1.3. Преобразование данных.
1.3.1. Преобразование шкалы данных.
Команда Recode позволяет создать как новую переменную, так и перекодировать уже существующую. Например, нужно перекодировать переменную «age» в номинальную шкалу по следующему принципу:
если возраст человека больше 0 и меньше 25лет – (значение 1),
если возраст от 25 до 45лет – (значение 2),
если возраст от 45 до 60лет – (значение3)
больше 60 лет – (значение 4),
Для этого необходимо во вкладке Transform выбрать функцию Recode into Different Variables.
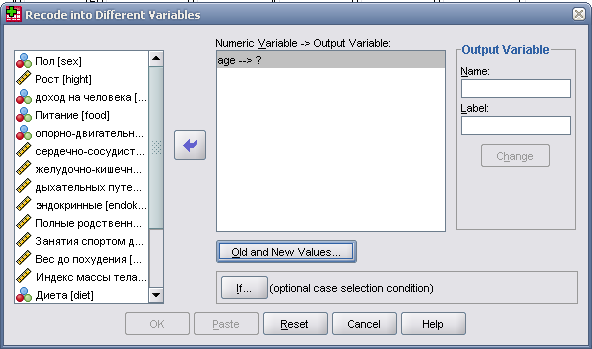
Затем, нажать на кнопку Old and New Values и ввести перекодировку
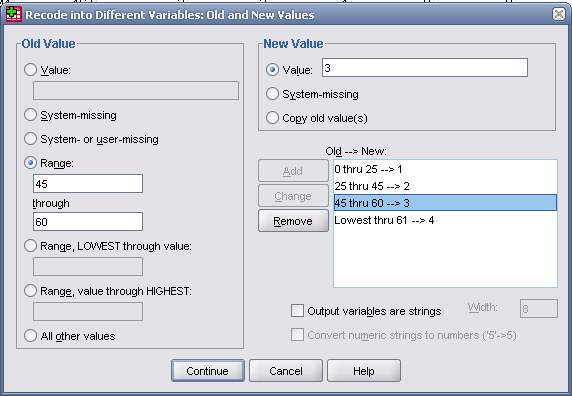
ПослеперекодировкивокнеRecode into Different Variables: Old and New ValuesнеобходимощелкнутьнакнопкеContinue.В окне Recode into Different Variables указать имя новой переменной и щелкнуть на кнопке Change. Затем ОК.
В результате получим
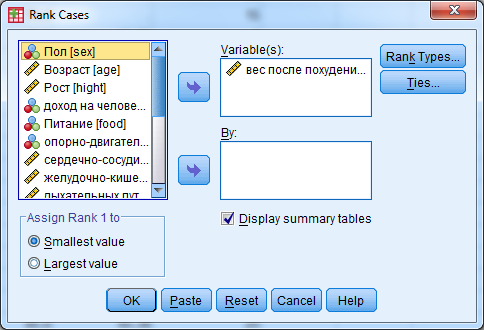
Ранжирование. Команда Rank Cases так же как и Compute Varibles позволяет создать новую переменную, значения которой – ранговые места объектов по заданной переменной.
Ранжирование может быть произведено как для одной переменной (например, для «weight_2», как показано ниже), так и для нескольких переменных одновременно.
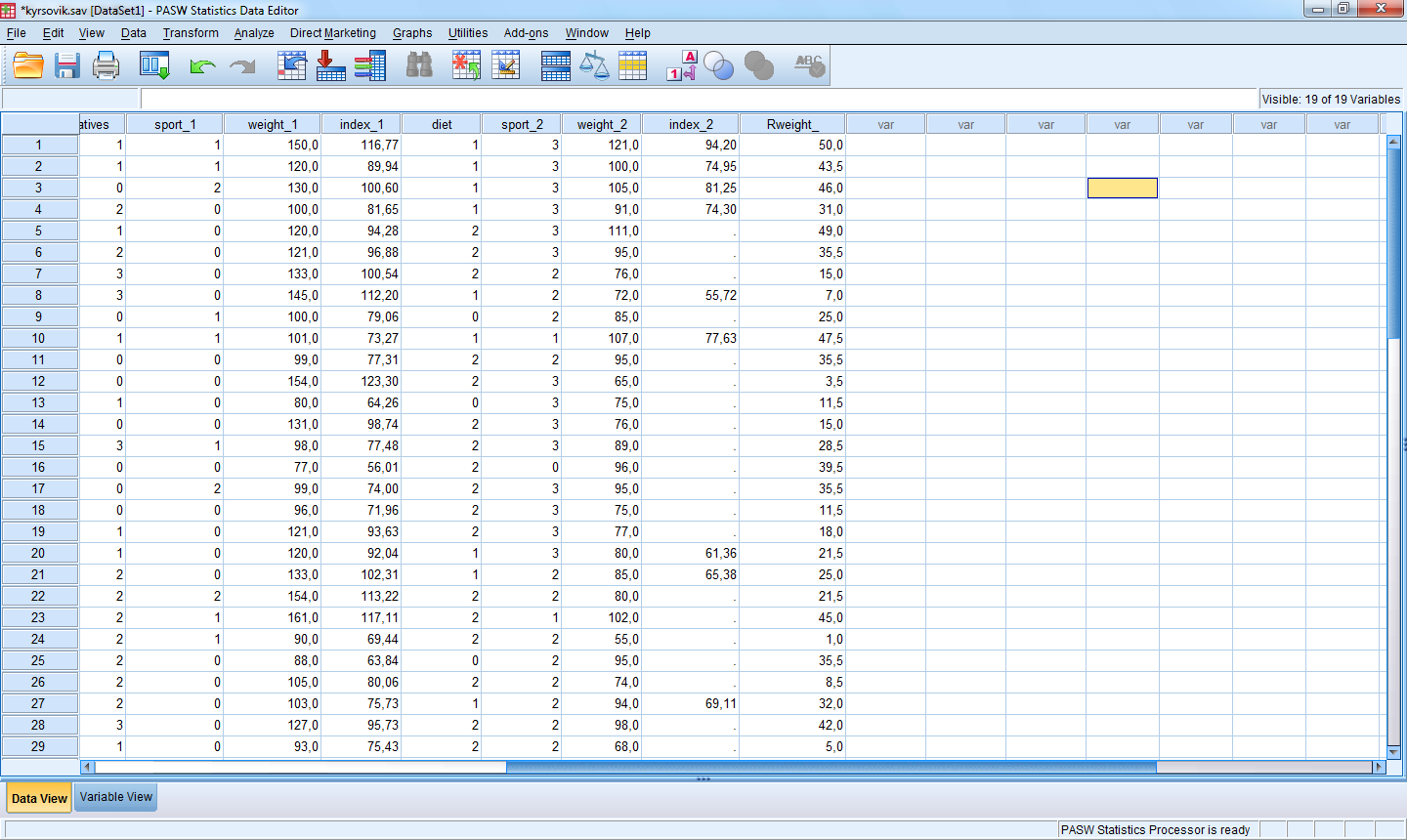
В результате получим
Стандартизация (нормировка) данных - приведение данных к определенному стандарту, дающая возможность их корректного сравнения и проведения некоторых видов анализов (факторного, кластерного…). В SPSS предусмотрена необходимость стандартизации, поэтому, при проведении какого-то из видов анализа, можно установить «стандартизировать данные» и выбрать один из предложенных методов стандартизации.
1.3.2. Вычисление новых переменных.
Операция Compute
Variables
позволяет создавать новые переменные
на основе существующих данных файла.
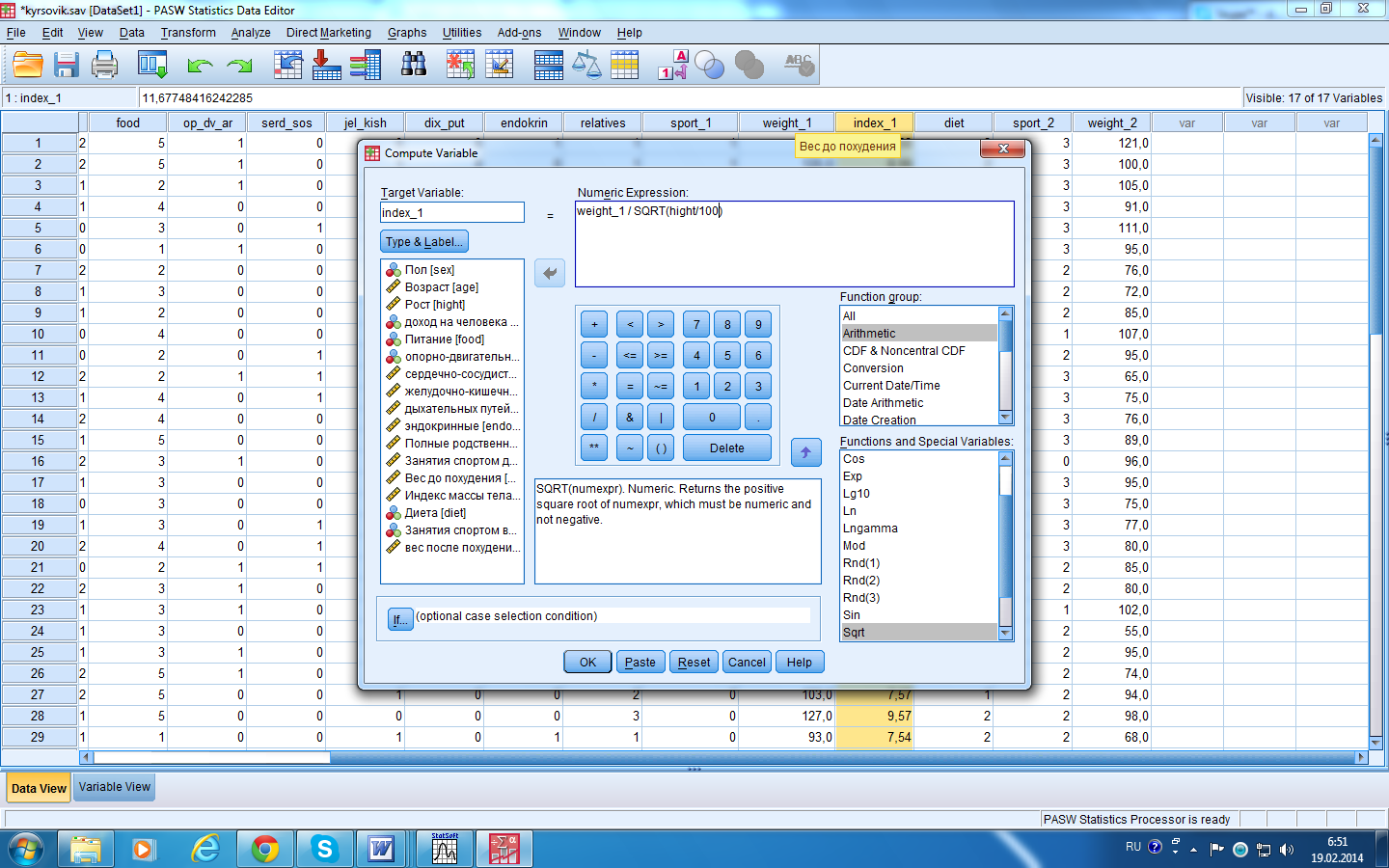
Например, вычислим индекс массы тела
респондентов до программы похудения и
после (![]() ).
).
Создадим предварительно новую переменную «index_1» перед переменной «weight_1». Далее, во вкладке Transform выберем команду Compute Variables
В результате получим
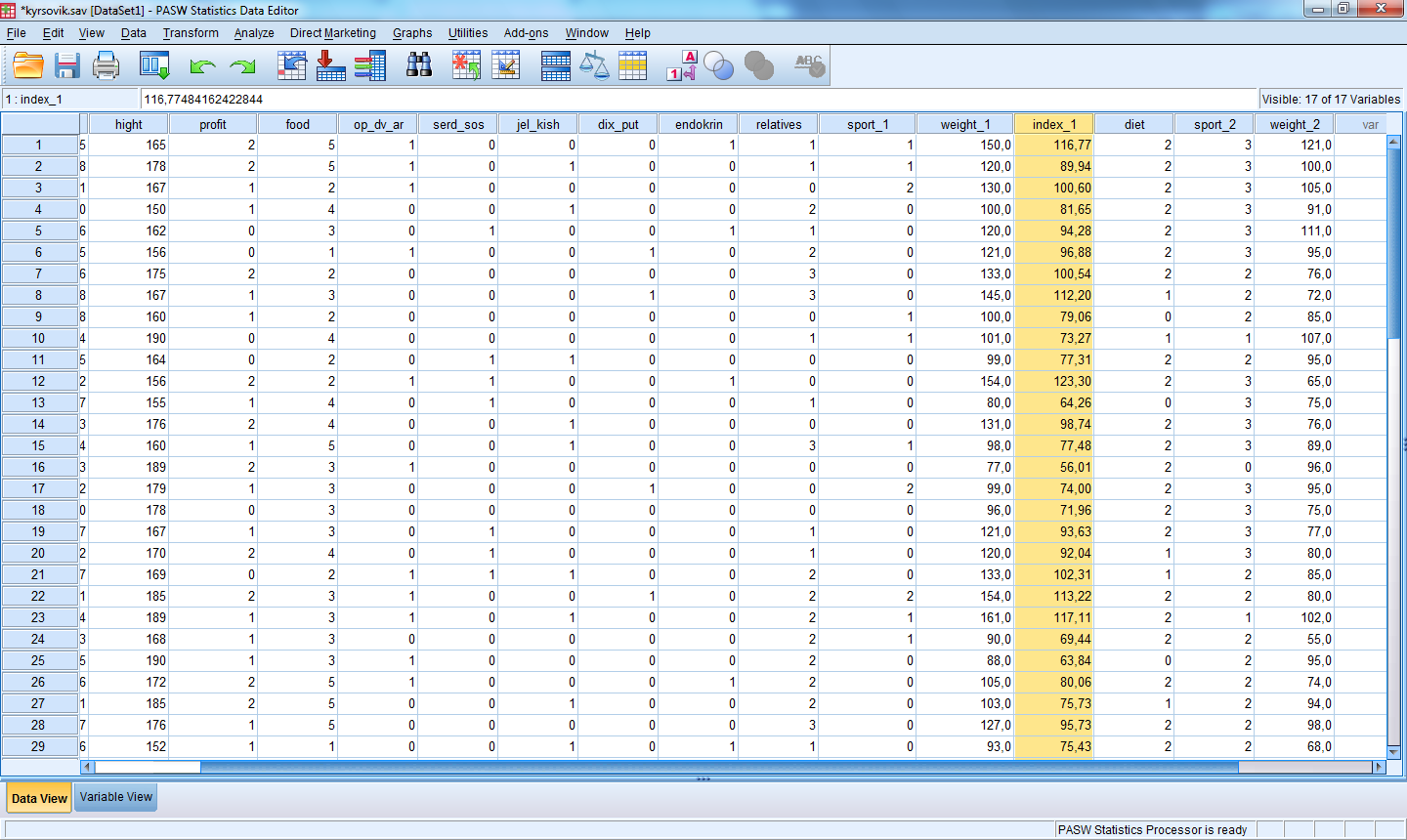
Также с помощью операции Compute Variables можно создать новую переменную, в которой и будут находится рассчитанные по формуле значения. Тогда новая переменная будет помещена в конец таблицы.
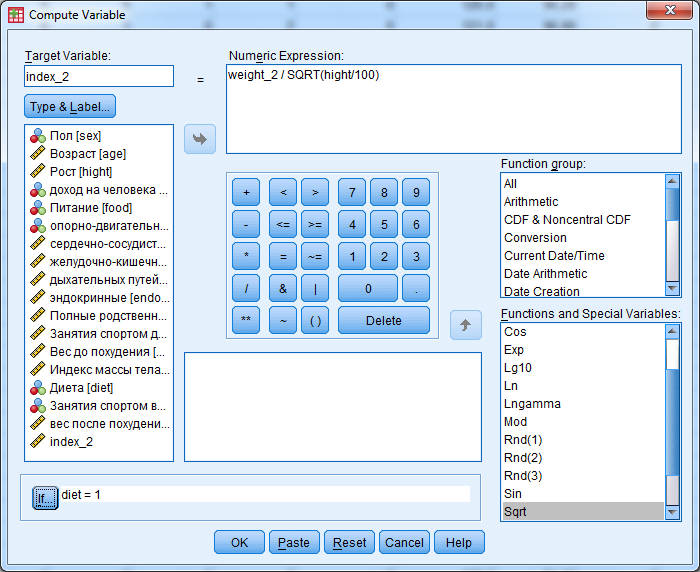
Рассчитаем новую переменную «index_2» - массы тела респондентов после программы похудения.
Если вычисления необходимо произвести только для части объектов (строк), используется функция If . Например, рассчитаем индекс массы тела респондентов после программы похудения только для тех, кто соблюдал диету:
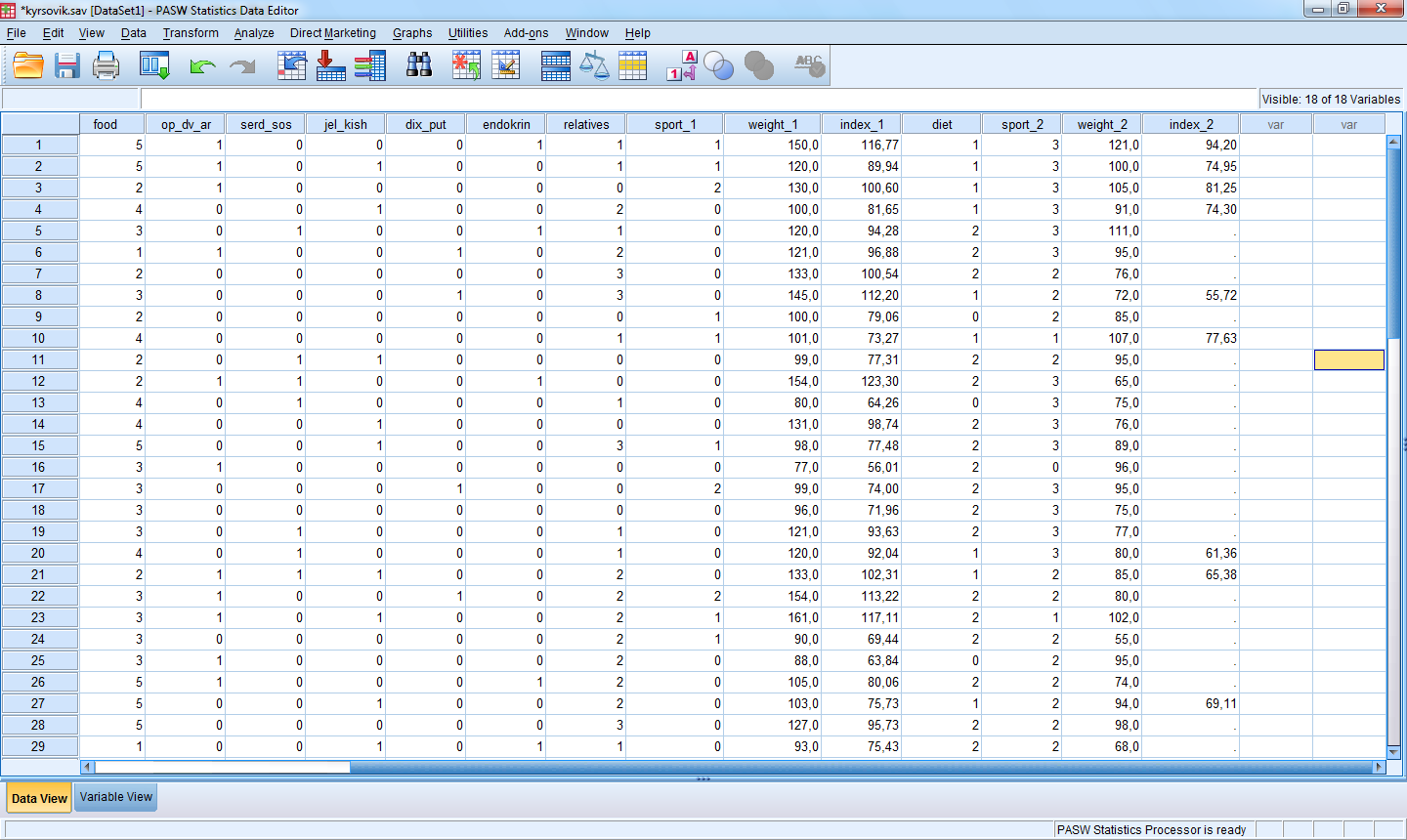
В результате получим
1.4. Статистическая корректировка данных.
1.4.1. Обработка пропущенных значений.
В процессе работы с программой SPSS вы нередко будете сталкиваться с проблемой отсутствующих данных. Обратимся к переменным из примера. Вполне вероятна ситуация, когда кто-либо из участников программы отсутствовал при проведении тестирования или не ответил на вопрос о своем возрасте, либо не указал количество полных родственников в семье. Подобные случаи приводят к тому, что в данных рабочего файла появляются пропущенные значения. Пропущенные значения не только мешают осмысливать данные, но и могут оказывать нежелательное влияние на результаты анализа.
Некоторые статистические процедуры игнорируют объекты (строки), в которых содержится хотя бы одно пропущенное значение. Если, к примеру, из 35 наблюдений 13 имеют пропущенные значения по разным переменным, то анализу будет подлежать немногим более 60 % данных файла, что, несомненно, исказит результаты.
Большинство статистических методов SPSS позволяет учитывать пропуски в данных двумя принципиально различными способами: построчно (listwise) и попарно (pairwise). При построчном учете пропусков SPSS перед выполнением операции проверяет строки (объекты) на наличие пропущенных значений и в случае обнаружения последних исключает соответствующие строки из анализа целиком.
Этот способ позволяет получить наиболее корректные статистические результаты, однако потери данных при этом максимальны. При попарном учете пропусков обработка выполняется без дополнительных проверок, и в процессе вычислений не выполняются только те операции, которые требуют наличия пропущенного значения. Таким образом, в анализе участвуют все введенные данные, но результаты анализа содержат погрешности.
Мы рекомендуем вам по возможности решать проблему пропущенных значений на этапе ввода и кодирования данных, а не полагаться на то, что SPSS сделает это за вас. В любом случае, чем больше пропусков в исходных данных, тем менее точны и корректны результаты анализа.
Для номинальной переменной проблема пропущенных значений решается легко: вы можете просто ввести для нее еще одну градацию, которая соответствует пропуску в данных. Для количественной переменной (метрической или порядковой), имеющей множество возможных значений, в SPSS предусмотрены специальные процедуры заполнения пропусков:
в меню Преобразовать есть команда Заменить пропущенные значения. При всем соблазне ее использовать следует помнить, что результаты обработки данных с заменой пропусков фиктивными значениями, например средними, вряд ли могут вызвать доверие. Поэтому лучше на месте пропуска честно оставлять пустую ячейку. А вопрос о построчном или попарном учете пропусков решать отдельно для каждого конкретного метода анализа данных.
В справочной системе SPSS часто используется два термина: системные пропущенные значения (system missing values) и пользовательские пропущенные значения (user missing values). Под физически пропущенными значениями понимаются значения, не введенные в компьютер. В редакторе данных пустые ячейки, не содержащие значений, помечены точкой. Логически пропущенные значения — это специальные значения переменной, отражающие невозможность адекватного кодирования некоторой ситуации. Если, например, 1, 2 и 3 — тестовые оценки испытуемого, 8 означает, что тест не завершен, а 9 фиксирует неявку испытуемого, то значения 8 и 9 относятся к логически пропущенным, поскольку их нельзя интерпретировать как результаты теста.
Если в определенных случаях у переменных отсутствуют значения, например, если на вопрос не был дан ответ, ответ неизвестен, или существуют другие причины, пользователь может с помощью кнопки Missing объявить эти значения как пропущенные. Пропущенные значения можно исключить из последующих вычислений.
В примере пропущенным значением, определяемым пользователем, мы присваивается вариант ответа "0" (нет данных) для переменной sex.
Чтобы задать пропущенные значения,
нужно кликнуть в поле Missing на кнопке с
тремя точками
![]() .
Откроется диалоговое окно Define Missing
Values (Определение пропущенных значений).
.
Откроется диалоговое окно Define Missing
Values (Определение пропущенных значений).
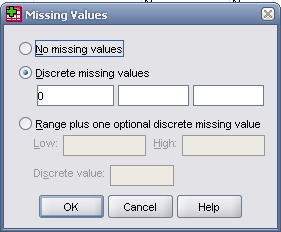
По умолчанию предлагается вариант No missing values (Нет пропущенных значений),то есть все значения в настоящее время рассматриваются как допустимые.
Для задания пользовательских пропущенных значений нужно кликнуть на кнопке Discrete missing values (Отдельные пропущенные значения).Для одной переменной можно задать до трех пользовательских пропущенных значений.
Альтернативный вариант: при выборе кнопки Range and one optional Discrete missing value (Диапазон и единичное отсутствующее значение),при этом все значения в диапазоне отMinimum (Наименьшее значение)доMaximum (Наибольшее значение)включительно объявляются как пропущенные. Кроме того, можно объявить как отсутствующее еще одно значение вне этого диапазона. Для одной переменной можно задать до трех пользовательских пропущенных значений.
Ввести для переменной sex значение "0". Проделась соответствующие действия для всех переменных, которые содержат пропущенные значения.
К сожалению, при сборе данных, как правило, не удается избежать пропущенных значений. Во многих статистических методах, прежде всего одномерных, учет пропущенных значений не составляет проблемы, так как, кроме соответствующего уменьшения количества наблюдений, не нужно вносить никаких дополнительных изменений в расчетный метод. Однако при двумерном, а тем более при многомерном анализе пропущенные значения в списках переменных создают более значительные проблемы, так как одного-единственного отсутствующего значения достаточно, чтобы сделать всю выборку непригодной для анализа.
Анализ пропущенных значений
Процедура Анализ пропущенных значений выполняет три основных функции:
Описывает структуру пропущенных данных. Где расположены пропущенные значения? Насколько широкую область они охватывают? Есть ли тенденция к пропуску значений в нескольких наблюдениях у пар переменных? Принимают ли данные крайние значения? Носят ли пропуски случайный характер?
Оценивает средние, среднеквадратичные отклонения, ковариации и корреляции для различных методов обработки пропущенных значений: по спискам, попарно, регрессия или ОМП (максимизация ожиданий). Попарный метод выводит также частоты полных пар наблюдений.
Производит вставку (импутацию) на место пропущенных значений оценочных значений, используя метод регрессии или ОМП (максимизация ожиданий); впрочем, есть метод, который обычно дает более точные результаты - это множественная импутация.
Анализ пропущенных значений помогает в борьбе с рядом серьезных проблем, порождаемых неполнотой данных. Если наблюдения с пропущенными значениями имеют систематические отличия от наблюдений без пропущенных значений, результаты могут вводить в заблуждение. Кроме того, пропущенные данные могут снизить точность рассчитанной статистики, поскольку информации окажется меньше, чем планировалось. Во многих статистических процедурах подразумевается, что анализ основан на полных наблюдениях, а для учета отсутствующих значений требуется более сложная теория.
Статистики.Одномерная статистика, включая число непропущенных значений, среднее, среднеквадратичное отклонение, число пропущенных значений и число крайних значений. Оценки среднего, ковариационные матрицы и матрицы корреляции, полученные списочным методом, попарно, методом ОМП или регрессией. Критерий Литтла MCAR с результатами ОМП. Сводка средних по разным методам. Для групп, определенных по соотношению пропущенных и непропущенных значений:t-критерии. Для всех переменных: структуры пропущенных значений, выведенные как наблюдения по переменным.
Данные.Данные могут быть категориальными или количественными (непрерывными). Но оценка статистики и импутация пропущенных значений возможны только для количественных данных. Для каждой переменной пропущенные значения, не помеченные как системные значения отсутствия, должны быть определены как пользовательские значения отсутствия. Например, если ответуНе знаюна пункт анкеты присвоен код 5 и нужно обработать его как пропущенный, пометьте для этого пункта значение 5 как пользовательское значение отсутствия.
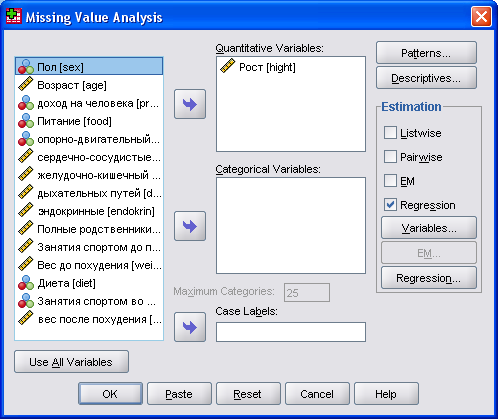
Чтобы выполнить анализ пропущенных значений
Выберите в меню Анализ (Analyze)> Анализ пропущенных значений (Missing Value Analysis). Выберите хотя бы одну количественную переменную для оценки статистики и, если нужно, импутации пропущенных значений.