных или по незнанию) или приложений.
-
Многопользовательский режим работы и разграничение прав доступа (см. аутентификация, авторизация).
Компоненты операционной системы
-
Загрузчик
-
Ядро
-
Командный процессор (интерпретатор)[1]
-
Драйверы устройств
-
Интерфейс
Основные
типы данных:
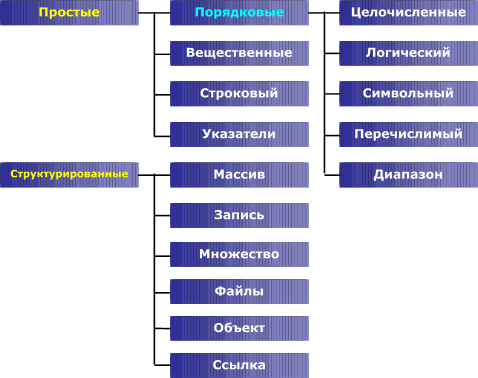
Данные, хранящиеся в памяти ЭВМ представляют собой совокупность нулей и едениц (битов). Биты объединяются в последовательности: байты, слова и т.д. Каждому участку оперативной памяти, который может вместить один байт или слово, присваивается порядковый номер (адрес).
Какой смысл заключен в данных, какими символами они выражены - буквенными или цифровыми, что означает то или иное число - все это определяется программой обработки. Все данные необходимые для решения практических задач подразделяются на несколько типов, причем понятие тип связывается не только с представлением данных в адресном пространстве, но и со способом их обработки.
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач.
Данные простого типа это - символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных.
Запись совокупность элементов данных разного типа. В простейшем случае запись содержит постоянное количество элементов, которые называютполями. Совокупность записей одинаковой структуры называется файлом. (Файлом называют также набор данных во внешней памяти, например, на магнитном диске). Для того, чтобы иметь возможность извлекать из файла отдельные записи, каждой записи присваивают уникальное имя или номер, которое служит ее идентификатором и располагается в отдельном поле. Этот идентификатор называют ключом.
Порядковые типы характеризуются тем, что каждый из них имеет конечное число возможных значений, среди которых установлен линейный порядок. С каждым из значений можно сопоставить некоторое целое число - его порядковый номер.
Строковый тип (String, String[n]) - этот тип данных определяет последовательности символов - строки. Параметр n определяет максимальное количество символов в строке. Если он не задан, подразумевается n=255. Значение типа "строка" в программе запиывается как последовательность символов, заключенных в одиночные кавычки (апострофы), например
Допустимые операции: - присваивание; - сложение (конкатенация, слияние); например, S := 'Зима'+' '+'пришла!'; - сравнение: <, >, >=, <=, <>, =. Строки считаются равными, если имеют одинаковую длину и посимвольно эквивалентны.
Вещественные типы - обозначают множества вещественных чисел в различных диапазонах. Имеется пять вещественных типов, различающихся диапазоном допустимы
допустимые операции: - присваивание; - все арифметические: +, - ,*, / ; - сравнение: <, >, >=, <=, <>, =. При сравнении вещественных чисел следует помнить, что в следствие неточности их представления в памяти компьютера (в виду неизбежности округления) стоит избегать попыток определения строгого равенства двух вещественных значений. Есть шанс, что равенство окажется ложным, даже если на самом деле это не так.х значений и размером занимаемой оперативной памяти.
Массив - упорядоченная структура однотипных данных, хранящая их последовательно. Массив обязательно имеет размеры, определяющие сколько элементов хранится в структуре. До любого элемента в массиве можно добраться по его индексу.