

9068
.pdfИнтерпретация. В случае, когда извлеченные зависимости и шаблоны непро-
зрачны для пользователя, должны существовать методы постобработки, позволяю-
щие привести их к интерпретируемому виду. Для оценки качества полученной мо-
дели нужно использовать как формальные методы, так и знания аналитика. Именно аналитик может сказать, насколько применима полученная модель к реальным дан-
ным. Построенные модели являются, по сути, формализованными знаниями экспер-
та, а следовательно, их можно тиражировать. Найденные знания должны быть при-
менимы и к новым данным с некоторой степенью достоверности.
Data Mining – это не один метод, а совокупность большого числа различных методов обнаружения знаний. Существует несколько условных классификаций за-
дач Data Mining. Мы будем говорить о четырех базовых классах задач.
1.Классификация – это установление зависимости дискретной выходной переменной от входных переменных.
2.Регрессия – это установление зависимости непрерывной выходной пере-
менной от входных переменных.
3. Кластеризация – это группировка объектов (наблюдений, событий) на основе данных, описывающих свойства объектов. Объекты внутри кластера должны быть похожими друг на друга и отличаться от других, которые вошли в другие кла-
стеры.
4.Ассоциация – выявление закономерностей между связанными событи-
ями. Примером такой закономерности служит правило, указывающее, что из собы-
тия X следует событие Y. Такие правила называются ассоциативными. Впервые эта задача была предложена для нахождения типичных шаблонов покупок, совершае-
мых в супермаркетах, поэтому иногда ее называют анализом рыночной корзины
(market basket analysis). Если же нас интересует последовательность происходящих событий, то можно говорить о последовательных шаблонах – установлении законо-
мерностей между связанными во времени событиями. Примером такой закономер-
ности служит правило, указывающее, что из события X спустя время t последует со-
бытие Y.
11
Кроме перечисленных задач, часто выделяют анализ отклонений (deviation detection), анализ связей (link analysis), отбор значимых признаков (feature selection), хотя эти задачи граничат с очисткой и визуализацией данных.
Задача классификации отличается от задачи регрессии тем, что в классифика-
ции на выходе присутствует переменная дискретного вида, называемая меткой клас-
са. Решение задачи классификации сводится к определению класса объекта по его признакам, при этом множество классов, к которым может быть отнесен объект, из-
вестно заранее. В задаче регрессии выходная переменная является непрерывной – множеством действительных чисел, например сумма продаж. К задаче регрессии сводится, в частности, прогнозирование временного ряда на основе исторических данных.
Кластеризация отличается от классификации тем, что выходная переменная не требуется, а число кластеров, в которые необходимо сгруппировать все множество данных, может быть неизвестным. Выходом кластеризации является не готовый от-
вет (например, плохо/удовлетворительно/хорошо), а группы похожих объектов – кластеры. Кластеризация указывает только на схожесть объектов, и не более того.
Для объяснения образовавшихся кластеров необходима их дополнительная интер-
претация.
Перечислим наиболее известные применения этих задач в экономике.
Классификация используется, если заранее известны класс, например, при отнесении нового товара к той или иной товарной группе, клиента к какой-либо ка-
тегории (при кредитовании – по каким-то признакам к одной из групп риска).
Регрессия используется для установления зависимостей между факторами.
Например, в задаче прогнозирования зависимая величина – объемы продаж, а фак-
торами, влияющими на нее, могут быть предыдущие объемы продаж, изменение курсов валют, активность конкурентов и т. д. Или, например, при кредитовании фи-
зических лиц вероятность возврата кредита зависит от личных характеристик чело-
века, сферы его деятельности, наличия имущества.
Кластеризация может использоваться для сегментации и построения профи-
12

лей клиентов. При достаточно большом количестве клиентов становится трудно подходить к каждому индивидуально, поэтому их удобно объединять в группы – сегменты с однородными признаками. Выделять сегменты можно по нескольким группам признаков, например по сфере деятельности, по географическому располо-
жению. После кластеризации можно узнать, какие сегменты наиболее активны, ка-
кие приносят наибольшую прибыль, выделить характерные для них признаки. Эф-
фективность работы с клиентами повышается благодаря учету их персональных предпочтений.
Ассоциативные правила помогают выявлять совместно приобретаемые то-
вары. Это может быть полезно для более удобного размещения товара на прилавках,
стимулирования продаж. Тогда человек, купивший пачку спагетти, не забудет ку-
пить к ней бутылочку соуса.
Последовательные шаблоны могут использоваться при планировании продаж или предоставления услуг. Они похожи на ассоциативные правила, но в анализе до-
бавляется временной показатель, то есть важна последовательность совершения операций. Например, если заемщик взял потребительский кредит, то с вероятностью
60 % через полгода он оформит кредитную карту.
статистика
теория информации
Data |
машинное |
Искусственный |
|
обучение |
|||
Mining |
интеллект |
||
|
|||
|
|
Базы |
|
|
дан- |
KDD |
методы оптимизации |
|
|
Рис. 2. Мультидисциплинарный характер Data Mining
Для решения вышеперечисленных задач используются различные методы и
13
алгоритмы Data Mining. Ввиду того что Data Mining развивается на стыке таких дисциплин, как математика, статистика, теория информации, машинное обучение,
теория баз данных, программирование, параллельные вычисления, вполне законо-
мерно, что большинство алгоритмов и методов Data Mining были разработаны на основе подходов, применяемых в этих дисциплинах (рис. 2).
В общем случае непринципиально, каким именно алгоритмом будет решаться задача, главное – иметь метод решения для каждого класса задач.
На сегодняшний день наибольшее распространение в Data Mining получили методы машинного обучения: деревья решений, нейронные сети, ассоциативные правила и т. д. Отметим, что Data Mining не ограничивается алгоритмами решения упомянутых классов задач. Существует несколько современных подходов, которые
«встраиваются» внутрь алгоритмов машинного обучения, придавая им новые свой-
ства. Так, генетические алгоритмы призваны эффективно решать задачи оптимиза-
ции, поэтому их можно встретить в процедурах обучения нейронных сетей, карт Кохонена, логистической регрессии, при отборе значимых признаков.
Математический аппарат нечеткой логики (fuzzy logic) также успешно включа-
ется в состав практически всех алгоритмов Data Mining; так появились нечеткие нейронные сети, нечеткие деревья решений, нечеткие ассоциативные правила. дан-
ных и нечетких запросов позволяет аналитикам получать нечеткие срезы. И подоб-
ных примеров множество.
Основные этапы решения задач методами Data Mining:
Понимание и формулировка задачи анализа. На этом этапе происходит осмысление поставленной задачи и уточнение целей, которые должны быть достигнуты методами DM. Правильно сформулированные цели и адекватно выбранные для их достижения методы в значительной степени определяют эффективность всего процесса.
Подготовка данных для автоматизированного анализа; то есть приведение данных к форме, пригодной для применения конкретных выбранных методов
DM.
14
Применение методов DM и построение моделей. Сценарии применения могут быть самыми различными и включать сложную комбинацию разных методов.
Проверка построенных моделей; что дает судить об адекватности построенной модели.
Интерпретация моделей человеком с целью их использования для принятия решений, добавления полученных правил и зависимостей в базы знаний.
Каждый из алгоритмов Data Mining использует определенный подход к визуа-
лизации:
1.Для деревьев решений это визуализатор дерева решений, список правил, таб-
лица сопряженности.
2.Для нейронных сетей в зависимости от инструмента это может быть тополо-
гия сети, график изменения величины ошибки, демонстрирующий процесс обучения, таблица сопряженности или диаграммы рассеивания.
3.Для линейной регрессии в качестве визуализатора выступает линия регрессии,
диаграммы рассеивания.
4.Для кластеризации – дендрограммы, карты Кохонена.
2.3.2.Раздел 2. Оперативная аналитическая обработка данных OLAP.
OLAP (OnLine Analytical Processing, оперативная аналитическая обработка дан-
ных) является на сегодня одним из самых популярных методов анализа данных. Его основное назначение – поддержка аналитической деятельности, а также произволь-
ных (нерегламентированных) запросов лиц, принимающих решения. На основе
OLAP строятся многочисленные системы поддержки принятия решений и подготов-
ки отчетов.
Эта технология позволяет осуществлять многомерный анализ данных. Она мо-
жет применяться не только для подготовки отчетности, но и для первичной провер-
ки гипотез об изучаемой предметной области. Такие гипотезы неизбежно возникают в процессе анализа; для выработки качественных решений они должны быть прове-
рены на основе имеющейся информации.
15
Средства OLAP-системы должны обеспечить работу с данными в многомерном представлении данных – естественном на уровне ненормализованной ER-модели с полной поддержкой иерархий независимо от того, какие типы баз данных исполь-
зуются в качестве источников.
ВOLAP-системах предварительно подготовленная информация преобразуется
вформу многомерного куба; такими данными гораздо легче манипулировать, ис-
пользуя необходимые для анализа срезы (рис. 3.4).
Многомерный куб можно рассматривать как систему координат, осями которой являются измерения, например, Дата, Товар, Покупатель. По осям будут отклады-
ваться значения измерений – даты, наименования товаров, названия фирм-
покупателей, ФИО физических лиц и т. д.
Втакой системе каждому набору значений измерений (например, дата – товар
–покупатель) будет соответствовать ячейка, в которой можно разместить числовые показатели (то есть факты), связанные с данным набором. Таким образом, между объектами бизнес-процесса и их числовыми характеристиками будет установлена однозначная связь.
Принцип организации многомерного куба поясняется на рис. 4.
16

Рис. 4. Принцип организации многомерного куба
Рис. 5. Измерения и факты в многомерном кубе.
Многомерный взгляд на измерения Дата, Товар и Покупатель представлен на рис. 5. Фактами в данном случае являются Цена, Количество, Сумма. Выделенный
17
сегмент содержит информацию о том, сколько плит, на какую сумму и по какой цене приобрела фирма ЗАО «Строитель» 3 ноября.
Визуализация OLAP-куба производится с помощью специального вида таб-
лиц, которые строятся на основе срезов OLAP-куба, содержащих необходимую пользователю информацию. Срезы, в свою очередь, являются результатом выполне-
ния соответствующего запроса к базе данных. Как правило, в процессе построения срезов пользователь с помощью мыши и клавиатуры манипулирует заголовками из-
мерений, добиваясь наиболее информативного представления данных в кубе. В за-
висимости от положения заголовков измерений в таблице автоматически формиру-
ется запрос к базе или хранилищу данных. Запрос извлекает данные из базы или хранилища, после чего OLAP-ядро системы визуализирует их.
Общую схему работы настольной OLAP системы можно представить следу-
ющим образом:
Рис. 6. Технология OLAP
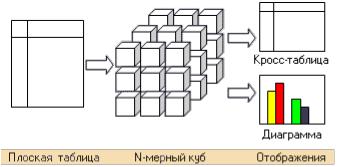
Алгоритм работы следующий:
1.Получение данных в виде плоской таблицы или результата выполнения SQL
запроса.
2.Кэширование данных и преобразование их к многомерному кубу.
3.Отображение построенного куба при помощи кросс-таблицы или диаграммы и т.п. В общем случае, к одному кубу может быть подключено произвольное ко-
личество отображений.
Отображения, используемые в OLAP системах, чаще всего бывают двух видов
–кросс-таблицы и кросс-диаграммы. Кросс-таблица является основным и наиболее распространенным способом отображения куба. Она отличается от обычной плос-
18
кой таблицы наличием нескольких уровней вложенности (например, она допускает разбиение строк на подстроки, а столбцов – на подстолбцы). Кросс-диаграмма пред-
ставляет собой диаграмму заданного типа (гистограмму, линейную диаграмму и т.д.), построенную на основе кросс-таблицы. Основное отличие кросс-диаграммы от обычной диаграммы в том, что она однозначно соответствует текущему состоянию куба и при любых его изменениях (транспонирование, фильтрация по измерениям и т.д.) также синхронно изменяется.
OLAP-куб можно использовать не только как метод визуализации, но и как средство оперативного формирования отчетов и представления информации в нуж-
ном разрезе (так называемая аналитическая отчетность).
OLAP-куб позволяет анализировать данные сразу по нескольким измерениям,
т.е. выполнять многомерный анализ. Пользователь, анализирующий информацию,
может «резать» куб по разным направлениям, получать сводные (например, по го-
дам) или, наоборот, детальные (по неделям) сведения и осуществлять прочие мани-
пуляции, которые необходимы ему в процессе анализа. В анализе может использо-
ваться любое число измерений, каждое из которых будет представлено новой осью.
Конечно, для OLAP-куба с размерностью больше трех геометрическая интерпрета-
ция не имеет смысла (тем более что речь идет не о реальном, а об информационном пространстве).
Следует отметить, что задача расчета и визуализации куба с большим числом измерений, во-первых, может потребовать слишком больших вычислительных ре-
сурсов, а во-вторых, ее содержательная интерпретация весьма затруднительна. Как правило, человек не способен анализировать больше 5-7 измерений одновременно.
Поэтому сложные задачи, требующие анализа данных большой размерности, следу-
ет по возможности сводить к нескольким более простым.
Визуализация и отчеты в Deductor Studio
На верхнем уровне принятия решений значение имеет не точность цифр, а
закономерности, поэтому визуализация результатов анализа в виде OLAP–отчетов,
графиков, карт и диаграмм – наиболее оптимальный вариант отображения
19
статистической информации, который позволяет на уровне простых обобщений получить агрегированные данные на текущий момент и спланировать динамику на ближайшее время.
В АП Deductor предусмотрены следующие способы визуализации данных:
OLAP-кубы, диаграммы, графики, гистограммы, статистика, правила, матрицы классификации, диаграммы рассеяния, ретропрогноз, карты Кохонена, профили кла-
стеров.
Визуализаторы общего назначения рассматривались в разделе «Базовые навы-
ки работы Deductor Studio Academic». Визуализаторы для иллюстрации построения и оценки качества аналитических моделей будут использоваться в разделе «Модели
Data Mining». Рассмотрим OLAP-кубы – визуализаторы, которые чаще всего ис-
пользуются в отчетах.
Аналитическая отчетность (отчеты) – это одно из средств визуализации и кон-
солидации результатов анализа данных для конечного пользователя (для лиц, при-
нимающих решения). Аналитическая отчетность обеспечивает быстрый доступ к ре-
зультатам анализа, не требуя от пользователя навыков анализа данных и работы в АП Deductor. При работе с отчетами пользователь не видит сценарий анализа дан-
ных, ему доступны только конечные результаты (выдержки) из работы аналитика.
Для построения аналитической отчетности в АП Deductor предназначена вкладка Отчеты, cпособ открытия: «Вид – Отчеты» или кнопка  , после нажатия на которую, в рабочей части экрана появится панель Отчеты.
, после нажатия на которую, в рабочей части экрана появится панель Отчеты.
Отчеты строятся в виде древовидного иерархического списка (рис. 7), каждым узлом которого является отдельный отчет или папка, содержащая несколько отче-
тов. Каждый узел дерева отчетности связан со своим узлом в дереве сценария. Для каждого отчета настраивается свой способ отображения (таблица, гистограмма,
кросс таблица, кросс диаграмма и т.п.). Это удобно, так как несколько отчетов могут быть связаны с одним узлом дерева сценария.
20