

МУ Эконометрика 1477
.pdf11
4)отобразить на графике фактические данные, результаты расчетов и прогнозирования;
5)для данного ряда выбрать наилучший вид тренда.
Порядок выполнения.
1.Оценка параметров модели
1.1.Оценим параметры с помощью надстройки Excel Анализ данных. Для этого выполним следующие действия:
введем исходные данные (рис. 2):
|
A |
B |
C |
1 |
t |
Yt |
2 |
1 |
16,3 |
3 |
2 |
20,2 |
4 |
3 |
17,1 |
5 |
4 |
7,7 |
6 |
5 |
15,3 |
7 |
6 |
16,3 |
8 |
7 |
19,9 |
9 |
8 |
14,4 |
10 |
9 |
18,7 |
11 |
10 |
20,7 |
Рис. 2. Исходные данные
выберем команду Сервис + Анализ данных;
в появившемся окне выберем инструмент Регрессия, а затем щелкнем по кнопке ОК (рис. 3).
Рис. 3. Диалоговое окно Анализ данных
в диалоговом окне Регрессия в поле Входной интервал Y введем диапазон ячеек зависимой переменной (Котировки). В поле Входной интервал Х введем диапазон ячеек, который содержит значения независимой переменной (t). Если выделить и заголовки столбцов, то необходимо установить флажок в поле Метки.
Для параметров вывода выберем поле Новый рабочий лист. Для анализа остатков выберем поля Остатки и График подбора. Диалоговое окно будет выглядеть следующим образом (рис. 4).

12
Рис. 4. Диалоговое окно Регрессия
Результат регрессионного анализа будет выведен на новый лист рабочей книги Excel. Анализ содержит таблицу регрессионной статистики и дисперсионного анализа (табл. 2, 3), таблицу регрессионного анализа (табл. 4, 5), а также график подбора (рис. 5).
Таблица 2
Регрессионная статистика |
|
Множественный R |
0,255670797 |
R-квадрат |
0,065367556 |
Нормированный R-квадрат |
-0,051461499 |
Стандартная ошибка |
3,915155092 |
Наблюдения |
10 |
Дисперсионный анализ |
|
|
|
|
Таблица 3 |
|
|
|
|
|
|
|
df |
SS |
MS |
F |
Значимость F |
Регрессия |
1 |
8,576484848 |
8,576484848 |
0,559514549 |
0,475867353 |
Остаток |
8 |
122,6275152 |
15,32843939 |
|
|
Итого |
9 |
131,204 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 4 |
||
|
|
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
|||||||||
Y-пересечение |
14,88666667 |
|
2,674560098 |
|
|
5,566024364 |
0,00053091 |
||||||||
Переменная X 1 |
0,322424242 |
|
0,431044389 |
|
|
0,748007051 |
0,475867353 |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
Нижние 95% |
Верхние 95% |
|
Нижние 95,0% |
|
Верхние 95,0% |
|
|
|||||
|
|
|
8,719120026 |
21,05421331 |
|
8,719120026 |
|
21,05421331 |
|
|
|||||
|
|
|
-0,6715659 |
1,316414385 |
|
-0,6715659 |
|
1,316414385 |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 5 |
||
|
Наблюдение |
|
Предсказанное Y |
|
Остатки |
|
|
|
|
||||||
|
1 |
|
|
15,20909091 |
|
|
1,090909091 |
|
|
|
|||||
|
2 |
|
|
15,53151515 |
|
|
4,668484848 |
|
|
|
|||||
|
3 |
|
|
15,85393939 |
|
|
1,246060606 |
|
|
|
|||||
|
4 |
|
|
16,17636364 |
|
|
-8,476363636 |
|
|
|
|||||
|
5 |
|
|
16,49878788 |
|
|
-1,198787879 |
|
|
|
|||||
|
6 |
|
|
16,82121212 |
|
|
-0,521212121 |
|
|
|
|||||
|
7 |
|
|
17,14363636 |
|
|
2,756363636 |
|
|
|
|||||
|
8 |
|
|
17,46606061 |
|
|
-3,066060606 |
|
|
|
|||||
|
9 |
|
|
17,78848485 |
|
|
0,911515152 |
|
|
|
|||||
|
10 |
|
|
18,11090909 |
|
|
2,589090909 |
|
|
|
|||||

|
|
|
13 |
|
|
|
|
Переменная X1 График подбора |
|
|
|||
25 |
|
|
|
|
|
|
20 |
|
|
|
|
|
|
15 |
|
|
|
|
|
|
Y |
|
|
|
|
|
|
10 |
|
|
|
|
|
|
5 |
|
|
|
|
|
|
0 |
|
|
|
|
|
|
0 |
2 |
4 |
6 |
8 |
10 |
12 |
|
|
|
Переменная X1 |
|
|
|
|
|
Y |
Предсказанное Y |
|
|
|
|
Рис. 5. График подбора |
|
|
|||
В результате расчетов получено линейное уравнение зависимости yt (урожайность) от t (время) в виде:
Y(t) = 14,887 + 0,322t
1.2. Оценка параметров модели "вручную". Расчеты коэффициентов модели будем проводить по формулам кривых роста оцененных МНК:
|
|
n |
t t yt |
|
|
|
||
|
|
|
|
y |
||||
a |
t 1 |
|
|
(3) |
||||
|
|
n |
|
|||||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
t t 2 |
||||
|
|
|
|
t 1 |
|
|
|
|
a0 = |
|
|
a1 t , |
(4) |
||||
|
y |
|||||||
где y , t - средние значения уровней ряда и моментов наблюдения соот-
ветственно.
Промежуточные расчеты приведены в табл. 6. Оценка параметров регрессии:
а1 = 26,6 0,3224; 82,5
а0 = 16,66 – 0,3224 5,5 14,8867.
В результате ручного расчета получено линейное уравнение зависимости yt (урожайности) от t (время) в виде:
Y(t) = 14,89 + 0,32t.
1.3.Оценка параметров модели средствами мастера диаграмм представлена на рис. 6.
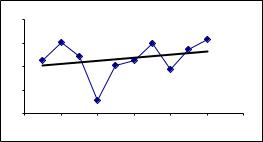
14
|
|
|
|
|
|
Таблица 6 |
|
|
|
|
|
|
|
|
t |
yt |
(t-tcp) |
(t-tcp)^2 |
(y-ycp) |
(t-tcp)*(y-ycp) |
|
1 |
16,3 |
-4,5 |
20,25 |
-0,36 |
1,62 |
|
2 |
20,2 |
-3,5 |
12,25 |
3,54 |
-12,39 |
|
3 |
17,1 |
-2,5 |
6,25 |
0,44 |
-1,1 |
|
4 |
7,7 |
-1,5 |
2,25 |
-8,96 |
13,44 |
|
5 |
15,3 |
-0,5 |
0,25 |
-1,36 |
0,68 |
|
6 |
16,3 |
0,5 |
0,25 |
-0,36 |
-0,18 |
|
7 |
19,9 |
1,5 |
2,25 |
3,24 |
4,86 |
|
8 |
14,4 |
2,5 |
6,25 |
-2,26 |
-5,65 |
|
9 |
18,7 |
3,5 |
12,25 |
2,04 |
7,14 |
сумма |
10 |
20,7 |
4,5 |
20,25 |
4,04 |
18,18 |
55 |
166,6 |
0 |
82,5 |
0 |
26,6 |
|
среднее |
5,5 |
16,66 |
|
|
|
|
25 |
|
|
|
|
|
|
20 |
|
|
|
|
|
|
15 |
|
|
|
|
y = 0,3224x + 14,887 |
|
|
|
|
|
R2 = 0,0654 |
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
5 |
|
|
|
|
|
|
0 |
2 |
4 |
6 |
8 |
10 |
12 |
Рис. 6. Корреляционное поле и тренд
2. Оценка качества построенной модели
Для этого исследуем адекватность модели. Модель является адекватной, если математическое ожидание значений остатков близко или равно нулю, и если значения остаточного ряда случайны, независимы и подчинены нормальному закону распределения;
Проверка равенства нулю математического ожидания уровней ряда остатков
Для этого найдем значения ряда остатков и произведем суммирование (табл. 7).
Таблица 7
t |
Урожайность |
Yрег |
Е |
1 |
16,3 |
15,20909 |
1,090909 |
2 |
20,2 |
15,53152 |
4,668485 |
3 |
17,1 |
15,85394 |
1,246061 |
4 |
7,7 |
16,17636 |
-8,47636 |
5 |
15,3 |
16,49879 |
-1,19879 |
6 |
16,3 |
16,82121 |
-0,52121 |
7 |
19,9 |
17,14364 |
2,756364 |
8 |
14,4 |
17,46606 |
-3,06606 |
9 |
18,7 |
17,78848 |
0,911515 |
10 |
20,7 |
18,11091 |
2,589091 |

15
сумма |
55 |
166,6 |
|
0 |
n
В нашем случае t 0, поэтому гипотеза о равенстве математиче-
t 1
ского ожидания значений остаточного ряда нулю выполняется. Модель по данному свойству адекватна.
Проверка независимости (отсутствие автокорреляции)
Данное свойство проверяют с помощью критерия Дарбина-Уотсона. Для этого находится статистика Дарбина-Уотсона (d-статистика):
n
t t 1 2
d |
t 2 |
|
. |
(5) |
|
n |
|||
|
|
|
|
t2
t 1
Для проверки используют два пороговых значения dв и dн, зависящие т о л ь к о от числа наблюдений, числа регрессоров и уровня значимости.
Графически результат теста Дарбина-Уотсона можно изобразить следующим образом (рис. 7).
Н0 отвергается |
Зона |
Н0 принимается |
Зона |
Н0 отвергается |
(положительная |
неопре- |
(отсутствие авто- |
неопре- |
(отрицательная |
автокорреляция) |
делен- |
корреляции) |
делен- |
автокорреляция) |
|
ности |
|
ности |
|
|
|
|
|
|
0 dн dв 2 4 - dв 4 - dн 4
Рис. 7. Тест Дарбина-Уотсона
Расчетное значение d равно:
d 235,7383 = 1,9224 122,6275
Значение рассчитанного параметра d больше dв и меньше 4 dв, поэтому принимаем гипотезу об отсутствии автокорреляции по критерию Дарбина-Уотсона.
Также для проверки наличия автокорреляции можно воспользоваться первым коэффициентом автокорреляции:

16
n
t t 1
r 1 |
t 2 |
. |
(6) |
|
n |
||||
|
|
|
t2
t 1
Для принятия решения об отсутствии или наличие автокорреляции в исследуемом ряду расчетное значение r(1) сопоставляют с табличным (критическим) значением r для = 0,05. Если r(1) < r , то гипотеза об отсутствии автокорреляции в исследуемом ряду может быть принята, иначе – делают вывод о наличии автокорреляции в ряду.
Вычислим r(1) для нашего примера:
r(1) = 0,8116 = 0,00662. 122,6275
Рассчитанное значение меньше табличного. Это означает, что гипотеза об отсутствии автокорреляции в ряду урожайности может быть принята.
Модель по параметру независимости а д е к в а т н а .
Проверка случайности возникновения отдельных отклонений от тренда
Используем критерий, основанный на поворотных точках.
Значение случайной переменной считается поворотной точкой, если оно одновременно больше (меньше) соседних с ним элементов. Если остатки случайны, то поворотная точка приходится примерно на каждые 1,5 наблюдения. Если их больше, то возмущения быстро колеблются, и это не может быть объяснено только случайностью. Если же их меньше, то последовательные значения случайного компонента положительно коррелированны.
Критерий случайности отклонений от тренда при уровне вероятности 0,95 можно представить как
|
|
|
|
|
|
|
|
2 |
n 2 |
1,96 |
16n |
29 |
|
||
p |
|
|
|
, |
(7) |
||
3 |
90 |
|
|||||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
где р фактическое количество поворотных точек в случайном ряду; 1,96 квантиль нормального распределения для 5%-го уровня значимости.
Квадратные скобки означают, что от результата вычисления следует взять целую часть (не путать с процедурой округления!).
Если неравенство не соблюдается, то ряд остатков нельзя считать случайным (т.е. он содержит регулярную компоненту), стало быть, модель не является адекватной.

|
|
|
|
17 |
|
|
|
Построим график остатков (рис. 8). |
|
|
|
||||
6 |
Et |
|
|
|
|
|
|
4 |
|
|
4,67 |
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
2,76 |
|
2,59 |
|
1,09 |
1,25 |
|
|
|
|
|
0 |
|
|
|
0,91 |
t |
||
|
|
|
|
-0,52 |
|
||
|
0 |
2 |
4 |
6 |
10 |
||
-2 |
8 |
12 |
|||||
|
|
|
-1,20 |
|
-3,07 |
|
|
-4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-6 |
|
|
|
|
|
|
|
-8 |
|
|
|
-8,48 |
|
|
|
|
|
|
|
|
|
|
|
-10 |
|
|
|
|
|
|
|
|
|
|
Рис. 8. График остатков |
|
|
||
Количество поворотных точек равно 4.
|
|
|
|
|
|
2 |
n 2 1,96 |
16n |
29 |
||
Значение |
|
|
|
= [2,9687] = 2. |
|
3 |
90 |
|
|||
|
|
|
|
||
|
|
|
|
|
|
Неравенство выполняется 4 > 2. Следовательно, свойство случайности выполняется. Модель по данному параметру а д е к в а т н а .
Соответствие ряда остатков нормальному закону распределения
Данное соответствие можно проверить с помощью RS-критерия:
RS |
max min |
, |
(8) |
|
S
где max, min – соответственно максимальный и минимальный уровни ряда остатков; S среднеквадратическое отклонение ряда остатков.
Если расчетное значение RS попадает между табулированными границами с заданным уровнем вероятности, то гипотеза о нормальном распределении ряда остатков принимается. В этом случае допустимо строить доверительный интервал прогноза.
Среднеквадратическое отклонение ряда остатков S = 3,6912.
RS = (4,6684 ( 8,4764)) = 3,5611 3,6912
Расчетное значение попадает в интервал [2,67-3,69], следовательно, выполняется свойство нормального распределения. Модель по этому параметру а д е к в а т н а .

18
Если все пункты проверки дают положительный результат, то выбранная трендовая модель является адекватной реальному ряду экономической динамики, и, следовательно, ее можно использовать для построения прогнозных оценок. В противном случае модель надо улучшать.
3. Точечный и интервальный прогнозы на два шага вперед
Точечный прогноз – это прогноз, которым называется единственное значение прогнозируемого показателя. Это значение определяется подстановкой в полученное (рассчитанное) уравнение выбранной кривой роста величины времени t, соответствующей периоду упреждения: t = n + 1; t = n + 2 и т.д.
Точное совпадение фактических данных и прогностических точечных оценок, полученных путем экстраполяции кривых, характеризующих тенденцию, имеет малую вероятность. Возникновение соответствующих отклонений объясняется следующими причинами.
1.Выбранная для прогнозирования кривая не является единственно возможной для описания тенденции. Можно подобрать такую кривую, которая дает более точные результаты.
2.Прогноз осуществляется на основании ограниченного числа исходных данных. Кроме того, каждый исходный уровень обладает еще и случайной компонентой. Поэтому и кривая, по которой осуществляется экстраполяция, также будет содержать случайную компоненту.
3.Тенденция характеризует движение среднего уровня ряда динамики, поэтому отдельные наблюдения могут от него отклоняться. Если такие отклонения наблюдались в прошлом, то они будут наблюдаться и
вбудущем.
Интервальные прогнозы строятся на основе точечных прогнозов. Доверительным интервалом называется такой интервал, относительно которого можно с заранее выбранной вероятностью утверждать, что он содержит значение прогнозируемого показателя. Ширина интервала зависит от качества модели, т.е. степени ее близости к фактическим данным, числа наблюдений, горизонта прогнозирования и выбранного пользователем уровня вероятности.
При построении доверительного интервала прогноза рассчитывается величина U(k), которая для линейной модели имеет следующий вид
U(k) S ˆt |
1 |
1 |
|
n k t |
|
, |
(9) |
|
n |
||||||
Y |
|
|
|
|
|
||
|
|
n |
|
t t 2 |
|
|
|
|
|
|
|
t 1 |
|
|
|
где р – число факторных переменных; k – период прогнозирования; t табличное значение t-статистики Стьюдента при заданном уровне зна-

19
чимости и числе наблюдений (значение t можно получить с помощью
|
n |
|
|
|
t2 |
|
|
встроенной функции Excel СТЬЮДРАСПОБР); S ˆ |
t 1 |
|
|
|
|||
Y |
n p 1 |
|
|
|
|
||
стандартная ошибка (среднеквадратическое отклонение от модели). Для других моделей величина U(k) рассчитывается аналогичным об-
разом, но имеет более громоздкий вид. Как видно из формулы, величина U зависит прямо пропорционально от точности модели, коэффициента доверительной вероятности t , степени углубления в будущее на k шагов вперед, т.е. на момент t = n + k, и обратно пропорциональна объему наблюдений. Доверительный интервал прогноза будет иметь следующий вид:
Uy = yˆn k U(k) (10)
Если построенная модель адекватна, то с выбранной пользователем вероятностью можно утверждать, что при сохранении сложившихся закономерностей развития прогнозируемая величина попадает в интервал, образованный верхней и нижней границей.
После получения прогнозных оценок необходимо убедиться в их разумности и непротиворечивости оценкам, полученным иным способом.
Построим прогнозы на два шага вперед (k = 1 и k = 2):
точечный у11 = 14,887 + 0,322 11 18,39
у12 = 14,887 + 0,322 12 18,71
интервальный
Рассчитаем стандартную ошибку SYˆ = 3,915
Тогда значение U(k) для расчета доверительного интервала будет
равно: |
|
|
|
|
|
|
|
|
U(1) = 3,915 1,108 |
1 |
|
1 |
|
10 1 5,5 |
|
|
= 5,254; |
10 |
|
|||||||
|
|
82,5 |
|
|
|
|||
|
|
|
|
|
|
|
||
U(2) = 3,915 1,108 |
1 |
|
1 |
|
10 2 5,5 |
|
= 7,319. |
|
10 |
|
|||||||
|
|
82,5 |
|
|
|
|||
Данные расчета верхних и нижних границ доверительного интервала приведены в табл. 8.
|
|
|
|
Таблица 8 |
|
|
|
|
|
|
|
n + k |
U(k) |
Прогноз |
Верхняя |
Нижняя |
|
граница |
граница |
|
|||
|
|
|
|
||
10 + 1 |
5,254 |
18,39 |
23,644 |
13,136 |
|
10 + 2 |
7,319 |
18,71 |
26,029 |
11,391 |
|

20
4.График фактических данных, результатов расчета
ипрогнозирования.
Для построения графика прогнозирования воспользуемся инструмен-
том Excel Мастер диаграмм.
Для этого необходимо:
1.Выделить диапазоны ячеек значений t, урожайности и оценки урожайности.
2.Запустить Мастер диаграмм, в диалоговом окне мастера выбрать тип диаграммы Точечный, на котором значения соединены отрезками. Далее в мастере установить необходимые настройки и параметры. Желательно для исходных значений у задать параметр, который обозначает фактические значения урожайности.
3.В диалоговом окне Исходные данные на вкладке Ряд добавить ряды для значений точечного и интервального прогноза. Для этого выбрать кнопку Добавить, в поле Имя указать название ряда, в поле Значение Х диапазон прогноза (11 и 12), в поле Значение Y диапазон либо точного, либо интервального прогнозов. Пример окна (рис. 9).
Рис. 9. Рабочее окно исходных данных
В результате график прогноза выглядит следующим образом
(рис. 10).