

9068
.pdfРис. 7. Панель отчетов сценария «Мониторинг водных ресурсов» Чтобы добавить новый отчет, нужно щелкнуть по кнопке Добавить узел или
выбрать соответствующую команду из контекстного меню. В результате откроется окно Выбор узла, в котором следует выделить узел дерева сценария, где содержится нужная выборка данных, и щелкнуть по кнопке Выбрать. Следует отметить, что операция добавления нового отчета доступна, только если выделена папка или кор-
невой пункт Отчеты списка отчетов. Если выделить узел, содержащий отдельный отчет, команда создания нового отчета будет недоступна.
Чтобы добавить новую папку, нужно щелкнуть по кнопке Добавить папку 
или выбрать соответствующую команду в контекстном меню. В результате в списке отчетов появится новая папка с открытым полем имени, куда следует ввести имя папки. После ввода имени для его сохранения щелкнуть по любому узлу списка.
Чтобы поместить отчет в папку, нужно перед вызовом команды Добавить узел вы-
делить эту папку.
На рис. 7. представлены отчеты сценария «Мониторинг водных ресурсов», ко-
торые содержат в себе историю работы с данными и их анализа. Для перехода на ту или иную ветку сценария необходимо щелкнуть правой кнопкой мыши по интере-
сующему отчету и выбрать опцию Найти узел в сценарии, после чего откроется тот или иной узел.
Используя имеющиеся в Deductor OLAP-технологии, отчеты можно предста-
вить в виде OLAP-кубов и кросс-диаграмм. Примером является отчет «Динамика за-
грязнения объекта» (рис. 8.). Он представляет собой сводную таблицу по измерени-
21
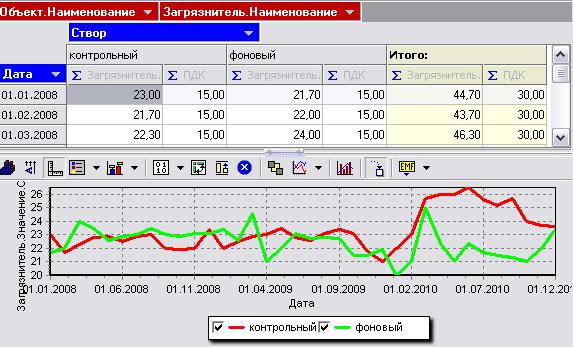
ям «Дата» и «Створ» и кросс-диаграмму, которая показывает динамику загрязнения водного объекта (в данном случае реки Беленькая) для фонового и для контрольного створа конкретным загрязнителем (в данном случае ХПК) на протяжении всего пе-
риода проведения мониторинга.
Данный отчет является универсальным, так как здесь имеется возможность выбора любого другого водного объекта и загрязнителя для быстрого составления отчетности.
Рис. 8. Отчет «Динамика загрязнения объекта»
Рассмотрим порядок настройки OLAP-куба для отчета «Динамика загрязнения объекта» (рис. 8).
Чтобы построить OLAP-куб, пользователь должен активировать мастер визуа-
лизации  и выбрать способ отображения данных в виде куба (рис. 9).
и выбрать способ отображения данных в виде куба (рис. 9).
22
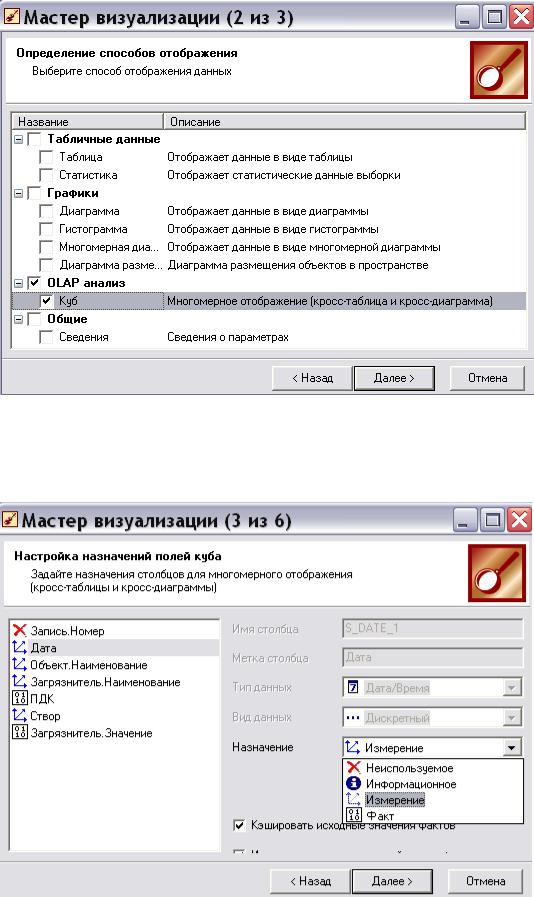
Рис. 9. Выбор способа отображения данных в виде куба На 3 и 4 шаге «Мастера настройки отображения» нужно указать системе, ка-
кие измерения и факты включать в куб (рис. 10, 11).
Рис. 10. Настройка назначений полей куба
23

Рис. 11. Настройка размещений полей куба На последнем шаге нужно выбрать, какие факты нужно отображать в кубе на
пересечении измерений и варианты агрегации их значений (рис. 12).
Рис. 12. Настройка отображения фактов Для отображения фактов предусмотрено 8 способов объединения (агрегирова-
ния):
Сумма – вычисляется сумма объединяемых фактов;
Минимум – среди всех объединяемых фактов в таблице отображается только минимальный;
24
Максимум - среди всех объединяемых фактов в таблице отображается только максимальный;
Среднее – вычисляется среднее значение объединяемых фактов;
Количество – в кубе будет отображаться количество объединенных фактов;
Стандартное отклонение;
Сумма квадратов;
Количество пропусков;
Кроме того, всегда присутствует факт Количество, который рассчитывает
число записей, соответствующих совокупности измерений.
В результате для нашего примера получится многомерный отчет, представ-
ленный на рис. 3.6. Измерения в кубе изображаются специальными полями. Си-
ние поля показывают измерения, участвующие в построении таблицы. Зелеными полями отображаются скрытые измерения, не участвующие в построении таблицы.
Имеется возможность перестраивать таблицу с помощью мыши «на лету». Сделать это можно, если перетаскивать поля с заголовками измерений.
Изменять расположение измерений можно, используя операцию транспониро-
вания таблицы. В результате транспонирования данные, ранее отображавшиеся в строках, отображаются в столбцах, а данные в столбцах преобразуются в строки.
Транспонирование во многих случаях позволяет оперативно сделать таблицу более удобной для восприятия.
Куб можно сортировать как по измерениям, так и по фактам. В первом случае на помощь приходит кнопка  Сортировать значения измерений (по умолчанию значения измерений следуют в алфавитном порядке), во втором – щелчок мышью по заголовку факта, как это показано ниже.
Сортировать значения измерений (по умолчанию значения измерений следуют в алфавитном порядке), во втором – щелчок мышью по заголовку факта, как это показано ниже.
Еще одной полезной возможностью является фильтрация. Чтобы осуществить фильтрацию по значениям измерений, нужно нажать кнопку  в заголовке измере-
в заголовке измере-
ния. Раскроется список всех уникальных значений данного измерения, в котором
25

при помощи флажков можно включить/отключить нужные (рис. 13). Если включены не все значения, заголовок измерения в кубе поменяет цвет с синего на красный.
Рис. 13. Фильтрация по значениям измерения Чтобы осуществить фильтрацию по значениям фактов необходимо во всплы-
вающем меню или на панели инструментов нажать кнопку  , после чего будет от-
, после чего будет от-
крыто окно селектора (рис. 14).
Рис. 14. Окно селектора Слева отображаются все измерения куба и поле Факты, означающее филь-
трацию по фактам. Справа находятся элементы:
Измерение. Фильтрация подразумевает, что в таблице останется лишь часть значений некоторого измерения. Это поле как раз и задает измерение, значе-
ния которого будут отфильтрованы;
Факты и варианты агрегации. В кубе может содержаться один и более фак-
тов. Фильтрация будет происходить по значениям выбранного здесь факта.
26
Для факта выбирается функция агрегации, в соответствии с которой отбира-
ются записи.
Условие – условие отбора записей по значениям выбранного факта.
Условие может принимать различные значения, перечислим некоторые из них.
Первые N. Значения измерения сортируются в порядке убывания факта и вы-
бираются первые N значений измерений. Таким образом, можно, например,
выделить 5 загрязнителей, больше всех превышающих ПДК или 10 наиболее продаваемых товаров, или первые 5 наиболее удачных дней.
Последние N. Значения измерения сортируются в порядке убывания факта и выбираются последние N значений измерений. Например, 10 наименее попу-
лярных товаров.
Доля от общего. Значения измерения сортируются в порядке убывания факта.
В этой последовательности выбирается столько первых значений измерения,
сколько в сумме дадут заданную долю от общей суммы. Например, можно отобрать клиентов, приносящих 80% прибыли, или товары, дающие 50 % объ-
ема продаж.
Диапазон, Больше, Меньше – отбираются записи, для которых значение соот-
ветствующего факта лежит в заданном диапазоне, больше или меньше указан-
ного значения.
2.3.3. Раздел 3. Data Mining: классификация и регрессия. Машинное обуче-
ние. Деревья решений.
Информационный подход к анализу данных получил распространение в таких методиках извлечения знаний, как KDD (Knowledge Discovery in Databases, извлече-
ние знаний из баз данных) и Data Mining (интеллектуальный анализ данных). Сего-
дня на базе этих методик создается большинство прикладных аналитических реше-
ний в бизнесе и многих других областях. KDD включает в себя этапы подготовки данных, выбора информативных признаков, очистки, построения моделей, посто-
бработки и интерпретации полученных результатов. Ядром или шагом процесса
27
KDD являются методы Data Mining, позволяющие обнаруживать закономерности и знания.
Knowledge Discovery in Databases – процесс получения из данных знаний в ви-
де зависимостей, правил, моделей, обычно состоящий из таких этапов, как выборка данных, их очистка и трансформация, моделирование и интерпретация полученных результатов.
Data Mining (DM) – обнаружение в «сырых» данных ранее неизвестных, не-
тривиальных, практически полезных и доступных интерпретации знаний, необхо-
димых для принятия решений в различных сферах человеческой деятельности. К ба-
зовым методам интеллектуального анализа данных прежде всего относят нейронные сети, деревья решений, логистическую регрессию, ассоциативные правила.
Выделяют пять основных типов задач, решаемых методами Data Mining:
1.Классификация – это установление зависимости дискретной выходной пере-
менной от входных переменных.
2.Регрессия – это установление зависимости непрерывной выходной переменной
от входных переменных.
3.Кластеризация – это группировка объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Объекты внутри кластера должны быть похожими друг на друга и отличаться от других, которые вошли в другие кластеры.
4.Ассоциация – выявление закономерностей между связанными событиями.
Примером такой закономерности служит правило, указывающее, что из собы-
тия X следует событие Y. Такие правила называются ассоциативными. Впер-
вые эта задача была предложена для нахождения типичных шаблонов поку-
пок, совершаемых в супермаркетах, поэтому иногда ее называют анализом рыночной корзины (market basket analysis). Если же нас интересует последова-
тельность происходящих событий, то можно говорить о последовательных шаблонах – установлении закономерностей между связанными во времени со-
28
бытиями. Примером такой закономерности служит правило, указывающее,
что из события X спустя время t последует событие Y.
5.Прогнозирование – определение некоторой неизвестной величины по набору связанных с ней значений. Выполняется с помощью таких задач Data Mining,
как регрессия, классификация и кластеризация.
Прогнозирование – одна из самых востребованных задач анализа данных.
Зная, пусть даже с определенной погрешностью, характер развития событий в буду-
щем, можно принимать более обоснованные управленческие решения, планировать деятельность, разрабатывать соответствующие комплексы мероприятий, эффективно распределять ресурсы и т.д.
Существует множество методов, позволяющих сделать прогноз. Среди стати-
стических методов достаточно эффективными считаются методы регрессионного анализа. Их суть заключается в определении кривой, наиболее точно описывающей связь между двумя параметрами на основании существующих статистических дан-
ных. Развитие методов прогнозирования непосредственно связано с развитием ин-
формационных технологий, в частности, с ростом объемов хранимых данных и усложнением методов и алгоритмов прогнозирования, реализованных в инструмен-
тах интеллектуального анализа данных – Data Mining.
Ввиду того, что Data Mining развивается на стыке таких дисциплин, как мате-
матика, статистика, теория информации, машинное обучение, теория баз данных,
программирование, параллельные вычисления, вполне закономерно, что большин-
ство алгоритмов и методов Data Mining были разработаны на основе подходов, при-
меняемых в этих дисциплинах.
Эти методы стали весьма широко и эффективно применяться в связи с бурным развитием в последнее десятилетие XX века самих методик и соответствующих ин-
струментальных средств. Они находят применение в тех ситуациях, когда обычные методы анализа трудно или невозможно применить из-за отсутствия сведений о ха-
рактере или закономерностях исследуемых процессов, взаимозависимостях явлений,
29
фактов, поведении объектов и систем из различных предметных областей, в том числе в социальной и экономической.
На сегодняшний день наибольшее распространение в Data Mining получили
методы машинного обучения: деревья решений, нейронные сети, ассоциативные правила и т. д.
Машинное обучение (machine learning) – обширный подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться на данных.
Общая постановка задачи обучения следующая. Имеется множество объектов
(ситуаций) и множество возможных ответов (откликов, реакций). Между ответами и объектами существует некоторая зависимость, но она неизвестна. Известна только конечная совокупность прецедентов – пар вида «объект – ответ», – называемая обу-
чающей выборкой. На основе этих данных требуется обнаружить зависимость, то есть построить модель, способную для любого объекта выдать достаточно точный ответ. Чтобы измерить точность ответов, вводится критерий качества.
Основные этапы решения задач методами Data Mining:
Понимание и формулировка задачи анализа. На этом этапе происходит осмысление поставленной задачи и уточнение целей, которые должны быть достигнуты методами DM. Правильно сформулированные цели и адекватно выбранные для их достижения методы в значительной степени определяют эффективность всего процесса.
Подготовка данных для автоматизированного анализа; то есть приведение данных к форме, пригодной для применения конкретных выбранных методов
DM.
Применение методов DM и построение моделей. Сценарии применения могут быть самыми различными и включать сложную комбинацию разных методов.
Проверка построенных моделей; что дает судить об адекватности построенной модели.
30