

8249
.pdf101
нормальной формы (2NF), и в нем отсутствуют транзитивные зависимости неключевых атрибутов от ключа. В большинстве случаев третья нормальная форма служит компромиссом между полной нормализацией и функциональностью в совокупности с легкостью реализации. Как было отмечено выше, существуют нормальные формы, выше третьей (3NF), но на практике они затрудняют разработку структур данных и снижают их функциональность.
Рассмотрим пример приведения отношения к третьей нормальной форме. Пусть небольшой фирме, занимающейся продажей комплектующих для компьютеров, требуется сохранять данные о заказах. Эти данные включают:
1)дату заказа;
2)номер заказа;
3)артикул (уникальный номер единицы товара);
4)наименование товара;
5)цену заказанного товара.
Нам необходимо нормализовать приведенную ниже таблицу. Заметим, что она уже находится в 1NF, так как все ее атрибуты атомарны. В СУБД дата - неделимый тип данных, поэтому, хотя дата заказа и состоит из 3 чисел, это - атомарный атрибут.
Дата |
Номер |
Артикул |
Наименование |
Цена |
|
заказа |
|
|
|
01.09.98 |
1 |
1672 |
Процессор Pentium 233 MMX |
1638 |
01.09.98 |
1 |
5301 |
M/B SOYO SY-5EAS ETEQ-6618 |
300 |
01.09.98 |
1 |
1611 |
DIMM 32 Mb |
420 |
01.09.98 |
1 |
58 |
SVGA PCI 1Mb S3 TRIO 64+ |
192 |
01.09.98 |
2 |
1672 |
Процессор Pentium 233 MMX |
1638 |
01.09.98 |
2 |
1611 |
DIMM 32 Mb |
420 |
02.09.98 |
1 |
58 |
SVGA PCI 1Mb S3 TRIO 64+ |
192 |
02.09.98 |
1 |
3417 |
Процессор Pentium II 333 |
3876 |
02.09.98 |
1 |
1611 |
DIMM 32 Mb |
420 |
02.09.98 |
2 |
2660 |
SVGA AGP S3 86C357 |
396 |
В одном заказе может оказаться несколько одинаковых наименований товара, например, можно заказать два одинаковых процессора, поэтому составной атрибут «Дата-НомерЗаказа-Артикул» не может быть первичным ключом. Для того чтобы выполнить требования второй нормальной формы, надо добавить к таблице атрибут, который бы однозначно идентифицировал каждую единицу товара, входящую в заказ. Назовем такой атрибут «ID». Вот приведенное выше отношение в 2NF.
ID |
Дата |
Номер |
Арти- |
Наименование |
Цена |
|
|
заказа |
кул |
|
|
1 |
01.09.98 |
1 |
1672 |
Процессор Pentium 233 MMX |
1638 |
2 01.09.98 1 |
5301 M/B SOYO SY-5EAS ETEQ-6618 300 |
102
3 |
01.09.98 |
1 |
1611 |
DIMM 32 Mb |
420 |
4 |
01.09.98 |
1 |
58 |
SVGA PCI 1Mb S3 TRIO 64+ |
192 |
5 |
01.09.98 |
2 |
1672 |
Процессор Pentium 233 MMX |
1638 |
6 |
01.09.98 |
2 |
1611 |
DIMM 32 Mb |
420 |
7 |
02.09.98 |
1 |
58 |
SVGA PCI 1Mb S3 TRIO 64+ |
192 |
8 |
02.09.98 |
1 |
3417 |
Процессор Pentium II 333 |
3876 |
9 |
02.09.98 |
1 |
1611 |
DIMM 32 Mb |
420 |
10 |
02.09.98 |
2 |
2660 |
SVGA AGP S3 86C357 |
396 |
В этой таблице все атрибуты зависят от атрибута ID, но, кроме того, есть зависимость «Наименования» и «Цены» от «Артикула». Требование независимости атрибутов отношения не выполняются (3NF). Для приведения отношения в третью нормальную форму таблицу требуется разбить на три отношения.
Нормализация отношений – не пустая трата времени. Пусть в приведенном примере требуется изменить «Наименование» с «DIMM 32 Mb» на «DIMM 32 Mb SDRAM». В ненормализованном отношении пришлось бы искать и редактировать все строки, содержащие это наименование, а в нормализованной БД изменяется только одна строка одного отношения.
Подробнее с процессом нормализации и с требованиями нормальных форм старше третьей (3NF) можно ознакомиться в литературе по теории
реляционных БД. |
|
|
|
|
|
|||
|
ID |
|
Дата |
|
Номер заказа |
|
Артикул |
|
|
1 |
|
01.09.98 |
1 |
|
1672 |
|
|
|
2 |
|
01.09.98 |
1 |
|
5301 |
|
|
|
3 |
|
01.09.98 |
1 |
|
1611 |
|
|
|
4 |
|
01.09.98 |
1 |
|
58 |
|
|
|
5 |
|
01.09.98 |
2 |
|
1672 |
|
|
|
6 |
|
01.09.98 |
2 |
|
1611 |
|
|
|
7 |
|
02.09.98 |
1 |
|
58 |
|
|
|
8 |
|
02.09.98 |
1 |
|
3417 |
|
|
|
9 |
|
02.09.98 |
1 |
|
1611 |
|
|
10 |
|
02.09.98 |
2 |
|
2660 |
|
||
|
Артикул |
|
|
Наименование |
|
|
||
|
|
|
|
|
||||
|
1672 |
|
|
|
Процессор Pentium 233 MMX |
|
||
|
5301 |
|
|
|
M/B SOYO SY-5EAS ETEQ-6618 |
|
||
|
1611 |
|
|
|
DIMM 32 Mb |
|
|
|
|
58 |
|
|
|
SVGA PCI 1Mb S3 TRIO 64+ |
|
||
|
3417 |
|
|
|
Процессор Pentium II 333 |
|
||
2660 |
|
|
|
SVGA AGP S3 86C357 |
|
|||
|
Артикул |
|
|
|
|
Цена |
|
|
|
|
|
|
|
|
|||
|
1672 |
|
|
|
|
|
1638 |
|
5301 |
|
|
|
|
|
300 |
|
|
|
103 |
1611 |
|
420 |
|
58 |
192 |
3417 |
3876 |
2660 |
396 |
8.6. Средства ускорения доступа к данным
Современным СУБД приходится оперировать огромными массивами информации, объемы которых достигают порой десятков терабайт. Выполняя запросы тысяч пользователей, они должны обеспечить небольшое, не более нескольких секунд, время отклика. СУБД не сможет эффективно работать в таких условиях, не используя методов ускорения выборки данных. Цель этих методов - избежать полного перебора строк таблиц БД при выполнении реляционных операций, например, при соединении отношений или поиске строк, удовлетворяющих условию.
В современных СУБД используются два основных метода ускорения доступа к данным: индексирование и хеширование. Эти методы обеспечивают лучшее по сравнению с остальными время поиска и модификации таблиц БД.
Метод индексирования основан на использовании индексов. Индекс отношения очень похож на предметный указатель книги. В таком указателе приведен список упорядоченных по алфавиту терминов, которые встречаются в книге. Каждому термину сопоставлена страница или страницы, где он встречается. Обычно предметный указатель занимает не более нескольких страниц. Если нам требуется найти место в книге, где термин раскрывается, мы находим его в предметном указателе, это легко сделать - указатель невелик, кроме того, все термины там упорядочены по алфавиту. Затем мы читаем номер страницы, соответствующий термину, раскрываем книгу на ней и находим нужный нам абзац. Если бы предметный указатель отсутствовал, нам пришлось бы пролистывать все страницы, чтобы найти интересующее нас место, и мы бы потратили значительно больше времени.
Индекс базы данных - не листы бумаги, это - специальная структура данных, создаваемая автоматически или по запросу пользователя. В целом работа с ним выглядит так же, как и с предметным указателем. Разница лишь в том, что СУБД все делает автоматически, пользователь может даже не знать, что она использует индекс. В книге приводится предметный указатель слов, в БД для формирования индекса может быть использован любой атрибут отношения, в том числе и составной. В индексе значения атрибута хранятся упорядоченно (по возрастанию или убыванию), каждому значению соответствует указатель на строку отношения, которое его содержит (аналог номера страницы в предметном указателе). Индекс занимает значительно меньший, чем таблица, объем, поэтому даже полный перебор значений в нем потребует меньше времени, чем считывание и поиск информации в отношении. Кроме того, значения в индексе хранятся упорядоченно, что позволяет резко ускорить поиск нужной строки. Индексы позволяют выбирать строки отношений, значения индексируемого атрибута которых принадлежит некоторому заданному интервалу.
104
Для одного отношения может быть создано несколько индексов. Если разные отношения содержат одинаковые атрибуты, то для них может быть сформирован мультииндекс. В нем каждому значению общего атрибута соответствует несколько ссылок, каждая из которых указывает на строку с таким значением в том или ином отношении. Мультииндексы применяются для оптимизации выполнения операции соединения отношений.
Еще один интересный подход, применяемый для повышения эффективности доступа к данным, - хеширование (hashing). Для метода хеширования, к сожалению, нет житейского аналога, поэтому объяснить его «на пальцах» вряд ли получится. Основная идея хеширования - организация ассоциативной памяти для хранения строк таблицы с определением места строки в таблице по значениям одного или нескольких ее ключевых атрибутов. Место строки вычисляется хэш-функцией, аргументы которой - значения атрибутов, а результат - целое число в диапазоне номеров строк таблицы. Идеальная хэш-функция должна давать разные значения номеров строк для разных ключевых атрибутов. Однако построить такую хэш-функцию - дело трудоемкое и не всегда возможное.
На практике используются, как правило, простые хэш-функции. Для целочисленных атрибутов в качестве хэш-функции может быть использован, например, остаток от деления на простое число:
f(k) = k mod p,
где f - хэш-функция, k - целочисленный атрибут, а р - простое число. Если ключевой атрибут - строка символов, то для вычисления хэш-
функции выбирается наиболее подходящий в конкретной ситуации метод преобразования строки в число, например, вычисление контрольной суммы.
Доступ к данным при хешировании производится так. В начале работы с БД таблица состоит из пустых строк. Когда строка с данными заносится в таблицу, вычисляется значение хэш-функции для ее атрибутов, и результат трактуется как номер строки отношения, в которую она должна быть записана. Если эта строка уже занята, то по некоторому алгоритму производится проверка следующих строк таблицы до тех пор, пока не будет обнаружено свободное место (при этом, как правило, считается, что таблица имеет кольцевую структуру). В это место и помещается записываемая строка. Для поиска данных используется аналогичный алгоритм. Сначала вычисляется значение хэш-функции для требуемого значения ключевого атрибута и проверяется строка таблицы, номер которой вычислен хэш-функцией. Если значение атрибута, по которому происходит доступ, соответствует значению ключа строки, то поиск заканчивается. В противном случае проверяются следующие строки таблицы до обнаружения кортежа с нужным значением или пустой строки. Пустая строка свидетельствует об отсутствии кортежа с нужным значением ключа в таблице - процедура занесения данных обязательно бы использовала ее, если бы требуемый кортеж существовал.
Если таблица заполнена не более чем на 60%, то для размещения в ней новой строки необходимо проверить в среднем не более двух ячеек. Иногда для устранения конфликтов (коллизий), возникающих, если хэшфункция выдает номер занятой строки, используют не линейный просмотр, а

105
более сложные методы. Скорость обращения к данным при этом возрастает. Хеширование может использоваться для поиска строк по точному
совпадению значения атрибута кортежа с нужным значением ключа.
8.7. Язык запросов
База данных бесполезна, если отсутствуют средства доступа к информации в ней. Для получения информации из БД пользователи направляют СУБД запросы. СУБД обрабатывает их и отправляет результаты обработки пользователям. Запросы формулируются на специальном «языке запросов». Фактическим стандартом такого языка для современных реляционных СУБД стал SQL (Structured Query Language - структурный язык запросов).
Этот язык имеет официальный стандарт, последняя версия которого была принята ANSI и ISO в 1992 году. Большинство разработчиков СУБД придерживаются этого стандарта. Тем не менее они часто расширяют его для реализации специальных возможностей обработки данных. SQL - это не язык программирования в традиционном смысле. Это язык запросов к базе данных. С его помощью можно сформулировать, какие данные требуется получить, но невозможно определить, как это следует сделать. На SQL не пишутся программы - в нем отсутствуют многие операторы процедурных языков программирования, например, операторы проверки условия (if...then...else), операторы циклов и др. Для того чтобы использовать SQL в приложениях, работающих с БД, необходимо использовать библиотеки подпрограмм, позволяющие встраивать запросы на SQL в текст на С или Pascal. В современных СУБД имеются свои средства, позволяющие разрабатывать прикладные программы с применением SQL и средств управления интерфейсом с пользователем.
Запросы на языке SQL строятся с использованием одного или нескольких операторов. Операторы разделяются символом перевода строки или точкой с запятой. В таблице 8.1 перечислены некоторые операторы, входящие в текущий стандарт языка SQL.
Стандарт языка SQL определяет также типы данных, которые можно использовать при создании БД и работе с ней. В таблице 8.2 перечислены основные типы данных, используемые в SQL, а также указаны соответствующие им типы языка С.
Таблица 8.1.
Оператор |
Назначение |
SELECT |
Выбрать данные из БД |
INSERT |
Добавить данные в БД |
UPDATE |
Обновить данные в БД |
DELETE |
Удалить данные из БД |
GRANT |
Предоставить привилегии пользователю |
REVOKE |
Отменить привилегии пользователя |
COMMIT |
Зафиксировать текущую транзакцию |
106
ROLLBACK |
Прервать текущую транзакцию |
|
|
Таблица 8.2. |
|
|
|
Тип данных SQL/92 |
Описание |
Тип языка |
|
|
|
С |
|
CHARACTER |
Стока символов фиксированной |
char[] |
|
|
длины |
|
|
INTEGER |
Целое число |
long |
|
SMALLINT |
Целое число |
short |
|
REAL |
Число с плавающей запятой |
float |
|
DOUBLE PRECISION |
Число с плавающей запятой |
double |
|
|
двойной точности |
|
|
В стандарте SQL определяются также некоторые специальные типы:
1)денежные единицы (MONEY);
2)дата (DATE) и время (TIME);
3)числовые типы, для которых задается масштаб и точность
(FLOAT, NUMERIC, DECIMAL).
С использованием SQL можно определить отношения, содержащие данные любого из перечисленных типов, однако для использования этих данных в приложениях, написанных на стандартных языках программирования (С, Pascal), требуются специальные средства – в этих языках нет многих типов данных SQL.
Контрольные вопросы:
1.Дайте определение документальной информационной системы.
2.Дайте определение фактографической информационной системы.
3.Дайте определение термину «база данных».
4.Перечислите основные модели данных. Приведите примеры.
5.Перечислите и опишите основные операции реляционной алгебры, реализуемые в СУБД.
6.Опишите метод нормализации отношений, применяемый при проектировании баз данных.
7.Перечислите и опишите основные методы ускорения доступа к данным.
8.Что такое запросы и для чего они служат?
9. Локальные и глобальные сети ЭВМ
9.1. От централизованных систем – к вычислительным сетям
Концепция вычислительных сетей является логическим результатом эволюции компьютерной технологии. Первые компьютеры 50-х годов — большие, громоздкие и дорогие — предназначались для очень небольшого
107
числа избранных пользователей. Часто эти монстры занимали целые здания. Такие компьютеры не были предназначены для интерактивной работы пользователя, а использовались в режиме пакетной обработки.
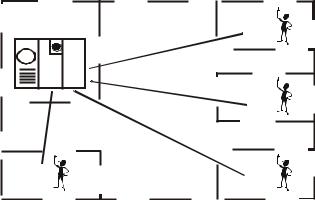
Системы пакетной обработки, как правило, строились на базе мэйнфрейма — мощного и надежного компьютера универсального назначения. Пользователи подготавливали перфокарты, содержащие данные и команды программ, и передавали их в вычислительный центр. Операторы вводили эти карты в компьютер, а распечатанные результаты пользователи получали обычно только на следующий день (рис. 9.1). Таким образом, одна неверно
набитая карта означала как минимум суточную задержку.
Предприятие
ВЦ на базе мэйнфрейма
Рис. 9.1. Централизованная система на базе мэйнфрейма
Конечно, для пользователей интерактивный режим работы, при котором можно с терминала оперативно руководить процессом обработки своих данных, был бы гораздо удобней. Но интересами пользователей на первых этапах развития вычислительных систем в значительной степени пренебрегали, поскольку пакетный режим — это самый эффективный режим использования вычислительной мощности, так как он позволяет выполнить в единицу времени больше пользовательских задач, чем любые другие режимы. Во главу угла ставилась эффективность работы самого дорогого устройства вычислительной машины — процессора, в ущерб эффективности работы использующих его специалистов.
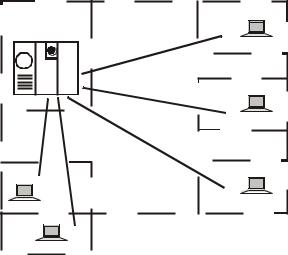
По мере удешевления процессоров в начале 60-х годов появились новые способы организации вычислительного процесса, которые позволили учесть интересы пользователей. Начали развиваться интерактивные многотерминальные системы разделения времени (рис. 9.2). В таких системах компьютер отдавался в распоряжение сразу нескольким пользователям. Каждый пользователь получал в свое распоряжение терминал, с помощью которого он мог вести диалог с компьютером. Причем время реакции вычислительной системы было достаточно мало для того, чтобы пользователю
108
была не слишком заметна параллельная работа с компьютером и других пользователей. Разделяя таким образом компьютер, пользователи получили возможность за сравнительно небольшую плату пользоваться преимуществами компьютеризации.
Предприятие
ВЦ на базе мэйнфрейма
Удаленное
подразделение
Рис. 9.2. Многотерминальная система — прообраз вычислительной
сети
Терминалы, выйдя за пределы вычислительного центра, рассредоточились по всему предприятию. И хотя вычислительная мощность оставалась полностью централизованной, некоторые функции — такие как ввод и вывод данных — стали распределенными. Такие многотерминальные централизованные системы внешне уже были очень похожи на локальные вычислительные сети. Действительно, рядовой пользователь работу за терминалом мэйнфрейма воспринимал примерно так же, как сейчас он воспринимает работу за подключенным к сети персональным компьютером. Пользователь мог получить доступ к общим файлам и периферийным устройствам, при этом у него поддерживалась полная иллюзия единоличного владения компьютером, так как он мог запустить нужную ему программу в любой момент и почти сразу же получить результат. (Некоторые, далекие от вычислительной техники пользователи даже были уверены, что все вычисления выполняются внутри их дисплея.)
Таким образом, многотерминальные системы, работающие в режиме разделения времени, стали первым шагом на пути создания локальных вычислительных сетей. Но до появления локальных сетей нужно было пройти еще большой путь, так как многотерминальные системы, хотя и имели
109
внешние черты распределенных систем, все еще сохраняли централизованный характер обработки данных. С другой стороны, и потребность предприятий в создании локальных сетей в это время еще не созрела — в одном здании просто нечего было объединять в сеть, так как из-за высокой стоимости вычислительной техники предприятия не могли себе позволить роскошь приобретения нескольких компьютеров. В этот период был справедлив так называемый «закон Гроша», который эмпирически отражал уровень технологии того времени. В соответствии с этим законом производительность компьютера была пропорциональна квадрату его стоимости, отсюда следовало, что за одну и ту же сумму было выгоднее купить одну мощную машину, чем две менее мощных — их суммарная мощность оказывалась намного ниже мощности дорогой машины.
Тем не менее, потребность в соединении компьютеров, находящихся на большом расстоянии друг от друга, к этому времени вполне назрела. Началось все с решения более простой задачи — доступа к компьютеру с терминалов, удаленных от него на многие сотни, а то и тысячи километров. Терминалы соединялись с компьютерами через телефонные сети с помощью модемов. Такие сети позволяли многочисленным пользователям получать удаленный доступ к разделяемым ресурсам нескольких мощных компьютеров класса суперЭВМ. Затем появились системы, в которых наряду с удаленными соединениями типа терминал — компьютер были реализованы и удаленные связи типа компьютер — компьютер. Компьютеры получили возможность обмениваться данными в автоматическом режиме, что, собственно, и является базовым механизмом любой вычислительной сети. Используя этот механизм, в первых сетях были реализованы службы обмена файлами, синхронизации баз данных, электронной почты и другие, ставшие теперь традиционными сетевые службы.
Таким образом, хронологически первыми появились глобальные вычислительные сети. Именно при построении глобальных сетей были впервые предложены и отработаны многие основные идеи и концепции современных вычислительных сетей. Такие, например, как многоуровневое построение коммуникационных протоколов, технология коммутации пакетов, маршрутизация пакетов в составных сетях.
В начале 70-х годов произошел технологический прорыв в области производства компьютерных компонентов — появились большие интегральные схемы. Их сравнительно невысокая стоимость и высокие функциональные возможности привели к созданию мини-компьютеров, которые стали реальными конкурентами мэйнфреймов. Закон Гроша перестал соответствовать действительности, так как десяток мини-компьютеров выполнял некоторые задачи (как правило, хорошо распараллеливаемые) быстрее одного мэйнфрейма, а стоимость такой мини-компьютерной системы была меньше.
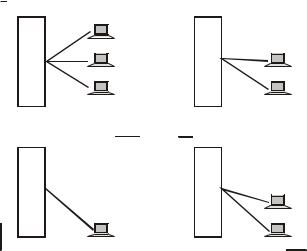
Даже небольшие подразделения предприятий получили возможность покупать для себя компьютеры. Мини-компьютеры выполняли задачи управления технологическим оборудованием, складом и другие задачи уровня подразделения предприятия. Таким образом, появилась концепция
110
распределения компьютерных ресурсов по всему предприятию. Однако при этом все компьютеры одной организации по-прежнему продолжали работать автономно (рис. 9.3).
Предприятие
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Мини-ЭВМ Терминалы |
|
|
|
|
Мини-ЭВМ Терминалы |
|||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 9.3. Автономное использование нескольких мини-компьютеров на одном предприятии
Но шло время, потребности пользователей вычислительной техники росли, им стало недостаточно собственных компьютеров, им уже хотелось получить возможность обмена данными с другими близко расположенными компьютерами. В ответ на эту потребность предприятия и организации стали соединять свои мини-компьютеры вместе и разрабатывать программное обеспечение, необходимое для их взаимодействия. В результате появились первые локальные вычислительные сети (рис. 9.4). Они еще во многом отличались от современных локальных сетей, в первую очередь — своими устройствами сопряжения. На первых порах для соединения компьютеров друг с другом использовались самые разнообразные нестандартные устройства со своим способом представления данных на линиях связи, своими типами кабелей и т. п. Эти устройства могли соединять только те типы компьютеров, для которых были разработаны, — например, мини-компьютеры PDP-11 с мэйнфреймом IBM 360 или компьютеры «Наири» с компьютерами «Днепр». Такая ситуация создала большой простор для творчества студентов — названия многих курсовых и дипломных проектов начинались тогда со слов «Устройство сопряжения...».