

Министерство науки и высшего образования Российской Федерации
Федеральное государственное бюджетное образовательное учреждение
высшего образования
«ТОМСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ СИСТЕМ
УПРАВЛЕНИЯ И РАДИОЭЛЕКТРОНИКИ» (ТУСУР)
Кафедра безопасности информационных систем (БИС)
автоматизированный анализ текста на естественном языке
Отчет по лабораторной работе №1
по дисциплине «Языки программирования»
Студент гр.739-1
_______ М. Д. Климанов
24.09.2020
Принял
Младший научный сотрудник
______ ______ В. А. Полюга
24.09.2020
Томск 2020
Содержание
Содержание 2
1 Введение 3
2 Ход работы 4
2.1 Теоретические сведения 4
2.2 Задание 4
3 Заключение 7
Приложение А 9
Приложение Б 10
1 Введение
Цель работы: закрепить знания, полученные при изучении учебных курсов по программированию. Познакомиться с алгоритмами обработки текста.
Задание: разработать программу, которая будет определять и выводить концы предложений в русском тексте разных стилей: научный, официально-деловой, публицистический, художественный и разговорный-обиходный на языке Python.
2 Ход работы
2.1 Теоретические сведения
Синтаксический анализ — это процесс сопоставления линейной последовательности лексем (слов, токенов) языка с его формальной грамматикой.
Лексический анализ — процесс аналитического разбора входной последовательности символов с целью получения на выходе последовательности символов, называемых «токенами» (подобно группировке букв в слова). Группа символов входной последовательности, идентифицируемая на выходе процесса как токен, называется лексемой. В процессе лексического анализа производится распознавание и выделение лексем из входной последовательности символов.
Семантический анализ — этап в последовательности действий алгоритма автоматического понимания текстов, заключающийся в выделении семантических отношений, формировании семантического представления текстов.
2.2 Задание
Условие: разработать программу, которая будет определять и выводить концы предложений в русском тексте разных стилей: научный, официально-деловой, публицистический и художественный на языке Python.
Для начала составим блок-схему, изображенную на рисунке 2.1
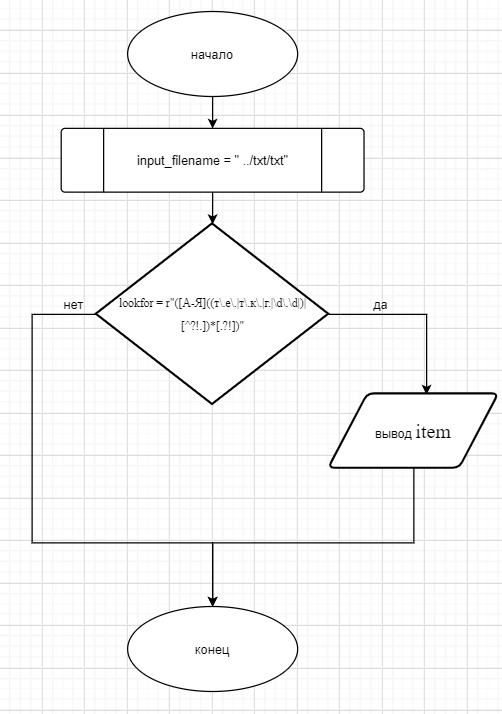
Рисунок 2. 1 – Блок-схема
На языке Python данный алгоритм может выглядеть вот так:
Считывание текста из файла:
import re
input_filename = "../txt.txt"
Регулярное выражение и его вывод:
lookfor = r" ([\w](((т\.к\.)| (т\.е\.)|(\w\))| (\W\")|([А-Я]\.[А-Я]\.) |(г\.)|(\s\() |(т\.\w)|(\d\.\s*)) |[^?!.)(])*[.?!)(])"
results = re.findall(lookfor, mytext)
for item in results:
print(item[0])
Полный листинг программы представлен в приложении А.
Данная программа определяет конец предложения и выводит все предложения с новой строки. Учитывая разнообразие русского языка, учесть все моменты, когда действительно заканчивается предложение – невозможно. Программа работает в тех случаях, когда текст относительно простой: перед точками/вопросительными/восклицательными знаками нет пробелов, между дробной и целой частью числа нет пробела, предложения не начинаются с фамилии, имени и отчества, то пишутся в конце предложения вместе, между инициалами ставится пробел.
Пример правильной работы программы для текста, указанного в приложении Б, представлен на рисунке 2.2.

Рисунок 2.2 – Результат работы программы
3 Заключение
В ходе выполнения лабораторной работы закреплены знания, полученные при изучении учебных курcов по программированию, получены навыки составления алгоритмов обработки текста.
Была разработана программа, которая будет определять и выводить концы предложений в русском тексте разных стилей на языке C#.
Отчет был написан согласно ГОСТ ОС ТУСУР.
Список использованных источников
1 Романов, А.С. Методические указания. Автоматизированный анализ текста на естественном языке, 2014. – 9 с.