

12.3.3. Средства навигации в Интернете
В Интернете не существует компьютера, который бы знал адреса всех других компьютеров сети и способов соединения с ними. Если нужный вам адрес не будет найден на запрашиваемом DNS-сервере, компьютер обратится к другомуDNS-серверу и т.д.
Однако существуют специальные DNS-серверы (служба доменных имен), распределенные по всему миру, каждый из которых отвечает за определенную часть сети. Слова в любом тексте в информационном отношении неравнозначны.
Основная технология поиска следующая. Программа обходит Интернет, «читая» web-страницы и сохраняя их содержимое на поисковом сервере. Затем анализируется структура документа, заголовки, подзаголовки, выделяются ссылки на другие документы и изображения. Затем собранный массив информации обрабатывается по специальному алгоритму и в результате формируется индекс – специальная структура данных, по которой и проводится поиск по запросам пользователей и формируется страница результатов поиска.
Существующие поисковые системы хорошо работают с HTML-документами, с обычнымиASCII-текстами и новостямиusernet. Трудности возникают для текстовWinword. Это связано с тем, что такие тексты содержат большое количество управляющих символов и текстов. Трудно осуществлять поиск для текстов, которые представлены в графической форме. Информация уже загруженная в Интернет, требует эффективных средств навигации. Это подтверждается и тем, что на запрос, Интернет предоставляет сотни, тысячи документов.
Поисковых систем достаточно много, наиболее популярные из них: Google,Yahoo,MNS,AOLSearch,Altavista. В России:Yandex,Rambler,Aportи другие. Как в мире, так и в других странах поисковые системы возникают и умирают. Для получения более свежей информации о поисковых системах можно найти, набрав ключевое слово «современные поисковые системы». Часто поисковая система ориентируется на какую-то конкретную область информации.
Все поисковые системы мира можно найти на www.netoteka.ru
Поисковые системы:
http://www.google.com- поисковая системаGoogle
http://www.yandex.ru– поисковая системаYandex
http://www.aport.ru– поисковая система Апорт
http://www.rambler.ru– поисковая система Рамблер
http://www.mail.ru- порталMail.ru
http://www.shpl.ru/adress/email/- адреса российских библиотек и архивы России
http://www.openweb.ru/rusarch- адреса российских библиотек и архивы России
http://www.school.edu/ru-Российский образовательный портал
http://www.ege.edu.ru–портал единого государственного экзамена
http://www.en.tdu–естественно-научный портал
http://www.ecsocman.edu.ru-фед. портал «Экономика. Социология.Менеджемт»
http://www.openet.edu.ru– Российский портал открытого образования
http://Leweb.log.gov/- фундаментальный каталог мира Библиотека конгресса США
12 млн. единиц хранения, в том числе и на русском языке
http://www.lib-journal.ru– научно-методический журнал «Библиотеки учебных заведений»
http://ellib.gpntb.ru– журнал «Научные и технические библиотеки»
http://www.library.ru– информационно-справочный портал о библиотеках и для библиотек
http://www.msses.ru/win/departments/library/links.html- библиотечные ресурсы «on-line»
http://www.scsml.rssi.ru/listrus.html- Российская сеть библиотек вInternet
http://lib.da.ruилиhttp://stratum.pstu.ac.ru– электронная библиотека
Примером ведущих Webсеверов, предлагающих доступ к большим базам НТИ для пользователей Интернет, могут служить:
EasyNet 2.0(http://www.telebase.com/) – коммерческая служба фильтрации и доставки информации через Интернет, организованная шлюзовой службой доступа к более чем 250 базам данных. Доступ к службе бесплатный, но пользователь платит за каждый поиск от 2$ до 5$ за полный текст статьи.
UnCover Periodicals(http://www.carl.org/uncover/unchome.html) – служба диалогового поиска в базах данных более чем тысячи библиотек, охватывающих более 17 тыс. наименований периодических изданий.
Internet Patent Search(http://sunsite.unc.edu/patents/intropat.html) – сервер, предлагающий услуги поиска патентной информации и доступа к полному тексту патентов с иллюстрациями. Предоставляются также платные услуги по предоставлению копий статей, представленных в Интернете.
UMI InfoStore(http://www.umi.com/ach/index.htm) –cлужба коммерческой компании, предоставляющая пользователю доступ к статьям из 15 тысяч сериальных изданий, на основе которых подготавливаются ее базы данных.
Российские Webсерверы, предлагающие доступ к научно-технической информации:
МЦНТИ (http://www.icsti.su/) – сервер, предлагающий базы данных НТИ по различным областям знаний.
РИНКЦЭ (http://www.extech.msk.su/) – сервер, содержащий список государственных научных центров по отраслям науки, а также тексты документов, формирующих нормативно-правовую базу науки и техники в России.
RD MNTS-Service Company(http://www.mns.msk.su/) – сервер, охватывающий информацию о российский научно-технических достижениях.
РосНИИРОС (http://www.ripn.net/) – сервер, обеспечивающий в рамках службы ИНФОМАГ доступ к оглавлениям научно-технических журналов и зарубежных электронных бюллетеней, кратким тезисам статей.
Instauratio Magma(http://www.free.net/IM/main.ru.html) – информационная система ВУЗов России, создаваемая по программе Госкомвуза РФ – Национальная система баз данных и баз знаний высшей школы России.
Курьер РАН и высшей школы(http://www.free.net/courier/ENTRY.ru.html) – электронный ежемесячный журнал, включающий материалы о жизни научного общества России и международную информацию (сведения о грантах, вакансиях, зарубежных научных организациях).
Международная поддержка российской науки и высшей школы– по адресу (http://www.free.net/ENTRY.ru.html) – страница, содержащая справочник по негосударственным источникам финансирования российской науки и образования.
Современная поисковая системасодержит в себе несколько подсистем (2).
Web-агенты. Осуществляют поиск серверов, извлекают оттуда документы и передают их системе обработки.
Система обработки. Индексирует полученные документы, используя синтаксический разбор и стоп-листы (где содержатся все стандартные операторы и атрибутыHTML).
Система поиска. Воспринимает запрос от системы обслуживания, осуществляет поиск в индексных файлах, формирует список найденных ссылок на документы.
Система обслуживания. Принимает запросы поиска от клиентов, преобразует их, направляет системе поиска.
Работа Web-агента происходит непрерывно, вне зависимости от поступающих запросов. Их задача – выявление новых документов или новых версий уже существующих документов. Под документов здесь подразумеваетсяHTML, текстовый илиnntp-документ. Каждый новый документ передается системе обработки.
Когда робот заходит на ЭВМ, он проверяет
наличие в корневом каталоге файла
robots.txt.
Обнаружив его, робот копирует этот файл
и следует изложенным в нем рекомендациям.
Содержимое файлаrobots.txtможет выглядеть таким образом
# robots.txtforhttp://store.in.ru
user-agent: #* соответствует любому имени робота
disallow: /cgi-bin/ # не допускать робот в каталогcgi-bin
disallow: /tmp/ # не следует индексировать временные файлы
disallow: /private/ # не следует заходить в частные каталоги
Автор исходного теста может заметно помочь поисковой системе, выбрав умело заголовок и подзаголовок и перечислив ключевые слова в подзаголовках.
Для написания рефератов документов, необходимо знать критерии оценки важности отдельных слов и фраз, составляющих текст. Оценку значимости предложений выработал Г. Лун. Он предложил оценивать предложения текста в соответствии с параметром:
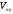 =
=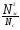 ,
, где
где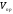 -
значимость предложения,
-
значимость предложения,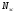 -
число значимых слов в предложении,
-
число значимых слов в предложении,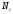 -
полное число слов в предложении.
-
полное число слов в предложении.
Автоматическая система выявления ключевых слов обычно использует статистический частотный анализ (методика В. Пуарто). Пусть f- частота, с которой встречаются различные слова в тексте, аu– относительное значение полезности (важности), тогда
f(u)
=C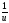 ,
т.е. произведение частоты встречи
слов и их полезности является константой.
,
т.е. произведение частоты встречи
слов и их полезности является константой.
В работах Спарка Джонса экспериментально показано, что если N-число документов иn– число документов, в которых встречается данный индексный термин (ключевое слово), то вычисление веса его по формуле приводит к более эффективным результатам поиска, чем вообще без использования оценки индексного термина
W=log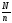 +1
+1
Наиболее эффективным инструментом при поиске можно считать возможность использования в запросе булевых логических операторов AND,OR,NOT. Объединение ключевых слов с помощью логических операторов может сузить или расширить зону поиска.
Многие системы поиска информации основаны на словарях и тезаурусах для корректировки запросов и представления индексируемых документов, чтобы увеличить шансы найти необходимый документ. Словари создаются с помощью одного из двух способов:
- связывают слова, описывающие одну и ту же тему;
- связываются слова, описывающие похожие темы.
Для дальнейшего увеличения эффективности системы используется так называемая кластеризация документов. Это кластеризация ключевых слов и кластеризация документов. Первый способ очень сложный и практически мало используется. На основе определенных взаимосвязей можно построить систему кластеров. Взаимосвязь между документами определяется понятиями «степень сходства», «степень различия», «степень соответствия». Значение степени сходства и степени соответствия между документами увеличивается по мере увеличения количества совпадающих параметров.