

ПР7_Отчёт_ЗаболотниковМЕ_9373
.docx
МИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра информационных систем
отчет
по практической работе №7
по дисциплине «Теория информации, данные, знания»
Тема: Словарное кодирование. Метод LZW
Студент(ка) гр. 9373 |
|
Заболотников М.Е. |
Преподаватель |
|
Писарев И. А. |
Санкт-Петербург
2020
Цель работы
Сформулировать ответы на вопросы с указанием источников информации.
Вопросы по теме 7:
В чем состоит особенность методов словарного кодирования?
Дать сравнительную характеристику наиболее известных методов словарного кодирования (LZ77, LZ78, LZW).
Описать метод Лемпеля-Зива-Велча (LZW).
Закодировать сообщение bbbbbbbbbb методом LZW. Опишите выполненные шаги алгоритма кодирования. Какое значение степени сжатия получено? Привести описание последовательности выполненных действий по кодированию с комментариями выполняемых шагов алгоритма.
Закодировать сообщение DADAADAAA методом LZW. Опишите выполненные шаги алгоритма кодирования. Какое значение степени сжатия получено? Привести описание последовательности выполненных действий.
Выполнение работы
Методы, основанные на словарном подходе, в отличие от статистических методов, не рассматривают статистические модели и не используют коды переменной длины. Вместо этого они выбирают некоторые последовательности символов, сохраняют их в словаре, а все последовательности кодируются в виде меток, при этом используется словарь.
Плюсы:
Не требует вычисления вероятностей встречаемости символов или кодов.
Для декомпрессии не надо сохранять таблицу строк в файл для распаковки. Алгоритм построен таким образом, что мы в состоянии восстановить таблицу строк, пользуясь только потоком кодов.
Данный тип компрессии не вносит искажений в исходный графический файл, и подходит для сжатия растровых данных любого типа.
Минусы:
Алгоритм не проводит анализ входных данных, поэтому не оптимален.
Процесс сжатия выглядит следующим образом. Последовательно считываются символы входного потока и происходит проверка, существует ли в созданной таблице строк такая строка. Если такая строка существует, считывается следующий символ, а если строка не существует, в поток заносится код для предыдущей найденной строки, строка заносится в таблицу, а поиск начинается снова.
Пусть (0: b), тогда:
-
Текущая строка
Текущий символ
Следующий символ
Вывод
Словарь
Код
Биты
b
b
b
0
000
–
bb
b
b
–
–
1: bb
b
b
b
–
–
–
bb
b
b
1
001
–
bbb
b
b
–
–
2: bbb
b
b
b
–
–
–
bb
b
b
–
–
–
bbb
b
b
2
010
–
bbbb
b
b
3
011
3: bbbb
Степень сжатия:
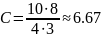
Ответ: код сообщения:
000001010011;
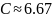 .
.
Пусть (0: A; 1: D), тогда:
-
Текущая строка
Текущий символ
Следующий символ
Вывод
Словарь
Код
Биты
D
D
A
1
001
–
DA
A
D
–
–
2: DA
A
A
D
0
000
–
AD
D
A
–
–
3: AD
D
D
A
–
–
–
DA
A
A
2
010
–
DAA
A
D
–
–
4: DAA
A
A
D
–
–
–
AD
D
A
3
011
–
ADA
A
A
–
–
5: ADA
A
A
A
0
000
–
AA
A
A
–
–
6: AA
A
A
A
6
110
–
Степень сжатия:
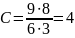
Ответ: код сообщения:
001000010011000110;
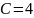 .
.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
https://yadi.sk/i/wthU8ISpHESyQQ
https://yadi.sk/i/djuccSCVCeQpxQ