

4. Энтропия в контексте защиты информации от помех при передаче по каналу связи
4.1. Меры искажения. Постановка задачи защиты информации от помех при передаче по каналу связи
Мы приступаем к рассмотрению одного из наиболее актуальных сегодня разделов теории информации - к кодированию источников при заданных ограничениях на точность восстановления информации декодером. Такие методы сжатия сегодня востребованы во многих областях обработки, хранения и передачи мультимедиа данных.
Для потребителя системы передачи или хранения информации критерием качества работы кодера и декодера является субъективное восприятие искажений. С точки зрения потребителя искажения могут быть характеризованы как незаметные, допустимые, грубые и т.п. Разработчики систем кодирования также стараются использовать субъективные критерии в своей работе, для чего к тестированию аппаратуры привлекаются группы экспертов. Каждое такое измерение качества требует значительных затрат времени и финансовых средств, поэтому на этапе разработки кодеров необходимо использовать объективные критерии качества.
Конечно, следует выбирать критерии так, чтобы уровень объективного качества был монотонно связан с уровнем субъективного качества. Однако, в большинстве случаев "повергнуть алгебре язык гармоний" не удается. Приходится, как это часто бывает в теоретических исследованиях, накладывать на множестве мер искажений такие ограничения, которые позволили бы с разумной сложностью найти аналитические решения интересующих нас задач.
Итак,
рассмотрим некоторое множествоX
=
{x},
элементы которого - сообщения источника
и второе множество,Y
=
{y},
которое будем называть
аппроксимирующим. Мера
искажения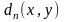 определяется как функция на множестве
определяется как функция на множестве
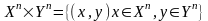 ,
удовлетворяющая следующим ограничениям:
,
удовлетворяющая следующим ограничениям:
- Для любыхx = (x1,..., xn), y = (y1,..., yn)
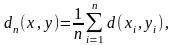 (4.17)
(4.17)
где -
так называемая
побуквенная
мера
искажения.
-
так называемая
побуквенная
мера
искажения.
-
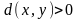 для
всех
для
всех
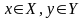
Согласно этим условиям, при кодировании последовательностей сообщений источника, мы рассматриваем только такие меры искажения которые вычисляются как среднее значение побуквенной меры по всем сообщениям последовательностей, причем побуквенная мера обязательно неотрицательна. Оба ограничения вполне естественны. Первое нормирует суммарную ошибку в последовательности сообщений по отношению к длине последовательности и позволяет объективно сравнивать кодеры, обрабатывающие последовательности разной длины. Второе ограничение тоже понятно, оно означает, что аппроксимация приводит к потере точности иd(x,y) указывает величину потери, связанной с заменой точного значения xего аппроксимирующим значением y. Приведем несколько примеров.
Пример. Вероятностная (Хэммингова) мера искажения. Пусть X = {0,..., M-1} - дискретное множество, иY = X. Положим
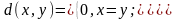
Соответствующая мера представляет собой долю "ошибок" при выдаче получателю y вместо истинной последовательности x. При большой длине последовательностиdn(x,y) можно рассматривать как эмпирическую оценку вероятности ошибочного символа, отсюда - название "вероятностная мера"
Пример. Абсолютная мера искажения. Пусть Х – произвольное множество вещественных чисел и Y = X. Положим

Соответствующая мера представляет собой нормированную сумму модулей отклонения компонентy от компонент последовательностиx.
Пример. Квадратическая мера искажения. Пусть Х – произвольное множество вещественных чисел и Y = X. Положим

Соответствующая мера представляет собой среднеквадратическую ошибку аппроксимации х последовательностью у. Последняя мера наиболее часто используется на практике. Ее можно рассматривать как мощность шума, наложенного на исходную последовательность источника в результате кодирования. Отношение мощности кодируемого сигнала к мощности шума, порожденного кодером, называют отношением сигнал/шум.
Отметим, что во всех примерах предполагалось, что сообщения и аппроксимирующие значения выбираются из одного и того же множества.
Рассмотрим теперь приведенную на рис.15 модель системы, осуществляющей кодирование при заданном критерии качества.
![]()
Рис. 4.1. Схема кодирования с заданным критерием качества
Последовательность
сообщений источника разбивается на
блоки длины n.
Каждый из блоков должен быть аппроксимирован,
по возможности с наименьшим искажением,
некоторой последовательностью .
Будем считать, что аппроксимирующие
последовательности (кодовые
слова)
выбираются из дискретного подмножества
.
Будем считать, что аппроксимирующие
последовательности (кодовые
слова)
выбираются из дискретного подмножества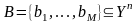 ,
которое
называют
кодом
или (в технической литературе)
кодовой книгой.
Объем книги - некоторое конечное число
,
которое
называют
кодом
или (в технической литературе)
кодовой книгой.
Объем книги - некоторое конечное число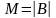 .
Операция кодирования - это выбор
наилучшего слова из кода. Ее можно
выполнить, поочередно перебирая кодовые
слова и подсчитывая каждый раз величину
ошибки аппроксимации. Передаче по каналу
или записи в память подлежит номерm
того слова, которое обеспечивает
наименьшую ошибку.
.
Операция кодирования - это выбор
наилучшего слова из кода. Ее можно
выполнить, поочередно перебирая кодовые
слова и подсчитывая каждый раз величину
ошибки аппроксимации. Передаче по каналу
или записи в память подлежит номерm
того слова, которое обеспечивает
наименьшую ошибку.
Декодер хранит точную копию кодаB и по полученному индексуmвоспроизводит аппроксимирующую последователь-ность y =bm.
Поскольку для передачи индекса m достаточно logM бит (для сокращения записи мы считаем М степенью двойки), скоростью кода источника называется величина
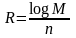 бит
/ сообщение источника.
бит
/ сообщение источника.
При
фиксированном коде В
и заданной вероятностной модели источника
можно усреднением по всем подсчитать
среднюю ошибку
подсчитать
среднюю ошибку
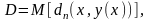
где
через
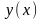 обозначена последовательность у,
которую кодер выбирает в качестве
аппроксимирующей последовательности
для х.
обозначена последовательность у,
которую кодер выбирает в качестве
аппроксимирующей последовательности
для х.
Таким образом, основными характеристиками описанной системы кодирования являются два числа: скорость R и средняя ошибка D. Наша задача закодировать последовательность сообщений с наименьшей скоростью и с наименьшей ошибкой.
Понятно, что уменьшение ошибки потребует увеличения числа кодовых слов. Если же мы захотим уменьшить скорость кода, придется уменьшить число кодовых слов, что приведет к увеличению средней ошибки. Таким образом, два требования противоречат друг другу. Придется зафиксировать один из параметров, например, допустимое искажение D и добиваться наименьшей скорости при заданном искажении. Для некоторого алгоритма или класса алгоритмов построения кодов и заданных процедур кодирования, изменяя требования к ошибке D, можно получить функцию R(D), называемую функцией скорость-искажение.
Более формально, функцией скорость искажение R(D) для заданной модели источника называется функция вида
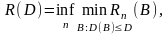
где нижняя рань берется по длинам кодируемых последовательностей, а минимум – по таким кодам последовательностей длины n, которые удовлетворяют ограничению на допустимую ошибку D.
Аналогично можно определить функцию искажение-скорость D(R).
Очевидно, определение невозможно использовать для подсчета функции скорость-искажение. Желательно (как это было сделано для кодирования источников без потерь и для каналов связи) научиться вычислятьR(D) по модели канала без перебора по всевозможным кодам источника, аналогично тому, как для кодирования без потерь минимальная скорость кода определяется энтропией источника, а максимальная достижимая скорость передачи информации по каналу связи равна его пропускной способности.
Вернемся
к схеме на рис. 4.1. Модель источника
задана и тем самым задано распределение
вероятностей на последовательностях
из
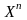 .
Для
определенности, будем считать источник
непрерывным и описывать модель
источника плотностью распределения
вероятностей
.
Для
определенности, будем считать источник
непрерывным и описывать модель
источника плотностью распределения
вероятностей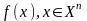 .Заметим,
что среднее количество информации об
,
доставляемой получателю декодером
может быть подсчитано как взаимная
информация
.Заметим,
что среднее количество информации об
,
доставляемой получателю декодером
может быть подсчитано как взаимная
информация
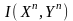 .
Соответственно, затраты в битах в расчете
на одну букву источника составляют
.
Соответственно, затраты в битах в расчете
на одну букву источника составляют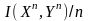 бит. Все промежуточные блоки
ОТ входа
до выхода схемы на рис. 4.1 можно описать
в виде условного распределения
вероятностей
бит. Все промежуточные блоки
ОТ входа
до выхода схемы на рис. 4.1 можно описать
в виде условного распределения
вероятностей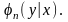 Многообразие таких плотностей полностью
включает в себя все мыслимые схемы
кодирования, но нас интересуют только
такие плотности, при которых выполняется
требование к допустимой ошибке,
которая в данном случае вычисляется
как
Многообразие таких плотностей полностью
включает в себя все мыслимые схемы
кодирования, но нас интересуют только
такие плотности, при которых выполняется
требование к допустимой ошибке,
которая в данном случае вычисляется
как
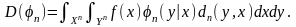
Теоретической
функцией скорость-искажение
называется величина
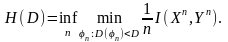 (4.19)
(4.19)
После ознакомления с предыдущими главами, не станет неожиданным то, что для большинства моделей источников функции R(D) и H(D) совпадают. Это означает, что при заданном D скорости сколь угодно близкие H(D) (но не большие H(D)) достижимы, а при скорости меньшей H(D) средняя ошибка неизбежно будет больше D.
Эти утверждения мы сформулируем, как всегда в виде двух теорем кодирования - прямой и обратной. Но прежде, чем мы приступим к формулировке и доказательству теорем кодирования, мы изучим свойства функции H(D)и рассмотрим несколько важных моделей источников и мер искажения, для которых H(D) может быть вычислена в явной форме как функция параметров модели.