

Практическое задание 2 Нелинейный регрессионный анализ при обработке результатов пассивных экспериментов
Задание: провести нелинейный регрессионный анализ.
Сгладить данную экспериментальную кривую.
Параметр |
Значения х |
||||||||||
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
у |
30 |
31 |
32 |
33,5 |
34 |
36,3 |
38 |
40 |
43 |
46 |
49 |
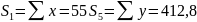
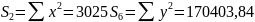
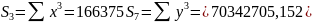
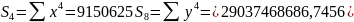
Для расчета параметров регрессии построим расчетную таблицу (табл. 3)
x |
y |
x2 |
y2 |
x*y |
0 |
30 |
0 |
900 |
0 |
1 |
31 |
1 |
961 |
31 |
2 |
32 |
4 |
1024 |
64 |
3 |
33.5 |
9 |
1122.25 |
100.5 |
4 |
34 |
16 |
1156 |
136 |
5 |
36.3 |
25 |
1317.69 |
181.5 |
6 |
38 |
36 |
1444 |
228 |
7 |
40 |
49 |
1600 |
280 |
8 |
43 |
64 |
1849 |
344 |
9 |
46 |
81 |
2116 |
414 |
10 |
49 |
100 |
2401 |
490 |
55 |
412.8 |
385 |
15890.94 |
2269 |
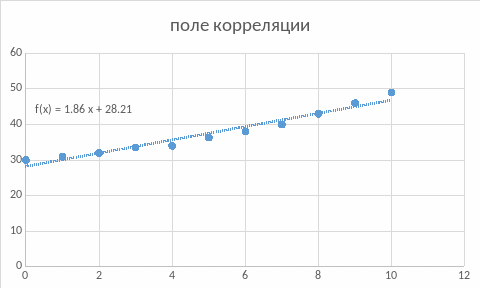
Для наших данных система уравнений имеет вид 11a + 55·b = 412.8 55·a + 385·b = 2269 Домножим уравнение системы на (-5), получим систему, которую решим методом алгебраического сложения. -55a -275 b = -2064 55*a + 385*b = 2269 Получаем: 110*b = 205 Откуда b = 1.8636 Теперь найдем коэффициент «a» из уравнения: 11a + 55*b = 412.8 11a + 55*1.8636 = 412.8 11a = 310.3 a = 28.2091 Получаем эмпирические коэффициенты регрессии: b = 1.8636, a = 28.2091 Уравнение регрессии (эмпирическое уравнение регрессии): y = 1.8636 x + 28.2091
Параметры уравнения регрессии. Выборочные средние.
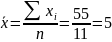
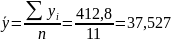
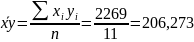 Выборочные
дисперсии:
Выборочные
дисперсии:
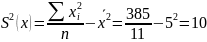
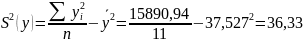 Среднеквадратическое
отклонение
Среднеквадратическое
отклонение
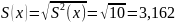
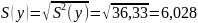 Коэффициент
корреляции b можно находить по формуле,
не решая систему непосредственно:
Коэффициент
корреляции b можно находить по формуле,
не решая систему непосредственно:
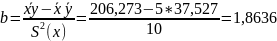 a
= \\x\\to(y) - b·\\x\\to(x) = 37.527 - 1.8636·5 = 28.2091
a
= \\x\\to(y) - b·\\x\\to(x) = 37.527 - 1.8636·5 = 28.2091
Коэффициент корреляции. Ковариация.
cov(x,y)
= \\x\\to(x·y)
- \\x\\to(x)·\\x\\to(y)
= 206.273 - 5·37.527 = 18.64
Рассчитываем
показатель тесноты связи. Таким
показателем является выборочный линейный
коэффициент корреляции, который
рассчитывается по формуле:
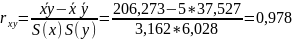
Коэффициент детерминации. Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака. Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах. R2= 0.9782 = 0.9559 т.е. в 95.59% случаев изменения х приводят к изменению y. Другими словами - точность подбора уравнения регрессии - высокая. Остальные 4.41% изменения Y объясняются факторами, не учтенными в модели (а также ошибками спецификации). Для оценки качества параметров регрессии построим расчетную таблицу (табл. 4)
x |
y |
y(x) |
(yi-ycp)2 |
(y-y(x))2 |
|y - yx|:y |
0 |
30 |
28.209 |
56.66 |
3.207 |
0.0597 |
1 |
31 |
30.073 |
42.605 |
0.86 |
0.0299 |
2 |
32 |
31.936 |
30.551 |
0.00405 |
0.00199 |
3 |
33.5 |
33.8 |
16.219 |
0.09 |
0.00896 |
4 |
34 |
35.664 |
12.442 |
2.768 |
0.0489 |
5 |
36.3 |
37.527 |
1.506 |
1.506 |
0.0338 |
6 |
38 |
39.391 |
0.223 |
1.935 |
0.0366 |
7 |
40 |
41.255 |
6.114 |
1.574 |
0.0314 |
8 |
43 |
43.118 |
29.951 |
0.014 |
0.00275 |
9 |
46 |
44.982 |
71.787 |
1.037 |
0.0221 |
10 |
49 |
46.845 |
131.623 |
4.642 |
0.044 |
55 |
412.8 |
412.8 |
399.682 |
17.636 |
0.32 |
Ошибка аппроксимации. Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации - среднее отклонение расчетных значений от фактических:
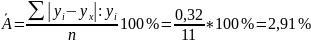
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения регрессии к исходным данным. В среднем, расчетные значения отклоняются от фактических на 2.91%. Поскольку ошибка меньше 7%, то данное уравнение можно использовать в качестве регрессии.
F-статистика. Критерий Фишера.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму: 1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R2=0 на уровне значимости α. 2. Далее определяют фактическое значение F-критерия:
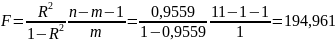 Поскольку
фактическое значение F > Fтабл,
то коэффициент детерминации статистически
значим (найденная оценка уравнения
регрессии статистически надежна).
Поскольку
фактическое значение F > Fтабл,
то коэффициент детерминации статистически
значим (найденная оценка уравнения
регрессии статистически надежна).
t-статистика. Критерий Стьюдента.
tкрит(n-m-1;α/2) = tкрит(9;0.025) = 2.685
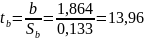 Поскольку
13.96 > 2.685, то статистическая значимость
коэффициента регрессии b подтверждается
(отвергаем гипотезу о равенстве нулю
этого коэффициента).
Поскольку
13.96 > 2.685, то статистическая значимость
коэффициента регрессии b подтверждается
(отвергаем гипотезу о равенстве нулю
этого коэффициента).
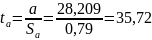 Поскольку
35.72 > 2.685, то статистическая значимость
коэффициента регрессии a подтверждается
(отвергаем гипотезу о равенстве нулю
этого коэффициента).
Поскольку
35.72 > 2.685, то статистическая значимость
коэффициента регрессии a подтверждается
(отвергаем гипотезу о равенстве нулю
этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии. Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими: (b - tкрит Sb; b + tкрит Sb) (1.86 - 2.685*0.133; 1.86 + 2.685*0.133) (1.505;2.222) С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале. (a - tкрит Sa; a + tкрит Sa) (28.209 - 2.685*0.79; 28.209 + 2.685*0.79) (26.089;30.329) С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
Выводы. Изучена зависимость Y от X. На этапе спецификации была выбрана парная линейная регрессия. Оценены её параметры методом наименьших квадратов. Статистическая значимость уравнения проверена с помощью коэффициента детерминации и критерия Фишера. Установлено, что в исследуемой ситуации 95.59% общей вариабельности Y объясняется изменением X. Установлено также, что параметры модели статистически значимы. Возможна экономическая интерпретация параметров модели - увеличение X на 1 ед.изм. приводит к увеличению Y в среднем на 1.864 ед.изм.