Лабы / статграф лаба 4
.docЛабораторная работа № 4
Построение регрессионной модели системы двух случайных величин
Цель работы: изучить основные методы регрессионного и корреляционного анализа; исследовать зависимость между двумя случайными величинами, заданными выборками.
Задание: по виду корреляционного поля сделать предположение о форме регрессионной зависимости между двумя случайными величинами; используя метод наименьших квадратов, найти параметры уравнения регрессии; оценить качество описания зависимости полученным уравнением регрессии.
Пример. По результатам тридцати измерений веса грузового поезда, т, и соответствующего времени нахождения поезда на участке Y, ч, представленных в таблице 4.3, следует исследовать зависимость между данными величинами.
Необходимо определить коэффициенты уравнения регрессии методом наименьших квадратов, оценить тесноту связи между величинами, проверить значимость коэффициента корреляции и спрогнозировать время нахождения поезда на участке при заданном весе поезда (5200 т).
Решение. На величину времени нахождения поезда на участке Y, помимо веса X, влияние оказывает качество железнодорожного полотна, качество подвижного состава, топливо и другие факторы. Поэтому зависимость между величиной времени нахождения поезда на участке Y и веса поезда X является статистической: при одном весе поезда при различных дополнительных условиях время нахождения поезда на участке может принимать различные значения.
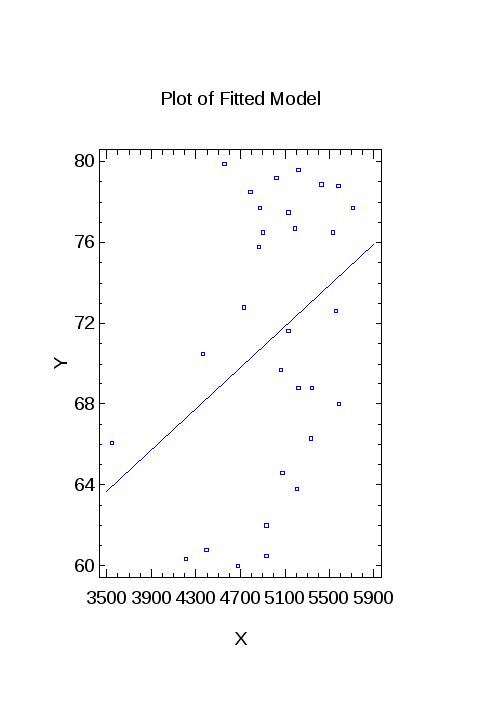
Для определения вида регрессионной зависимости построим корреляционное поле:
Рисунок 1– Диаграмма рассеяния случайных величин X и Y
Характер расположения точек на диаграмме рассеяния позволяет сделать предположение о линейной регрессионной зависимости
![]() .
.
Оценки параметров
![]() найдем методом наименьших квадратов.
Для этого составим функцию S(
найдем методом наименьших квадратов.
Для этого составим функцию S(![]() ),
которая в случае параболической регрессии
примет вид:
),
которая в случае параболической регрессии
примет вид:
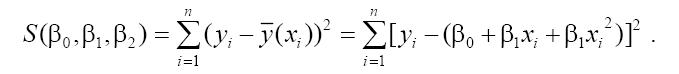

Для вычисления значений сумм, входящих в систему уравнений, составим расчетную таблицу 1:
Multiple Regression - Y
Dependent variable: Y
Independent variables:
X
|
|
|
Standard |
T |
|
|
Parameter |
Estimate |
Error |
Statistic |
P-Value |
|
CONSTANT |
45.793 |
12.8642 |
3.55973 |
0.0013 |
|
X |
0.00510528 |
0.00255888 |
1.99512 |
0.0558 |
Analysis of Variance
|
Source |
Sum of Squares |
Df |
Mean Square |
F-Ratio |
P-Value |
|
Model |
166.879 |
1 |
166.879 |
3.98 |
0.0558 |
|
Residual |
1173.88 |
28 |
41.9241 |
|
|
|
Total (Corr.) |
1340.76 |
29 |
|
|
|
R-squared = 12.4467 percent
R-squared (adjusted for d.f.) = 9.31977 percent
Standard Error of Est. = 6.47488
Mean absolute error = 5.61908
Durbin-Watson statistic = 1.93195 (P=0.4309)
Lag 1 residual autocorrelation = 0.00783976
The StatAdvisor
The output shows the results of fitting a multiple linear regression model to describe the relationship between Y and 1 independent variables. The equation of the fitted model is
Y = 45.793 + 0.00510528*X
Since the P-value in the ANOVA table is greater or equal to 0.05, there is not a statistically significant relationship between the variables at the 95.0% or higher confidence level.
The R-Squared statistic indicates that the model as fitted explains 12.4467% of the variability in Y. The adjusted R-squared statistic, which is more suitable for comparing models with different numbers of independent variables, is 9.31977%. The standard error of the estimate shows the standard deviation of the residuals to be 6.47488. This value can be used to construct prediction limits for new observations by selecting the Reports option from the text menu. The mean absolute error (MAE) of 5.61908 is the average value of the residuals. The Durbin-Watson (DW) statistic tests the residuals to determine if there is any significant correlation based on the order in which they occur in your data file. Since the P-value is greater than 0.05, there is no indication of serial autocorrelation in the residuals at the 95.0% confidence level.
In determining whether the model can be simplified, notice that the highest P-value on the independent variables is 0.0558, belonging to X. Since the P-value is greater or equal to 0.05, that term is not statistically significant at the 95.0% or higher confidence level. Consequently, you should consider removing X from the model.