

denbnovetsky
.pdfПод объединением двух систем  и
и  с возможными состояниями
с возможными состояниями  понимается сложная система
понимается сложная система  , состояния которой
, состояния которой  представляют собой все возможные комбинации состояний
представляют собой все возможные комбинации состояний  систем
систем  и
и  .
.
Очевидно, число возможных состояний системы  равно
равно  . Обозначим
. Обозначим  вероятность того, что система
вероятность того, что система  будет в состоянии
будет в состоянии  :
:
 . (18.3.1)
. (18.3.1)
Вероятности  удобно расположить в виде таблицы (матрицы)
удобно расположить в виде таблицы (матрицы)
Найдем энтропию сложной системы. По определению она равна сумме произведений вероятностей всех возможных ее состояний на их логарифмы с обратным знаком:
(18.3.2)
или, в других обозначениях:
. |
(18.3.2') |
Энтропию сложной системы, как и энтропию простой, тоже можно записать в форме математического ожидания:
, |
(18.3.3) |
где  - логарифм вероятности состояния системы, рассматриваемый как случайная величина (функция состояния).
- логарифм вероятности состояния системы, рассматриваемый как случайная величина (функция состояния).
Предположим, что системы  и
и  независимы, т. е. принимают свои состояния независимо одна от другой, и вычислим в этом предположении энтропию сложной системы. По теореме умножения вероятностей для независимых событий
независимы, т. е. принимают свои состояния независимо одна от другой, и вычислим в этом предположении энтропию сложной системы. По теореме умножения вероятностей для независимых событий
 ,
,
откуда
 .
.
Подставляя в (18.3.3), получим
 ,
,
или
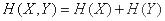 , (18.3.4)
, (18.3.4)
т. е. при объединении независимых систем их энтропии складываются. Доказанное положение называется теоремой сложения энтропий.
Теорема сложения энтропий может быть легко обобщена на произвольное число независимых систем:

 . (18.3.5)
. (18.3.5)
Если объединяемые системы зависимы, простое сложение энтропий уже неприменимо. В этом случае энтропия сложной системы меньше, чем сумма энтропий ее составных частей. Чтобы найти энтропию системы, составленной из зависимых элементов, нужно ввести новое понятие условной энтропии.
33. Умовна ентропія. Ентропія об’єднання двох або більшої кількості статистично зв язаних ансамблів. Диференціальна ентропія.
Энтропия - мера беспорядка системы, состоящей из многих элементов.
(вариант лекции этого года) Энтропия –как мера неопределенности, которая учитывает вероятность появления.
Шеннона(еѐ наз. энтропией дискретного источника) – H(N)= - |
; (1-p) |
Хартли – H(N) = logN; (1-2) |
|
Статически независимых – H(AB) = − ∑∑p(aibj)logp(aibj) |
|
Условная - |
|
Дифференциальная - |
|
Равномерный -
Гауссовский закон - 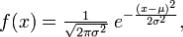
Энтропия 2-х статически зависимых ансамблей U и V = безусловной энтропие оного ансамбля H (U ) или H (V ) плюс условная энтропия другого ансамбля
H (U ,V ) H (U ) HU (V ) H (V ) HV (U ) |
(19) |
k
HV (U ) p(v j )HVj (U )
j 1
k
HVj (U ) p(ui / v j ) log p(ui / v j )
j 1
34.Визначення, переваги та недоліки кодування у ЕС. Теорема Котельникова.
Кодирование информации— процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи,
хранения или автоматической переработки.
Преимущество цифрового представления информации заключается:
-болем высокой помехоустойчивости;
-позволяет обойтись конечным числом уровней квантования;
-позволяет снизить затраты на хранение и обработку сигналов;

-простота восстановления формы кодовых импульсов, которая искажается во время
прохождения через канал связи.
Недостатки:
-передача аналогового сигнала в цифровой требует значительно более широкой полосы частот чем передача аналоговых сигналов полосе частот и ограничению ресурсов.
-цифровая электронная система нуждается в прецезионной синхронизации передачи и приема.
-несовместимы со старыми аналоговыми;
-ухудшаются качества системы которая носит пороговое значение.
Помехоустойчивость кодирования обеспечивается за счѐт введения избыточности в кодовые комбинации. Это значит, что не все n символов кодовой комбинации используются для кодирования информации
Теорема Котельнікова – теорема, згідно котрої сигнал з обмеженим спектром частот можна поністю представити сукупністю відліків з тактовою частотою fS=1/TS,
перевищуючою неменше ніж в 2 рази найвищу частоту спектру сигналу.
Связываетаналоговые и дискретныесигналы и гласит, что, еслианалоговый сигнал x(t);
имеетфинитный (ограниченный по ширине) спектр, то он можетбытьвосстановлен однозначно и без потерь по своимотсчѐтам, взятым с частотой,
большейилиравнойудвоеннойверхнейчастоте.
35. Ефективні коди: Шеннона-Фано, Хафмена. Код Грея. Манчестерський код.
Код Шеннона-Фано
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
X |
|
P |
|
|
|
|
|
|
|
|
|
Коды |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
x1 |
|
1/4 |
|
0 |
|
0 |
|
------- |
|
------- |
|
00 |
|
|
|
|
|
|
|
|
|
|||||
|
x2 |
|
1/4 |
|
|
|
1 |
|
------- |
|
------- |
|
01 |
|
|
|
|
|
|
|
|
|
|||||
|
x3, |
|
1/8 |
|
|
|
0 |
|
0 |
|
------- |
|
100 |
|
|
|
|
|
|
|
|
|
|
||||
|
x4 |
|
1/8 |
|
1 |
|
|
|
1 |
|
------- |
|
101 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x5 |
|
1/16 |
|
|
|
|
|
0 |
|
0 |
|
1100 |
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
x6 |
|
1/16 |
|
|
|
|
|
1 |
|
1101 |
||
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
||||
|
x7 |
|
1/16 |
|
|
|
|
|
1 |
|
0 |
|
1110 |
|
|
|
|
|
|
|
|
|
|
|
|||
|
x8 |
|
1/16 |
|
|
|
|
|
|
|
1 |
|
1111 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Средняя длина полученного кода будет равна
В коде Шеннона-Фано количество цифр в различных кодовых комбинациях разное, т.е. код неравномерный. Сообщения с большей вероятностью имеют более короткую кодовую комбинацию.
Принцип построения: Сначала знаки алфавита записываются в столбец в порядке убывание вероятности. Потом а) список символов делится на две части так, чтобы суммы частот обеих были точно или
примерно равны. В случае, когда точного равенства достичь не удается, разница между суммами должна быть минимальна; б) кодовым комбинациям первой части дописывается 1, кодовым комбинациям второй части дописывается 0;
в) анализируют первую часть: если она содержит только один символ, работа с ней заканчивается, – считается, что код для ее символов построен, и выполняется переход к шагу г) для построения кода второй части. Если символов больше одного, переходят к шагу а) и процедура повторяется с первой частью как с самостоятельным упорядоченным списком; г) анализируют вторую часть: если она содержит только один символ, работа с ней
заканчивается и выполняется обращение к оставшемуся списку (шаг д). Если символов больше одного, переходят к шагу а) и процедура повторяется со второй частью как с самостоятельным списком; д) анализируется оставшийся список: если он пуст – код построен, работа заканчивается.
Если нет, – выполняется шаг а).
Код Хаффмена
Обеспечивает однозначность построения кода со средним числом символов на буквы для данного распределения вероятности символов. Построение: буквы алфавита записываются в порядке уменьшения вероятности, 2 последние буквы с наименьшей вероятностью обьединяются в одну самостоятельную группу с большей вероятностью. сравниваются вероятности с учетом, что 2 последних буквы уже в группе с сумарной вероятностью и процесс повторяется снова. Процесс повторяется снова до тех пор пока не получится единственная группа с вероятностью 1. Потом строится кодовое дерево на базеполученных данных, причем ветви с большей вероятностью присваивается значение 1, а ветви с меньшей 0. ответвление продолжается до момента достижения вероятности каждого сообщения.
Рефлексный код (Грея)
Строение кода Грея Код Грея - непозиционный код с одним набором символов (0 и 1) для каждого разряда.
Таким образом, в отличие от римской системы счисления число в коде Грея не является суммой цифр. Чтобы показать соответствие последовательности чисел коду Грея можно воспользоваться таблицей, но есть и наглядное правило построения этой последовательности.
Младший разряд в последовательности чисел в коде Грея принимает значения 0 и 1, затем следующий старший разряд становится единичным и младший разряд принимает свои значения уже в обратном порядке (1, 0). Этим и объясняется название кода - "отражѐнный". Соответственно, два младших разряда принимают значения 00, 01, 11, 10, а затем, при единичном следующем старшем разряде, те же значения в обратном порядке (10, 11, 01, 00). Ниже дана таблица, показывающая первые восемь чисел в двоичном коде и в коде Грея.
N |
двоичный код |
код Грея |
|
N двоичный код |
код Грея |
0 |
000 |
000 |
4 |
100 |
110 |
1 |
001 |
001 |
5 |
101 |
111 |
2 |
010 |
011 |
6 |
110 |
101 |
3 |
011 |
010 |
7 |
111 |
100 |
Использование кода Грея Благодаря своему основному свойству (отличие соседних чисел только в одном разряде)
код Грея применяется, например, в построенных на кодовых дисках определителях углового положения вала. В оптическом кодовом диске единицы и нули кодируются прозрачными и непрозрачными областями. С одной стороны диск просвечивается ориентированной вдоль его радиуса световой щелью, с другой стороны размещаются фотодиоды. Считываемый с фотодиодов двоичный код и указывает угол поворота диска. Ниже показаны 3-разрядные диски на позиционном коде и коде Грея (в силу ограниченности выразительных средств диски "разрезаны" посредине последнего угла и "вытянуты" в ленту, как это делается и для карт земного шара): позиционный код код Грея Недостаток кодирования позиционным двоичным кодом заключается в том, что при
смене нечѐтного кода чѐтным считанный с фотодиода код может оказаться неверным. Характеристики фотодиодов обычно не идентичны и при смене сразу нескольких разрядов выходные уровни фотодиодов могут измениться не строго одновременно. Например, при переходе от третьего угла к четвѐртому или от седьмого угла к нулевому меняются все разряды и какое-то время на выходе фотодиодов можно получить любое значение от 0 до 7. В коде же Грея при переходах ошибка не будет превышать один угол.
Манчестерский код.
Каждий разряд исходного двоичного кода записывается в виде двух елементов
0 01
1 10
Например исходной кодовой комбинации 0010011 соответствует комбинация
01011001011010
Приемное устройство, которое состоит из двух соединенных элементов Манчестерского кода должно фиксировать переход 0 в 1 или 1 в 0, в случае приема двух нулей или единиц, приемник фиксирует ошибку. Переход полярности происходит строго в центре каждого временного интервала, что очень удобно для синхронизации, но есть отрицательная сторона: Манчестерский код требует удвоения скорости линейного кодирования. Обнаруживает ошибки любой кратности, но не обнаруживает зеркальные ошибки, когда соседние элементы одного такта под влиянием помех меняются на противоположные.
Избыточность кода: Rизб 1 2kk 12 .
Преимущества:
Отсутствие постоянной составляющей при передаче комбинации по каналу связи
Возможность самосинхронизации генератора приемника, так как прием каждого бита информации осуществляется по переднему фронту, который фиксируется в центре бита.

36. Цілі, параметри та принципи перешкодостійкого кодування. Переваги та недоліки
Под помехоустойчивыми кодами понимают коды, позволяющие обнаруживать или обнаруживать и исправлять ошибки, возникающие в результате влияния помех . Помехоустойчивость кодир обеспечивается за счет введения избыточности в кодовые комбинации, тоесть за счет того, что не все символы в кодовой комбинации использ для передачи информации. Помехоустойчтвые коды-это одно из наиболее эффект средств для обеспечения высокой помехоустойчивости и высокой верности. Помехоустойчивое кодиров должно осущ так, что бы сигнал соотв принятой послед символов после воздействия на него помехи оставался ближе к сигналу соотв перед послед символов. Проверка на приемной стороне дает возможность обнаружить и исправить ошибки.
Основной задачей помехоустойчивого кодирования является решение проблемы обеспечения высокой достоверности передаваемых данных за счет применения устройств кодирования/декодирования в составе системы передачи цифровой информации, структурная схема которой представлена на рис. 1.1. Данная схема широко используется в теории помехоустойчивого кодирования, поскольку она охватывает большинство ситуаций, которые встречаются на практике.
Идея может быть рассмотрена на примере двоичного кода, тоесть m=2. Количество разрядов n в кодовой комбинации принято называть длина или значность кода.Символы каждого разряда могут принимать значения 0 или 1 при этом количество единиц кодовой комбинации называется весом кодовой комбинации ω.
Например, 11000111101 n=11, ω=7. Степень отличия любых двух кодовых комбинаций данного кода характеризуется кодовым расстоянием d оно выражается числом позиций или символом, в которых комбинации отличаются одна от другой и определяется как вес суммы по модулю этих кодовых комбинаций.
11000111101
+
10111000101
=
01110110111
d=7
Полученая в результате суммирования новая кодовая комбинация вследствии расстоянию между исходной кодовой комбинации равно 7.

∑
Геометрическая интерпритация. Допустим имеется алфавит из 3 символов: 000, 001, 010, 011,100,101,111.
Ошибку можно обнаружисть если кодовые комбинации отстают на два ребра 000, 011,101,110. Для данного кода для исправления ошибки необходимо чтобы отличалось на 3 ребра. Ошибки вследствии воздействия помех проявляются в том , что в одном или нескольких разрядах нули переходят в единицы. В результате создается ложная комбинация.Если ошибки происходят только в одном разряде, то их название однократные. При наличии ошибок в двух-трех разрядах-двукратные, трѐхкратные. Эксперементирование исследования каналов связи показали что ошибки символов при передачи по каналам связи групируются в пачки. Под пачкой ошибок понимают участок последовательности, начинающийся и заканчивающейся ошибочно принятыми символами. Внутри пачки могут быть правильно принятые сиволы но вся пачка бракуется. Для указания мест кодовой комбинации, где имеется искажение символов используются вектор ошибок(e).Ветор ошибки n-разрядного кода -это n раздная комбинации единицы в которой указываю положение искаженных символов. Вектор ошибки характеризует кратность ошибки.
Величина d называется расстоянием – это расстояние всегда целое число, равное числу разрядов, которые отл. Двоичным числам-эти расстояния соответствуют пространству. В более общем случае пространство будет иметь ни 3 координаты, а n-координат и будет отображаться n-мерным кубом.
Если для 5-ти разрядного кода е=01100, то это значит что в 3 и 4 кодовых комбинациях вес вектора ошибки Ω характеризует кратность ошибки .Сумма по модулю 2 для искаженной кодовой
комбинации и вектора ошибки даст исходную неискаженную комбинацию, таким образом помехоустойчивое кодирование обеспечивается за счет введения избыточности кодовой комбинации. Это значит что из n-символов для передачи информации используется только k-символов.(n>k).
Следовательно из числа возможных кодовых комбинаций |
. |
.В |
||
соответствии с этим все множество |
возможных кодовых комбинаций разбивается |
|||
на 2 группы.В первую группу входит множество |
. Вторая группа включает в |
|||
себя |
- запрещенная кодовая комбинация.если на приемной стороне |
|||
установлено , что принятая комбинация относится к группе разреш. то считается, что сигнал прошѐл через канал без искажений.
Параметры помехоустойчивого кода
1.Длина, значность, число разрядов, разрядность (одно и тоже).
n=k+r
2.Количество информационных, иначе разрешенных символов элементов k, обеспечивающих кодирование передаваемой информации.
3.Кол-во избыточных, проверочных, контрольных корректирующих, запрещенных (одно и тоже)
r=n-k
Обеспечивает помехоустойчивость кода при наличии помех. 4. Основание кода.
nq=n=M
Кол-во используют при кодировании упорядоченных знаков.
5.Для сверточного кода используется 3 числа: n,k,K.
6.Общее число кодовых комбинаций или число всех возможных комбинаций или объем алфавита кода N0=qn=mn
Для двоичных кодов q=m=2.
7.Вес кода и вес кодовой комбинации для 2-го числа равен 2.
8.Мощность Nразр – это число разрешенных кодовых комбинаций.
9.Избыточность корректирующего кода используется для передачи сообщения
wkk=r/n=(n-1)/n=1-k/n показывает какую часть от числа символов составляет k. Величина k/n характеризует относительную скорость передачи информации.
10.Корректирующая способность кода связана с минимальным необходимой избыточностью. Определены верхние и нижние границы для кодов, которые устанавливают связь между максимально возможным кодовым расстоянием корректирующего кода и его избыточности.
Нижняя граница Варшамова r/n=1-(k/n)>=H(dmin-2), где H(x)=-x log2(1-x) r>=nH(dmin-2)/(n-1)
k/n<=(1- H(dmin-2)/(n-1))/
Позволяет оценить необходимое количество проверочных символов и относительной скорости передачи.
11.Относительная скорость передачи информации характеризует степень использования избыточности.
Rотн=k/n
12.Кратность ошибки.
13.Кодовое расстояние.
14.Помехоустойчивость характеризует его способность обеспечивать правильную передачу сообщения в условиях возбуждения помех, поэтому для количественной оценки
помехоустойчивого кода млжна использовать вероятность правильного приема: Рпр=1-Рош. Более удобным критерием оценки помехоустойчивого кода является S=log(1/ Рош).
15.Эффективность действия помехоустойчивого кода оценивается по след. формуле:
KKK=(10lg(E1/N0*)/E1/N0) дБ
E1 – энергия затраченная на передачу информации в 1 бит.
N0 – мощность шума на 1 Гц полосы частот канала связи.
E1/N0* - отношение этих же величин, но при использовании корректирующего кода. KKK – показывает на сколько применение корректирующего кода позволяет улучшить отнощение сигнал/шум в каналах, сохранение числа ошибок на прежнем уровне. Значение находится в пределах 3-7 дБ и возрастает при уменьшении числа ошибок.

37. Класифікація перешкодостійких кодів. Коди з подвоєнням кількості елементів.
Інверсний код.
Под помехоустойчивыми кодами понимают коды, позволяющие обнаруживать или обнаруживать и исправлять ошибки, возникающие в результате влияния помех .
Помехоустойчивость кодир обеспечивается за счет введения избыточности в кодовые комбинации, тоесть за счет того, что не все символы в кодовой комбинации использ для передачи информации. Помехоустойчтвые коды-это одно из наиболее эффект средств для обеспечения высокой помехоустойчивости и высокой верности. Помехоустойчивое кодиров должно осущ так, что бы сигнал соотв принятой послед символов после воздействия на него помехи оставался ближе к сигналу соотв перед послед символов.
Проверка на приемной стороне дает возможность обнаружить и исправить ошибки.
Інверсний код.
Кодовые слова инверсного корректирующего кода образуются повторением исходного кодового слова. Если число единиц в исходном слове четное, оно повторяется в неизменном виде; если число единиц нечетное, то при повторении все символы исходного кодового слова инвертируются (нули заменяются единицами, а единицы - нулями).
Например 01010 0101001010 01110 0111010001
Для обнаружения ошибок в кодовом слове, состоящем из n k r символов производится две операции.
Суммируются единицы, содержащиеся в первых k символах кодового слова.

2. Если число единиц четное, r последующих символов сравниваются попарно с первыми k символами; если число единиц в первых символах нечетное, последующие символы перед сравниванием инвертируются.
Несовпадение хотя бы одной из пар сравниваемых кодовых символов указывает на наличие ошибки в кодовом слове. Ошибка в кодовом слове не обнаруживается, если одновременно искажается четное число символов в исходном слове и соответствующие им кодовые символы в последовательности повторяемых r символов.Инверсный код обладает максимальной помехоустойчивостью.
Избыточность кода: Rизб 1 2kk 12 .
Корреляционный код (Код с удвоением).
Элементыданногокодазаменяютсядвумя символами, единица ‘1’ преобразуется в 10, а
ноль ‘0’ в 01.
Вместокомбинации 1010011 передается 10011001011010. Ошибкаобнаруживается в том случае, если в парныхэлементахбудутодинаковыесимволы 00 или 11 (вместо 01 и 10).
Например, при k=5, n=10 и вероятностиошибки , . Но при этомизбыточностьбудетсоставлять 50%.
38. Код Хемінга, його побудова: класична, матрична. Реалізація, застосування, різновиди.
Известно несколько разновидностей кода Хэмминга, характеризуемых различной корректирующей способностью. К этим кодам обычно относят коды с исправлением однократных ошибок и коды с исправлением однократных и обнаружением двукратных ошибок.
Код Хэмминга, обеспечивающий исправление всех однократных
ошибок, должен иметь минимальное кодовое расстояние dmin = 3. Длина кода n выбирается из условия
где k — количество информационных сигналов.
Код строится таким образом, чтобы в результате p = n — k проверок получить р-разрядное двоичное число, указывающее номер искаженной позиции кодовой комбинации. Для этого проверочные символы должны находиться на номерах позиций, которые выражаются степенью двойки (20, 21, 22,..., 2р-1) так как каждый из них входит только в одно из проверочных уравнений. Таким образом, если нумеровать позиции слева направо, то контрольные символы должны находиться на первой, второй, четвертой и т. д. позициях.
Результат первой проверки дает цифру младшего разряда синдрома в двоичной записи. Если результат этой проверки даст 1, то один из символов проверенной группы искажен. Таким образом, первой проверкой должны быть охвачены символы с номерами,