

параллельные алгоритмы лаб_2
.docxМИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра Вычислительной техники
Отчет
по лабораторной работе №2
по дисциплине «Параллельные алгоритмы и системы»
Тема: Алгоритм поиска кратчайших путей Флойда
Студентка гр. 0321, ФКТИ |
|
|
Преподаватель |
|
|
Санкт-Петербург
2023
Цель работы
Изучить основные методы оптимизации кода.
Задача
Алгоритм поиска кратчайших путей Флойда
Подготовка
Все замеры производились на следующей системе:
Процессор: Intel Core i3-10105f, 4 ядра, 8 потоков;
ОЗУ: DDR4 16Gb 2666, 2 канальная;
Компилятор: GCC
Изначальный вариант программы без оптимизации
Исходный код программы lab1_1.c представлен в приложении.
Метрики из приложения Intel VTune:


![]()
![]()
Однопоточное приложение показывает не самые лучшие результаты по
быстродействию. Посмотрим, что даст распараллеливание вычислений.
Распараллеливание вычислений с помощью OpenMP
Для распараллеливания вычислений воспользуемся библиотекой OpenMP,
которая значительно упрощает организацию и логику работы потоков, что позволяет уменьшить время написания кода и упростить логику программы.
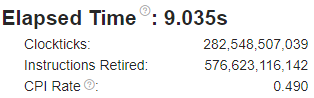
Ниже приведены метрики для 8 потоков.

![]()

Время выполнения программы уменьшилось в 3,7 раза. Уменьшилось количество обращений к основной памяти. Количество ошибок предсказания переходов стало равным 0%. Уменьшился процент кэш миссов. Немного увеличилось значение CPI.
График

Из результатов измерений видно, что использование многопоточности позволило нам сократить время вычисления нашей задачи. Однако увеличение числа потоков не всегда даёт прирост в скорости выполнения программы, т.к. при увлечении потоков (> 8) время увеличивается, из-за большого числа переключений контекста. Оптимальное число потоков оказалось равным 8.
Время выполнения исходной программы, скомпилированной с ключами O0, O1, O2, O3 в миллисекундах.
O0 |
O1 |
O2 |
O3 |
34618 |
8942 |
7648 |
7464 |
При оптимизации ключами O1, O2, O3 время выполнения исходной программы существенно уменьшилось, но исходя из полученных метрик количество обращений к основной памяти значительно увеличилось, так же увеличилось количество кэш-миссов.
Метрики для исходной программы скомпилированной с ключом O3

Вывод: оптимизация кода программы “Алгоритм поиска кратчайших путей Флойда”, привела к улучшения качества итогового ПО и приросту производительности. Итоговое время работы программы после оптимизации уменьшилось в 3,5 раза. Так же хочется отметить, что несмотря на то что исходная программа, скомпилированная с ключами O1, O2, O3 даёт лучшие результаты по времени, по другим показателям (количеству обращений к основной памяти, кэш-миссам) она не так эффективна, как программа, использующая многопоточность.
Приложения
Листинг lab 1_1.с

Листинг lab 1_2.с
