

2021ВКР750107ИСАКОВ
.pdfна латинице, так и на кириллице. Следующий этап потребует указать свой вес в кг и рост в см. Введенные числа должны быть целыми. Email указывается пользователем в обязательном порядке, т.к. это единственная возможность восстановить потерянный доступ в личный кабинет. Для отправки писем почта пациента не используется, для этого предусмотрен аккаунт pochtadiacompanion@gmail.com. В письме, полученном врачом, будут указаны ФИО пользователя и прикреплен Excel файл. Следовательно, для корректной работы приложения необходимо также указать лечащего врача (из предложенного списка) и свои настоящие ФИО. Пароль при регистрации необходимо повторить два раза во избежание опечаток. Для формирования электронного дневника, пользователю необходимо регулярно, в течение установленного врачом промежутка времени (неделя, месяц, три месяца и т.д.), заполнять приемы пищи (завтрак, обед, ужин и перекусы), а также по желанию указывать физическую нагрузку (ходьба, зарядка, спорт, работа в огороде, уборка квартиры) и продолжительность сна. По результатам мониторинга врач назначает рекомендации и лечение на очном приеме. Для удобства анализа данных и учета неполных дней пользователю будет предоставлена возможность указывать в календаре полностью заполненные дни. При удалении записи, она не должна быть бесследно стерта, запись об удалении сохранится в формате: дата/время/прием пищи/завтрак или дата/время/физическая активность/зарядка. Такой подход повысит информативность результатов, особенно при работе с детьми. Помимо прочего, приложение реализует прогностическую модель, работа с которой поможет спрогнозировать повышение уровня сахара в крови в момент формирования планируемого к приему пищи списка блюд пользователем, но до его фактического потребления, см. рис 18.
41
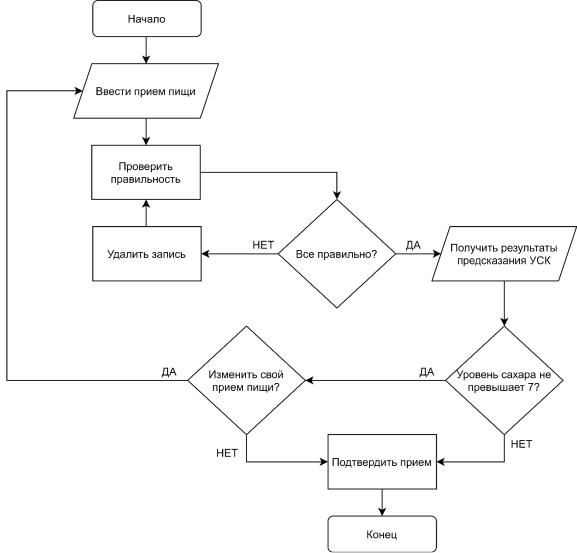
Рисунок 18 – Алгоритм ввода приема пищи пациентом Результат работы модели зависит от начального УСК и введенного
набора продуктов. Чтобы избежать ошибок, следует перепроверить список указанных блюд. В случае возникновения ошибки – удалить запись и еще раз указать УСК. Веб-приложение выдаст одно из двух уведомлений: «УСК в норме» или «УСК превысит норму». В обоих случаях система предложит записать результат. При возникновении сомнений в правильности выбранной диетической схемы следует обратиться к врачу, отложить или изменить прием пищи.
2.3 Разработка составных частей веб-приложения
2.3.1 Разработка базы данных
База данных представляет собой набор связанных между собой таблиц,
управляемых программным комплексом СУБД. На рисунке 19 представлена
42
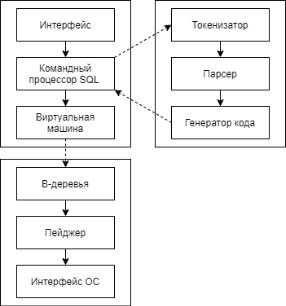
архитектура SQLite базы данных [37]. Она разделена на три разные части,
называемые внутренней частью (Backend), SQL компилятором и ядром (две последние можно назвать условно внешней частью).
Рисунок 19 – Архитектура SQLite
Токенизатор, парсер и генератор кода вместе образуют SQL компилятор,
генерирующий набор кодов операций, который запускается на виртуальной машине. Ядро и SQL компилятор задают порядок выполнения транзакций базы данных. Бэкенд содержит B-деревья, пейджер и интерфейс операционной системы (ОС) – виртуальную файловую систему, которая представляет собой общий программный интерфейс приложения для доступа к файлам в независимости от операционной системы. Этот API включает в себя функции для открытия/закрытия, чтения и записи с диска компьютера. Пейджер отвечает за работу со страницами. Когда пользователю необходимо прочитать данные из файла, СУБД запрашивает их как страницу (элементарную единицу для передачи). B-деревья это структура данных, которая используется для хранения информации в виде дерева, в самой простой форме – это двоичное дерево. В SQLite B-деревья хранят индексы, чтобы повысить производительность.
Таким образом движок в SQLite (SQL компилятор и виртуальная машина) представляет собой составную часть программы, не являясь отдельно
43
взятым работающим процессом, с которым взаимодействует программа. При этом в качестве протокола обмена используются вызовы функций (API)
библиотеки SQLite. Пейджер и B-деревья важны для нашего понимания, так как на их работе базируется основной инструмент манипуляции с данными в базе – курсор. С его помощью мы добавляем, удаляем и ищем записи по идентификатору страницы в таблице и показателю смещения (если индексирование недоступно, то проводится линейный поиск). А интерфейс ОС обеспечивает доступ к файловой системе, т.к. SQLite хранит всю базу данных (включая определения, таблицы, индексы и данные) в единственном стандартном файле на компьютере, на котором и исполняется программа.
Подходя к вопросу разработки структуры таблиц базы данных, прежде всего будем исходить из ограничений, накладываемых выбранным нами типом баз данных. Как уже упоминалось ранее в первой главе, SQLite
позволяет множеству пользователей читать записи внутри базы одновременно, при этом накладывая ограничения на число одновременных сеансов записи. Но так как приложение не является высоконагруженным
(ожидается менее 100 000 запросов в день и не превышает лимита хранения в
140 терабайт информации), было решено использовать базу SQLite [38]. Более того, SQLite базы данных могут работать хорошо даже при очень небольшом объеме оперативной памяти, что снижает затраты на сервер. Вопрос ограничений на единовременную запись можно решить повторением запроса на запись в течение ограниченного периода времени или же созданием вспомогательной таблицы, куда бы уходили записи, не записанные по истечении времени. Сравнительно недавно появилась еще одна возможность
– SQLite: Write Ahead Log. Если включить именно этот режим лога, то несколько подключений смогут одновременно модифицировать БД, но в этом режиме БД занимает несколько файлов [39].
SQLite поддерживает динамическое типизирование данных. Среди поддерживаемых значений: INT, REAL, TEXT и BLOB. Есть возможность указать пропущенную запись через специальное значение NULL.
44
Преимущественно в работе предполагается использование INT, REAL и TEXT
данных. Размеры TEXT данных не ограничены ничем, кроме максимальной длины SQLITE_MAX_LENGTH = 109, хотя большинство ограничений носят рекомендательный характер и могут быть упразднены по желанию.
Отличительной особенностью таблиц SQLite является поддержка разных форматов столбца и записей внутри него. Например, стандартным форматом данных столбца является INT, но записано число дробное. В таком случае запись будет либо приведена к заданному типу, либо сохранена в ячейке «как есть». Более того, если тип хранимого значения не соответствует типу запрашиваемого, он, по возможности, безопасно преобразуется [40]. Но гораздо удобнее было бы хранить уникальные ключи user_id в формате INT, а
все остальное в формате TEXT. Подобным образом можно избежать непредсказуемых ошибок динамической типизации. Более того, как уже упоминалось ранее, SQLite самостоятельно переведет TEXT в REAL если понадобится, например, посчитать средствами СУБД среднее avg(). Яркий пример тому – присоединенная база данных приложения DiaCompanion [21].
Она содержит значения в форматах REAL и INT, и при экспорте нередко возникает проблема несоответствия NULL значения в SQLite и NoneType в Python. Разделительные знаки не менее часто доставляют проблемы. В
некоторых записях стоит точка, в других запятая – Python же считает дробными числами только те, что отделяют дробную часть точкой.
Аналогичная проблема может возникнуть при сохранении введенного пользователем показателя уровня сахара в крови.
Разрабатываемая база данных должна хранить как обширную коллекцию записей нутриентов по категориям съедобных продуктов и блюд,
так и пользовательскую информацию. Предварительная структура базы данных приведена в таблице 1.
45

Таблица 1 – Предварительная структура базы данных
Название |
Заполняемые поля |
Назначение |
||
таблицы |
||||
|
|
|
||
|
user_id, date, time, min, type |
Здесь хранится информация о |
||
activity |
|
физической |
активности |
|
|
|
пользователя |
|
|
|
|
|
||
meal_diary |
user_id, week_day, date, time, |
Дневник приемов пищи |
||
class, food_id |
|
|
||
|
|
|
||
full_days |
user_id, date |
Список полных дней |
||
sleep |
user_id, date, time, hour |
График сна |
|
|
user |
user_id, username, surname, |
Личная |
информация, |
|
email, password, BMI |
сохраняемая при регистрации |
|||
|
||||
|
food_id, name, category, |
Уникальный идентификатор, |
||
|
carbo, prot, fat, ec, gi, water, |
наименование, |
категория |
|
|
nzhk, hol, pv, zola, na, k, ca, |
(молочные |
продукты, |
|
food |
mg, p, fe, a, b1, b2, rr, c, re, kar, |
колбасы, фрукты, овощи и |
||
|
mds, kr, te, ok, ne |
другие) и набор нутриентов |
||
|
|
по каждому |
доступному |
|
|
|
продукту или блюду |
||
Ключевое поле для всех таблиц – id, в случае с пользовательскими записями, это будет user_id, а для продуктов питания, food_id. Так как первичный ключ состоит из единственного атрибута, он является простым.
Иными словами, вся информация о приемах пищи, физической активности и сне напрямую связана с регистрационными данными пользователя через его id. А вся информация о потребленных микроэлементах в таблице meal_diary
связана через food_id с наименованиями блюд в таблице food. Помимо уникальных идентификаторов все блюда и продукты имеют поля name –
название и category – категорию. Для удобства все доступные категории можно свести в отдельную таблицу foodGroups с полями _id – в данном случае обычный порядковый номер и category, например:
•Алкогольные напитки;
•Блюда из картофеля, овощей и грибов;
•Выпечка.
И т.д. вниз по алфавиту.
46
Для возможности потенциального расширения базы данных микроэлементов путем присоединения к ней некоторой таблицы №2 необходимо составить отдельный Excel файл вида: «Наименование / Наличие в нашей таблице / Наличие параметра в присоединяемой таблице / Единицы измерения табл. №1 / Единицы измерения табл. №2 / Аббревиатура». Таким образом мы решаем две проблемы: во-первых, использование разных единиц измерения, например, мкг или мг, мг или мг% и, во-вторых, контролируем отсутствие в присоединяемой базе данных некоторых особенно важных наименований, например, крахмала.
2.3.2 Разработка модели предсказания сахара в крови
Постпрандиальный гликемический ответ является важной характеристикой эффективности контроля глюкозы в крови и метаболизма глюкозы у пациентов со всеми типами диабета. Модели машинного обучения обеспечивают эффективное решение для прогнозирования уровня глюкозы в крови после приема пищи. Перед нами стоит задача обосновать выбор конкретного метода и внедрить его математический аппарат в систему удаленного мониторинга.
Встатистике хорошо известно интуитивное соображение, согласно которому усреднение результатов наблюдений может дать более устойчивую
инадежную оценку, поскольку ослабляется влияние случайных флуктуаций в отдельном измерении. На аналогичной идее было основано развитие алгоритмов комбинирования моделей, в результате чего построение их ансамблей оказалось одним из самых мощных методов машинного обучения, нередко превосходящим по качеству предсказаний другие методы [41].
Внашей работе будут рассматриваться методы улучшения модели деревьев регрессии, но, так как зачастую возникает путаница между определениями моделей деревьев принятия решений и деревьев регрессии,
приведем короткое объяснение. Разница между ними заключается в том, что при классификации в листьях деревьев решений стоят результирующие
47
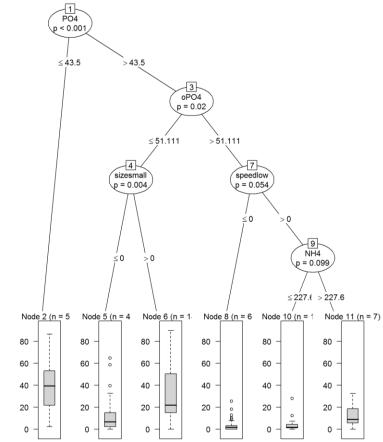
классы, при регрессии же стоит какое-то значение целевой функции см.
рисунок 20 [41]. Соответственно здесь в каждом узле мы видим среднее значение и стандартное отклонение значений целевой функции наблюдений,
попавших в узел Node. Общее число наблюдений, попавших в узел равно N.
Рисунок 20 – Дерево регрессии Деревья решений и регрессии являются одними из наиболее популярных
моделей, что обусловлено следующими причинами:
•Легко интерпретируемая модель;
•Может работать с переменными любого типа;
•Нет необходимости в явном виде задавать форму взаимосвязи между откликом и предикторами;
•Автоматически выполняют отбор информативных предикторов и учитывают взаимодействия между ними;
•Можно эффективно применять для работы с пропущенными данными;
•Хорошо применимы как количественным, так и к качественным зависимым переменным.
48
Однако, рассмотренный класс моделей имеет ряд критических
недостатков:
•Сложный поиск оптимального дерева;
•Невысокая точность предсказаний, возможно переобучение;
•Чувствительность к шумам во входных данных.
Происходит это потому как деревья предполагают, что признаки взаимно независимы, т.е. используют «наивный подход» и плохо работают при наличии корреляции.
Как уже раньше упоминалось в работе, мы используем систему градиентного бустинга (библиотека xgboost) для повышения качества модели регрессионных деревьев, но это не единственный популярный вариант.
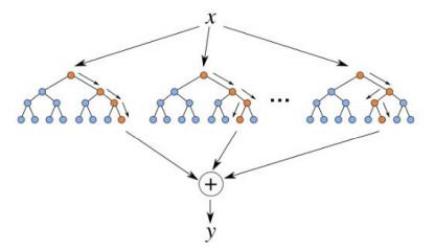
Случайный лес, в свою очередь, является алгоритмом машинного обучения, использующим ансамбли деревьев решений, каждое из которых само по себе дает очень невысокую точность, но за счет их большого количества результат получается лучше. Заключение принимается по итогу
«голосования» деревьев, рис. 21.
Рисунок 21 – Ансамбли случайного леса Метод случайного леса по сути является улучшенным бэггингом
деревьев решений. Бэггинг – это процедура усреднения результатов множества моделей, построенных на основе сгенерированных из генеральной совокупности обучающих выборок. Главное его преимущество в том, что он убирает корреляцию между деревьями. В обоих случаях мы строим несколько
49
сотен деревьев по обучающим бутстреп (процедура генерации повторных случайных выборок из исходного набора данных) выборкам, однако, на каждой из итераций построения дерева случайным образом выбирается лишь небольшая группа предикторов из всех подлежащих рассмотрению признаков.
Бустинг (Gradient Boosting Machine) заключается в итеративном процессе последовательного построения частных моделей. Каждая новая модель обучается с использованием информации об ошибках, сделанных на предыдущем этапе, а результирующая функция представляет собой линейную комбинацию всего ансамбля моделей с учетом минимизации любой штрафной функции. Т.е. каждая последующая модель строится таким образом, чтобы придавать больший вес ранее некорректно предсказанным наблюдениям [41].
Каждое дерево строится по набору данных X,r, который на каждом шаге модифицируется определенным образом. На первой итерации по значениям исходных предикторов строится дерево f1(x) и находится вектор остатков r1.
На последующем этапе новое регрессионное дерево f2(x) стоится уже не по обучающим данным X, а по остаткам r1 предыдущей модели. Линейная комбинация прогноза по построенным деревьям дает нам новые остатки и этот процесс повторяется B раз (при чрезмерно большом B бустинг может приводить к переобучению). Благодаря построению неглубоких деревьев по остаткам, прогноз отклика медленно улучшается в областях, где одиночное дерево работает не очень хорошо. Такие деревья могут быть довольно небольшими, лишь с несколькими конечными узлами. Параметр сжатия ,
который корректирует величину вклада каждого дополнительного дерева,
регулирует скорость этого процесса, позволяя создавать комбинации деревьев более сложной формы для анализа остатков [41]. Итоговая модель бустинга представляет собой ансамбль, выражающийся формулой:
̂( ) = ∑ ( )
1
50