

Кодирование информации
.pdfПример 2.12. Показать процесс исправления одиночной ошибки в принятой кодовой комбинации.
Решение:
1.Предположим, передавалась комбинация № 14 и в ней исказился третий разряд. Таким образом, принятая комбинация имеет вид 1000110.
2.Делим принятую комбинацию на образующий многочлен
1000110 |1 0 1 11011
11111011 10001011 11
3. Сравниваем вес полученного остатка W с возможным для данного кода числом исправляемых ошибок S. Вес остатка W=2. Число исправляемых ошибок S=1, т. к. W>S.
4. Производим циклический сдвиг принятой комбинации F(X) на один разряд влево с последующим делением полученной в результате циклического сдвига комбинации на К(X):
|
0001101 |1011 |
|
|||
|
1011 |
|
|
|
|
|
110 |
W>S, т. е. W=2, W>S. |
|||
5. Повторяем процедуру п. 3 до тех |
пор, пока не будет W ≤S |
||||
0011010 |1011 |
0110100 |1011 |
|
1101000 |1011 |
||
1011 |
10111 |
|
|
1011 |
|
1100 |
1100 |
|
|
1100 |
|
1011 |
1011 |
|
|
1011 |
|
111 W>S; |
1110 |
|
|
1110 |
|
|
1011 |
|
|
1011 |
|
|
101 W>S; |
1010 |
|||
|
|
|
|
|
1011 |
|
|
|
|
|
1 W = S. |
6. Складываем по модулю 2 последнее делимое с последним остатком |
|||||
|
1101000 |
|
|
||
|
|
|
1 |
|
|
1101001
7. Производим циклический сдвиг комбинации, полученной в результате суммирования последнего делимого с последним остатком, вправо на 4 разряда (так как перед этим мы четырежды сдвигали принятую комбинацию влево) 1110100, 0111010, 0011101, 1001110, как видим, последняя комбинация соответствует переданной, т. е. уже не содержит ошибки.
38

2.7. Упражнения и задачи
Задача 2.1
Построить матрицу для группового кода, способного исправлять одиночную ошибку при передаче 16 символов первичного алфавита.
Задача 2.2
Используя метод образующих матриц, построить циклически код, исправляющий одинарные ошибки при передаче комбинации четырехзначного двоичного кода на все сочетания (кроме нулевой комбинации).
Задача 2.3
При помощи образующей матрицы, полученной в результате умножения единичной матрицы на образующий многочлен Х3+Х+1, построить циклический код, исправляющий одиночную ошибку в любом из четырех информационных разрядов.
Задача 2.4
Исправить любую одиночную ошибку при передаче комбинации 0101, т.е. nи=4.
Задача 2.5
Составить макет кодовой комбинации для nи=4 (0111), вычислить значения контрольных символов.
Задача 2.6
Составить макет кодовой комбинации для nи=4 (1101), вычислить корректирующие коэффициенты.
Задача 2.7
Проверить, допущена ли ошибка при приеме кодовой комбинации (код Хемминга), nи=4, nк=3: 1011011. Изложить методику проверки.
Задача 2.8
Составить проверочную часть матрицы группового кода для nи=5, nк=4, dmin=3.
Задача 2.9
Проверить, допущена ли ошибка при приеме кодовой комбинации
(групповой код), при nи=4, nк=3: 1100111, 1000111.
39

Задача 2.10
Групповой код построен по матрице:
1000 011 C = 0100 111 0010 101 0001 110
Построить контрольную матрицу для исправления ошибки.
Задача 2.11
Дана образующая матрица для группового кода. Составить кодовые комбинации с учетом информационных составляющих nи=1101, nи=1111, nи=1001.
1000 111 C = 0100 110 0010 101 0001 011
Задача 2.12
При построении циклического кода использовался образующий многочлен Х3+Х+1. Проверить, допущены ли ошибки в кодовых комбинациях циклического кода:
0011101
0111010
1111111
1100010
Задача 2.13
Заданы производящие матрицы для группового кода:
|
100000 0011 |
|
10000 0011 |
|
|
|
|
||
|
010000 0101 |
|
|
|
|
|
01000 0110 |
|
|
|
001000 0110 |
|
|
|
C1 = |
C2 = |
00100 1001 |
|
|
|
000100 1001 |
|
00010 1100 |
|
|
000010 1010 |
|
|
|
|
|
00001 0101 |
|
|
|
000001 1100 |
|
|
|
|
|
|
|
Построить контрольные матрицы и записать алгоритм системы проверок для кодов, построенных по этим матрицам.
Используя матрицу С1, сформировать кодовые комбинации с учетом
информационных составляющих: |
|
|
111000, |
101000, |
111001, |
100111, |
100110, |
100110. |
40

Используя матрицу С2, сформировать кодовые комбинации с учетом
информационных составляющих: |
|
|
|
11100, |
0100, |
110011, |
|
10101, |
10001, |
10111. |
|
Проверить, допущены ли ошибки при получении кодовых комбинаций: |
|||
11 0000 0110, |
11 0000 |
0111, |
|
11 1000 0000, |
11 1000 |
0100, |
|
1 0001 0110, |
|
1 000 111, |
|
0 0011 1001, |
|
1 0011 |
1001. |
41
РАЗДЕЛ 3. АППАРАТУРНАЯ РЕАЛИЗАЦИЯ
3.1. Контроль по четности
На передаваемые по линии связи или хранимые в памяти данные воздействуют различные помехи, которые могут исказить эти данные. Простейшим способом удостовериться, что полученные с линии или извлеченные из памяти данные искажены ошибкой и использовать их нельзя, служит введение контроля по четности (контроль по нечетности, parity check – контроль по паритету). В его основе лежит операция сложения по модулю 2 всех двоичных разрядов контролируемого слова. Если число единиц в слове четное, то сумма по модулю 2 его разрядов будет 0, если нечетное – то 1. Признаком четности называют инверсию этой суммы.
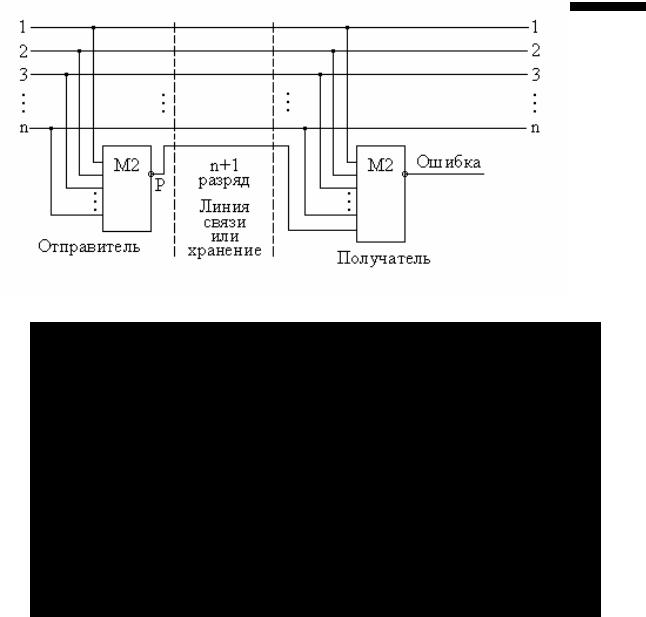
Общая схема организации контроля показана на рис. 3.1.
Рис. 3.1. Организация контроля по нечетности
На n-входовом элементе М2 формируется признак четности Р числа, который в качестве дополнительного, (n+1)-го контрольного разряда (parity bit) отправляется вместе с передаваемым словом в линию связи или запоминающее устройство (ЗУ). Передаваемое (n+1)-разрядное слово имеет всегда нечетное число единиц. Если в исходном слове оно было нечетным, то функция М2 от такого слова равна 0, и нулевое значение контрольного разряда не меняет числа единиц при передаче слова. Если же число единиц в исходном слове было четным, то контрольный разряд Р для такого числа будет равен 1, и результирующее число единиц в передаваемом (n+1)-разрядном слове станет нечетным. Вид контроля, когда по линии передается нечетное число единиц, по строгой терминологии называют контролем по нечетности.
На приемном конце линии или после чтения из памяти от полученного (n+l)-разрядного слова снова берется свертка по четности. Если значение этой свертки равно 1, то или в передаваемом слове, или в контрольном разряде при передаче или хранении произошла ошибка. Столь простой контроль не
42

позволяет исправить ошибку, но он, по крайней мере, дает возможность при обнаружении ошибки исключить неверные данные, затребовать повторную передачу и т. д.
Контроль по четности основан на том, что одиночная ошибка (безразлично
–пропадание единицы или появление лишней) инвертирует признак четности. Однако две сшибки проинвертируют его дважды, т. е. оставят без изменения, поэтому двойную ошибку контроль по четности не обнаруживает. Рассуждая аналогично, легко прийти к выводу, что контроль по четности обнаруживает все нечетные ошибки и не реагирует на любые четные. Пропуск четных ошибок
–это не какой-либо дефект системы контроля. Это следствие предельно малой избыточности при контроле по четности, равной всего одному разряду. Для более глубокого контроля требуется соответственно и большая избыточность. Если ошибки друг от друга не зависят, то из необнаруживаемых чаще всего будет встречаться двойная ошибка, и при вероятности одиночной ошибки,
равной q, вероятность двойной будет q2. Поскольку в нормальных цифровых устройствах q<<l, необнаруженные двойные ошибки встречаются значительно реже, чем обнаруженные одиночные. Поэтому даже при таком простом контроле качество работы устройства существенно возрастет. Еще раз напомним: это верно лишь для взаимно независимых ошибок.
Контроль по четности – самый дешевый по аппаратурным затратам вид контроля, и применяется он очень широко. Практически любой канал передачи цифровых данных или запоминающее устройство, если они не имеют какоголибо более сильного метода контроля, защищены контролем по четности.
3.2. Контроль по Хэммингу
Развитие принципа контроля по четности приводит к корректирующему коду Хэмминга, который позволяет не только обнаруживать, но и исправлять одиночную ошибку. Возможность исправления ошибки основывается на повторенной k раз системе контроля по четности, но не всего слова сразу, а k определенных групп его разрядов. Слово разбивается на группы так, чтобы номер каждого разряда однозначно определялся по его принадлежности или непринадлежности к этим группам.
Рис. 3.2, а иллюстрирует принцип построения 15-разрядного слова, передаваемого по линии связи, – кодового слова. Оно состоит из одиннадцати разрядов информационного слова, первоначально предназначавшегося для передачи по линии (или в память), разряды которого обозначены малыми латинскими буквами, и четырех контрольных разрядов. Контрольные разряды обозначены греческими буквами и показаны размещенными в кодовом слове не компактным массивом, а вперемежку с информационными. На рис. 3.2, а контрольные разряды зачернены.
Группы контроля по четности компонуются из разрядов кодового слова по следующим законам:
1)каждый разряд кодового слова входит в состав стольких групп, сколько единиц содержится в двоичном коде его номера. Так, разряд 4 входит в
43

состав всего одной, 3-й, контрольной группы; разряд 7 входит в состав трех групп: 1, 2 и 3-й;
2)в каждую i-ю контрольную группу входят те разряды кодового слова, в двоичном номере которых в i-й позиции стоит единица. Например, 3-я контрольная группа включает разряды 4, 5, 6, 7; 12, 13, 14 ... Самый младший разряд каждой группы – контрольный. Очевидно, что это разряды, в двоичных номерах которых содержится только одна единица: 1, 2, 4, 8-й... Такое расположение контрольных разрядов облегчает понимание принципа построения схем формирования этих
разрядов.
На рис. 3.2,б показан набор функциональных узлов, формирующих кодовое слово на передающей стороне. Семиразрядные контрольные группы информационного слова, скомпонованные в соответствии с рис. 3.2,а, поступают на семивходовые свертки по четности М 2.1–М 2.4. Результаты свертки каждой группы записываются в ее контрольный разряд.
Функциональные узлы приемной стороны представлены на рис. 3.2,в. Разряды принятого кодового слова также поступают на четыре свертки по четности, но здесь на каждой свертке обрабатывается вся группа вместе с ее контрольным разрядом. Выходы сверток образуют 4-разрядный синдром ошибки, или корректирующий код К. Если при передаче кодового слова в одном из его разрядов произошла ошибка (на рис. 3.2,а в качестве примера крестиком отмечен поврежденный пятый разряд), то будет зафиксировано нарушение четности именно в тех контрольных группах, в состав которых входит неверный разряд. В результате код синдрома ошибки укажет номер неисправного разряда принятого кодового слова. Так, код синдрома 0101 есть двоичный номер поврежденного разряда № 5.
Для восстановления слова неверный разряд нужно проинвертировать. Синдромные разряды поступают на дешифратор, активный выход которого возбуждает управляемый инвертор (двухвходовой элемент М2) в том разряде, в котором произошла ошибка. На рис. 3.2,в показаны 11 инверторов, обеспечивающих исправление разрядов только информационного слова. Предполагается, что оно дальше передаваться не будет, поэтому контрольные разряды больше не нужны, и в них ошибки корректировать не требуется. Разумеется, можно включить в состав схемы все 15 управляемых инверторов и исправлять не только информационные, но и контрольные разряды. Если ошибка не обнаружена, то все синдромные разряды будут нулями, о чем сигнализирует возбужденный нулевой выход S дешифратора. Инверторы при этом пропускают принятое слово без изменения. Следует отметить, что цель рис. 3.2 – возможно проще проиллюстрировать закон, по которому определенные разряды информационного или кодового слова должны взаимодействовать с определенными элементами схемы при кодировании и декодировании. Физическое расположение разрядов в слове при его передаче или хранении может и отличаться от показанного на рис. 3.2, если это технически оправдано. Например, информационные разряды могут образовывать один компактный массив, контрольные – другой.
44
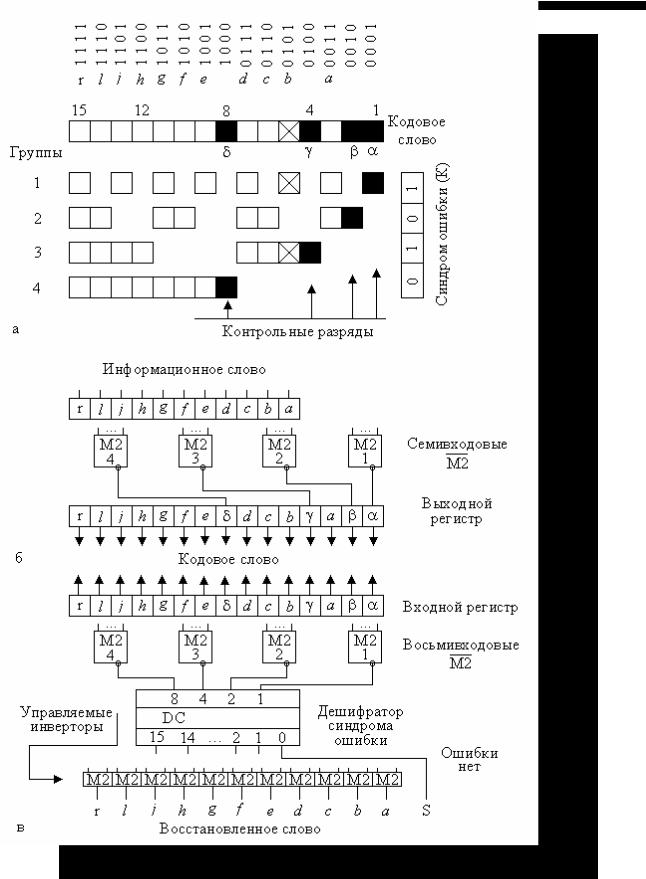
Рис. 3.2. Контроль по Хэммингу:
а– структура кодового слова и контрольных групп;
б– узлы кодирования передатчика;
в– узлы контроля и коррекции приемника
45

РАЗДЕЛ 4. ЦИФРОВЫЕ КОДЫ, ИСПОЛЬЗУЕМЫЕ В АЦП И ЦАП
При построении АЦП и ЦАП используют те же коды, что и в ЭВМ, с которыми они совместно работают в различных системах переработки информации. Это, как правило, разновидности натурального двоичного кода. В измерительных приборах с АЦП чаще применяют варианты двоичнодесятичных кодов. Наконец, в некоторых случаях преимущество имеет код Грея.
4.1. Натуральный двоичный код
При |
кодировании |
натуральным |
двоичным |
кодом |
каждому |
положительному числу ставится в соответствие код |
|
|
|||
|
|
{αij }= α1 j α2 j ...αmj , |
|
|
(4.1) |
где αij равны 0 или 1 и находятся из выражения
c j = ∑m |
α ij 2 − i . |
(4.2) |
i =1 |
|
|
Такой код называется прямым. Его крайний правый разряд является младшим, крайний левый – старшим. Двоичные числа, используемые в АЦП, как правило, нормализованы, т. е. их абсолютное значение не превышает единицы. Они представляют собой отношение входного сигнала к полному диапазону преобразуемого сигнала, который равен 2m. Как легко видеть, прямой код пригоден лишь для работы с однополярными сигналами. При работе с биполярными аналоговыми и цифровыми сигналами важное значение имеет представление отрицательных чисел.
Прямой код со знаком предусматривает введение дополнительного знакового разряда, который является старшим разрядом и для отрицательных чисел принимает значение 1, а для положительных 0. В остальном код остается без изменений. В результате такое представление часто называют «знак+амплитуда».
В вычислительной технике для представления отрицательных чисел используют смещенный, дополнительный и обратный двоичные коды. Смещенный двоичный код образуется прибавлением к числу постоянной величины 2m, в результате чего
c j = −2 −1 + ∑m |
αij 2 − i . |
(4.3) |
i =1 |
|
|
46

При этом максимальный положительный сигнал 1 – 2m представляется кодом 111 ... 1, максимальный отрицательный сигнал 2-m – кодом 000 ... 1, а нулю соответствует код 100 ... 0.
Достоинством смещенного двоичного кода является его достаточно легкая реализация на основе имеющихся однополярных АЦП и ЦАП, однако он менее удобен при выполнении арифметических операций в ЭВМ. Например, сложение двух значений смещенного кода, соответствующих одинаковым по абсолютному значению и противоположным по знаку величинам, приведет к образованию на выходе максимального (по абсолютному значению) сигнала вместо нулевого.
Дополнительный код образуется вычитанием в двоичной форме преобразуемого числа cj из постоянной величины 2m+1. Другими словами, находится дополнение до двух к числу сj, в результате образование отдельных разрядов в кодовом представлении описывается выражением
c j = α1 j (− 2 −1 )+ ∑m |
α ij 2 − i , |
(4.4) |
i =1 |
|
|
1 при c |
j |
<0 |
|
|
|
где α1 j = |
|
≥ 0. |
0 при с |
j |
|
|
|
Диапазон представления чисел в дополнительном коде соответствует от –2-m до 1–2-m. Нуль имеет одно представление 000...0. Этот код наиболее удобен для работы с ЭВМ.
Обратный код образуется вычитанием в двоичной форме преобразуемого числа сj из постоянной величины 2m+1–1, т. е. находится дополнением до единицы Cj. Образование отдельных разрядов в кодовом представлении происходит на основе выражения
|
|
c j = α1 j [− (2 −1 − 2 −m )]+ ∑m |
αij 2 −i , |
(4.5) |
|
|
i=2 |
|
|
1 при c |
j |
<0 |
|
|
|
|
|
|
|
где α1 j = |
|
≥ 0. |
|
|
0 при с |
j |
|
|
|
|
|
|
|
В обратном коде нуль имеет двойное представление: положительный 0+ = 0 000... 0 и отрицательный 0– = 1 111 ... 1. Диапазон чисел, представляемых в обратном коде, такой же, как и для прямого кода со знаком. Для положительных чисел представления в дополнительном и обратном кодах совпадают с представлением в прямом. Отметим, что прямой код со знаком предпочтительнее для операций умножения и деления, а дополнительный и обратный коды удобнее использовать для операций сложения и вычитания.
4.2. Двоично-десятичные коды
Двоично-десятичные коды широко применяют в АЦП, предназначенных для различных цифровых измерительных приборов. Каждая значащая десятичная цифра в таком коде представляется четырьмя двоичными знаками и
47