

книги / Статистические и интеллектуальные методы прогнозирования
..pdf1 |
0.0 |
0.00 |
|
|
0.2 |
0.04 |
|
1 |
|
||
|
0.4 |
0.16 |
|
1 |
|
||
1 |
0.6 |
0.36 |
|
1 |
0.8 |
0.64 |
|
|
1.0 |
1.00 |
|
1 |
|
||
1 |
1.2 |
1.44 |
|
|
1.4 |
|
|
1 |
1.96 |
||
|
1.6 |
2.56 |
|
1 |
|
||
|
1.8 |
3.24 |
|
1 |
|
||
X 1 |
2.0 |
4.00 |
|
1 |
2.2 |
4.84 |
|
|
2.4 |
5.76 |
|
1 |
|
||
1 |
2.6 |
6.76 |
|
|
2.8 |
|
|
1 |
7.84 |
||
|
3.0 |
9.00 |
|
1 |
|
||
|
3.2 |
|
|
1 |
10.24 |
||
1 |
3.4 |
11.56 |
|
1 |
3.6 |
12.96 |
|
|
3.8 |
|
|
1 |
14.44 |
||
|
4.0 |
|
|
1 |
16.00 |
||
a0 A a1a2
Коэффициентырегрессивноймоделипо(3.7)рассчитаныкак
a0 2.060
Aa1 1.1379 .a2 0.1695
Результаты моделирования регрессионных моделей представлены на рис. 3.1.
31
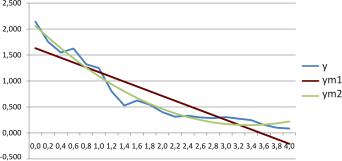
Рис. 3.1. Графики исходных данных и регрессионных моделей ym1 1.6307 0.4600x и ym2 2.060 1.1379x 0.1695x2
3.2.ПРИМЕНЕНИЕ РЕГРЕССИОННОГО АНАЛИЗА
ВЗАДАЧАХ ПРОГНОЗИРОВАНИЯ
Задача прогнозирования может быть определена как прогнозирование некоторого показателя в зависимости от изменения независимых факторов. Например, прогнозирование потребления электроэнергии на промышленных предприятиях. Тогда Y – это объем потребленной энергии за некоторый период, X – факторы, влияющие на количество потребленной энергии (объем и норматив потребления энергии отдельных видов продукции промышленного предприятия, количество рабочих дней, загруженность промышленного оборудования, время года, количество рабочих и выходных дней и др.). В этом случае коэффициенты регрессии представляют собой весовые коэффициенты, показывающие степень значимости того или иного фактора. Следует отметить, что при оценке адекватности таких моделей обязательно должны оцениваться значимость коэффициента множественной корреляции и значимость отдельных коэффициентов регрессионной модели.
Если рассматривать задачу прогнозирования как оценивание модели временного ряда, то компоненты регрессионной модели (3.3) могут быть представлены как
32
|
x(2) |
|
|
|
|
|
|
Y |
x(3) |
|
, |
|
|
||
|
|
|
|
|
|
|
|
|
x(m) |
|
|
1 |
x(1) |
x(2) |
|
x(m p) |
|
|
|
|
|
|
|
|
|
X 1 |
x(2) |
x(3) |
|
x(m p 1) |
|
, |
|
|
|
|
|
|
|
|
x(m p 2) |
x2(m p 3) |
|
xn (m 2) |
|
|
1 |
|
|
где р – степень погружения.
Задача в такой постановке определяется как авторегрессионная модель. Для расчета и исследования авторегрессионных моделей существуют собственные методы, которые будут рассмотрены ниже.
С точки зрения целесообразности и эффективности моделей прогнозирования есть смысл рассчитывать оба вида моделей и использовать их для прогнозирования.
3.3.НЕЛИНЕЙНАЯ РЕГРЕССИОННАЯ МОДЕЛЬ
Нелинейные регрессии делятся на два класса:
1) регрессии, нелинейные относительно включенных в анализ переменных. Например:
y a b1x b2x2 b3x3 ; y a bx ;
ya b1ex b2 2x ;
2)регрессии, нелинейные по оцениваемым параметрам. Например:
33
y axb ; y abx .
Очевидно, что нелинейные зависимости первого рода легко сводятся к линейному виду путем банальных замен переменных.
Для нелинейностей второго рода можно предложить процедуру линеаризации в узловых точках.
После соответствующих преобразований зависимости, приведенные к линейному виду, легко прогнозируются с помощью линейного регрессионного анализа.
ПРИМЕР 3.2. По данным примера 3.1 построить нелинейную регрессионную модель.
Анализируя исходные данные, можно предложить в качестве нелинейной регрессионной модели гиперболическую
зависимость типа y a bx , которая легко преобразуется к ви-
ду y a |
0 |
a x , |
где a |
a, |
a |
b, |
x |
1 . Но при расчете мо- |
|
|
1 |
1 |
0 |
|
1 |
|
1 |
x |
|
|
|
|
|
|
|
|
|
|
|
дели данного |
вида |
из |
|
рассмотрения убирается пара |
|||||
( x 0.0 |
|
y 2.143), чтобы избежать деления на ноль. |
|||||||
Расчет коэффициентов осуществляется аналогично примеру 3.1. Нелинейная регрессионная модель имеет вид
y 0.2775 0.4019x .
Результаты моделирования нелинейной регрессионной модели представлены на рис. 3.2.
Очевидно, что регрессионные модели имеют погрешность, поэтому необходимо оценить качество или адекватность моделей.
34
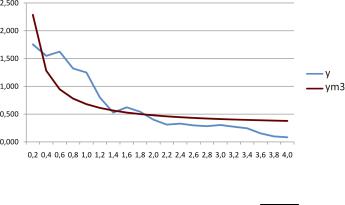
Рис. 3.2. Графики исходных данных и нелинейной регрессионной модели ym3 0.2775 0.4019x
3.4.АДЕКВАТНОСТЬ РЕГРЕССИОННОЙ МОДЕЛИ
Качество построенных регрессионных моделей оценивается с помощью методов оценки адекватности. Проверить адекватность модели – значит установить, насколько хорошо модель описывает реальные процессы, происходящие в системе, насколько качественно она будет прогнозировать развитие данных процессов. Проверка адекватности проводится на основании некоторой экспериментальной информации, полученной до момента прогнозирования, на основе дополнительных опытов в промежуток времени до прогнозирования. Иногда допрогнозный процесс разбивают на несколько выборок, которые могут в ходе проверки адекватности моделей использоваться для различных аспектов адекватности.
Поскольку процесс прогнозирования базируется на статистических данных, то при оценке адекватности используются статистические методы, использующие дисперсионный анализ и гипотезный подход.
35
3.4.1. Основные понятия дисперсионного анализа
Проверка адекватности заключается в доказательстве факта, что точность результатов, полученных по модели, будет не хуже точности расчетов, произведенных на основании экспериментальных данных. Признание адекватности модели сводится к принятию нулевой статистической гипотезы [9, 10].
Нулевая гипотеза H0 – это основное проверяемое предпо-
ложение, которое обычно формулируется как отсутствие различий, отсутствие влияние фактора, отсутствие эффекта, равенство нулю значений выборочных характеристик и т.п. Другое проверяемое предположение (не всегда строго противоположное или обратное первому) называется альтернативной гипотезой.
Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость проверить ее. Поскольку проверку производят статистическими методами, то данная проверка называется статистической.
При проверке статистических гипотез возможны ошибки (ошибочные суждения) двух видов [10, 11]:
1)можно отвергнуть нулевую гипотезу, когда она на самом деле верна (так называемая ошибка первого рода);
2)можно принять нулевую гипотезу, когда она на самом деле не верна (так называемая ошибка второго рода).
Допустимая вероятность ошибки первого рода оценивается с помощью уровней значимости.
Уровень значимости – это вероятность ошибки первого рода при принятии решения (вероятность ошибочного отклонения нулевой гипотезы). Альтернативные гипотезы принимаются, если опровергается нулевая гипотеза. Это бывает тогда, когда различия в статистических характеристиках экспериментальной и контрольной групп являются существенными.
1-й уровень – 5 % ( 0.05 ), где допускается риск ошибки в выводе в пяти случаях из ста теоретически возможных та-
36
ких же экспериментов при строго случайном отборе для каждого эксперимента;
2-й уровень – 1 % ( 0.01), т.е. соответственно допускается риск ошибиться только в одном случае из ста;
3-й уровень – 0.1 % ( 0.001), т.е. допускается риск ошибиться только в одном случае из тысячи.
Статистика критерия – некоторая функция от исходных данных, по значению которой проверяется нулевая гипотеза.
Всякое правило, на основе которого отклоняется или принимается нулевая гипотеза, называется критерием проверки данной гипотезы.
Статистический критерий – это случайная величина, ко-
торая служит для проверки статистических гипотез. Критическая область – совокупность значений критерия,
при котором нулевую гипотезу отвергают.
Область принятия нулевой гипотезы (область допусти-
мых значений) – совокупность значений критерия, при котором нулевую гипотезу принимают. При справедливости нулевой гипотезы вероятность того, что статистика критерия попадает в область принятия нулевой гипотезы, должна быть равна 1.
Процедура проверки нулевой гипотезы в общем случае включает следующие этапы:
задается допустимая вероятность ошибки первого рода
( 0.05 );
осуществляется выбор статистики критерия;
определяется область допустимых значений;
по исходным данным вычисляется значение статистики критерия;
если статистика критерия принадлежит области принятия нулевой гипотезы, то нулевая гипотеза принимается (т.е. делается заключение, что исходные данные не противоречат нулевой гипотезе), в противном случае нулевая гипотеза отвергается и принимается альтернативная гипотеза.
37
Основными составляющими дисперсионного анализа являются суммы квадратов, степени свободы и дисперсии различных источников происхождения (рассеяния) [10].
Сумма квадратов, обусловленная регрессией, определяет-
ся как
|
|
|
|
|
|
Q |
m |
|
y )2 , |
(3.8) |
|
|
|
|
|
|
(y |
mi |
|||
|
|
|
|
|
|
R |
i 1 |
ср |
|
|
|
|
|
|
|
|
|
|
|
|
|
где y |
|
|
1 m |
|
– среднее значение выходного (зависимого) па- |
|||||
ср |
|
|
y |
i |
||||||
|
||||||||||
|
|
m i 1 |
|
|
|
|
|
|||
раметра, |
m – количество наблюдений или измерений; |
|
||||||||
|
ymi |
– значение параметра, |
рассчитанное по уравнению |
|||||||
регрессии (3.3), здесь индекс m означает выход регрессионной модели.
Сумма квадратов, обусловленная регрессией QR , показы-
вает, что участвующая в ней величина ymi |
определяет n 1 ли- |
|
нейных связей между наблюдениями |
y1, y2, , ym , так как в нее |
|
входит n 1 оценок коэффициентов |
a0, a1, , an , определенных |
|
по тем же наблюдениям. Кроме того, yср |
определяет одну ли- |
|
нейную связь между ними. |
|
|
Число степеней свободы для QR определяется как |
||
R (n 1) 1 n , |
(3.9) |
|
где n 1 – количество коэффициентов регрессии.
Остаточная сумма квадратов определяется как
m |
(y y |
|
)2 |
, |
(3.10) |
Q |
mi |
||||
ост |
i |
|
|
|
|
i 1 |
|
|
|
|
где yi – значения выходной зависимого параметра
Остаточная сумма квадратов Qост отражает влияние всех
тех причин рассеивания результатов y, которые не может объяснить регрессия. По сути, остаточная сумма квадратов оценивает влияние неучтенных в уравнении регрессии параметров.
38
Число степеней свободы для Qост рассчитывается как
ост m n 1. |
(3.11) |
Общая (полная) сумма квадратов определяется по формуле
m
Q (yi yср)2 . (3.12)
i 1
Число степеней свободы для Q
m 1. |
(3.13) |
Для вышеприведенных сумм квадратов справедливо следующее:
Q QR Qост. |
(3.14) |
Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений Q переменной y от среднего зна-
чения |
y |
раскладывается на две части: «объясненную» |
QR и |
||||||||||
«необъясненную» Qост : |
|
|
|
|
|
|
|
|
|
||||
|
|
m |
|
m |
(y |
|
y |
m |
(y |
y |
|
)2. |
(3.15) |
|
|
(y y |
ср |
)2 |
mi |
)2 |
mi |
||||||
|
|
i |
i 1 |
|
ср |
i 1 |
i |
|
|
|
|||
|
|
i 1 |
|
|
|
|
|
|
|
|
|
||
Для степеней свободы |
|
|
|
|
|
|
|
|
|
||||
|
|
R ост |
n m n 1 m 1. |
|
(3.16) |
||||||||
Для анализа адекватности используются оценки дисперсий:
дисперсия, обусловленная регрессией
S 2 |
|
QR |
; |
|
(3.17) |
R |
|
|
|
|
|
|
|
R |
|
|
|
остаточная дисперсия |
|
|
|
|
|
S 2 |
|
Qост |
; |
(3.18) |
|
|
|||||
ост |
|
|
|
|
|
|
|
ост |
|
|
|
39
общая (полная) дисперсия |
|
|
|
|
|||
|
|
S 2 |
Q . |
|
|
(3.19) |
|
|
|
|
|
|
|
|
|
Результаты расчетов параметров дисперсионного анализа |
|||||||
удобно и наглядно оформлять в виде таблицы (табл. 3.2). |
|
||||||
|
|
|
|
|
Таблица 3.2 |
||
|
Параметры дисперсионного анализа |
|
|||||
|
|
|
|
|
|
|
|
Источник |
|
Сумма |
|
Число степеней |
|
Оценка дисперсии |
|
рассеяния |
|
квадратов |
|
свободы |
|
||
|
|
|
|
|
|||
Регрессия |
|
QR |
|
R n |
|
SR2 QR |
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Остаток |
|
Qост |
|
ост m n 1 |
|
Sост2 Qост |
|
|
|
|
|
|
|
|
ост |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Общая (полная) |
|
Q |
|
m 1 |
|
S 2 Q |
|
|
|
|
|
|
|
|
|
Для оценки адекватности моделей используются статистические критерии Фишера и Стьюдента [10, 11]. Суть критериев заключается в расчете значения критерия и сопоставления его с табличным значением данного критерия.
При анализе адекватности уравнения регрессии (модели) исследуемому процессу возможны следующие варианты:
1.Регрессионная модель в целом адекватна и все коэффициенты регрессии значимы. Такая модель может быть использована для задач прогнозирования.
2.Регрессионная модель адекватна, но часть коэффициентов не значима. Модель пригодна для принятия некоторых решений, но не для прогнозирования.
3.Модель адекватна, но все коэффициенты регрессии не значимы. Такая модель не может быть использована для задач прогнозирования.
40